Библиотека глубокого обучения Tensorflow
- пятница, 14 апреля 2017 г. в 03:14:42
 Здравствуй, Хабр! Цикл статей по инструментам для обучения нейронных сетей продолжается обзором популярного фреймворка Tensorflow.
Здравствуй, Хабр! Цикл статей по инструментам для обучения нейронных сетей продолжается обзором популярного фреймворка Tensorflow.
Tensorflow (далее — TF) — довольно молодой фреймворк для глубокого машинного обучения, разрабатываемый в Google Brain. Долгое время фреймворк разрабатывался в закрытом режиме под названием DistBelief, но после глобального рефакторинга 9 ноября 2015 года был выпущен в open source. За год с небольшим TF дорос до версии 1.0, обрел интеграцию с keras, стал значительно быстрее и получил поддержку мобильных платформ. В последнее время фреймворк развивается еще и в сторону классических методов, и в некоторых частях интерфейса уже чем-то напоминает scikit-learn. До текущей версии интерфейс менялся активно и часто, но разработчики пообещали заморозить изменения в API. Мы будем рассматривать только Python API, хотя это не единственный вариант — также существуют интерфейсы для C++ и мобильных платформ.
TF устанавливается стандартно через python pip. Есть нюанс: существуют отдельные алгоритмы установки для работы на CPU и на видеокартах.
В случае с CPU всё просто: нужно поставить из pip пакет под названием tensorflow.
Во втором случае нужно:
Впрочем, документация утверждает, что поддерживаются и более ранние версии CUDA Toolkit и cuDNN, но рекомендует устанавливать версии, указанные выше.
Разработчики рекомендуют устанавливать TF в отдельную среду с virtualenv, чтобы избежать возможные проблемы с версионированием и зависимостями.
Еще один вариант установки — Docker. По умолчанию из контейнера будет работать только CPU-версия, но если использовать специальный nvidia docker, то можно использовать и GPU.
Сам я не пробовал, но говорят, что TF работает даже с Windows. Установка проводится через тот же pip и, говорят, работает без проблем.
Я пропускаю процесс сборки из исходников, однако и такой вариант может иметь смысл. Дело в том, что пакет из репозитория собирается без поддержки SSE и прочих плюшек. В последних версиях TF проверяет наличие таких плюшек и сообщает, что из исходников он будет работать быстрее.
Подробно процесс установки описан тут.
Документации и примеров очень много.
Лучше всего ориентироваться на официальную документацию — из-за быстрого развития и частой смены api, в интернете очень много туториалов и скриптов, которые ориентированы на старые версии (ну как старые… полугодовой давности) со старым API, они не будут работать с последними версиями фреймворка.
С помощью «Hello, world» убедимся, что всё установилось правильно:
import tensorflow as tf # подключаем TF
hello = tf.constant('Hello, TensorFlow!') # создаем объект из TF
sess = tf.InteractiveSession() # создаем сессию
print(sess.run(hello)) #сессия "выполняет" объект
>>> b'Hello, TensorFlow!'Первой же строчкой подключаем TF. Уже сложилось правило вводить для фреймворка соответствующее сокращение. Этот же кусочек кода встречается в документации и позволяет удостовериться в том, что всё установилось правильно.
Работа c TF строится вокруг построения и выполнения графа вычислений. Граф вычислений — это конструкция, которая описывает то, каким образом будут проводиться вычисления. В классическом императивном программировании мы пишем код, который выполняется построчно. В TF привычный императивный подход к программированию необходим только для каких-то вспомогательных целей. Основа TF — это создание структуры, задающей порядок вычислений. Программы естественным образом структурируются на две части — составление графа вычислений и выполнение вычислений в созданных структурах.
Граф вычислений в TF по смыслу не отличается от такового в Theano. В предыдущей статье цикла дано отличное описание этой сущности.
В TF граф состоит из плейсхолдеров, переменных и операций. Из этих элементов можно собрать граф, в котором будут вычисляться тензоры. Тензоры — многомерные массивы, они служат «топливом» для графа. Тензором может быть как отдельное число, вектор признаков из решаемой задачи или изображение, так и целый батч описаний объектов или массив из изображений. Вместо одного объекта мы можем передать в граф массив объектов и для него будет вычислен массив ответов. Работа TF с тензорами похожа на то, как обрабатывает массивы numpy, в функциях которого можно указать ось массива, относительно которой будет выполняться вычисление.
Вычислительные графы выполняются в сессиях. Объект сессии (tf.Session) скрывает в себе контекст выполнения графа — необходимые ресурсы, вспомогательные классы, адресные пространства.
Существует два типа сессий — обычные, которые реализованы в tf.Session и интерактивные (tf.InteractiveSession). Разница между ними в том, что интерактивная сессия больше подходит для выполнения в консоли и сразу определяет себя как сессия по умолчанию. Основной эффект — объект сессии не нужно передавать в функции вычисления как параметр. В примерах далее я буду считать, что в данный момент работает интерактивная сессия, которую мы объявили в первом примере, и когда понадобится обращение к сессии, буду обращаться к объекту sess.
Далее в посте будут появляться стандартные для TF картинки с изображениями графов, сгенерированные встроенной утилитой под названием Tensorboard. Обозначения там вот такие:
| Переменная | Операция | Вспомогательный результат |
|---|---|---|
| Узел графа обычно содержит данные. | Делает что-то с переменными. Сюда же относятся плейсхолдеры, которые делают подстановку значений в граф. | Всякое кэширование и побочные вычисления типа градиентов, обычно так обозначают ссылку на отдельную часть графа. |
 |
 |
 |
Создадим, к примеру, тензор, заполненный нулями.
zeros_tensor = tf.zeros([3,3])Вообще, API в TF будет во многом напоминать numpy и tf.zeros() — далеко не единственная функция, имеющая прямой аналог в numpy. Чтобы увидеть значение тензора, его нужно выполнить. Подробнее о выполнении графа чуть ниже, пока что обойдемся тем, что выведем значение тензора и сам тензор.
print(zeros_tensor.eval())
print(zeros_tensor)
>>> [[ 0. 0. 0.]
[ 0. 0. 0.]
[ 0. 0. 0.]]
>>> Tensor("zeros_1:0", shape=(3, 3), dtype=float32)Различие между строчками состоит в том, что в первой строке происходит вычисление тензора, а во второй строке мы просто печатаем представление объекта.
Описание тензора показывает нам несколько важных вещей:
Над тензорами можно совершать разнообразные операции:
a = tf.truncated_normal([2,2])
b = tf.fill([2,2], 0.5)
print(sess.run(a+b))
print(sess.run(a-b))
print(sess.run(a*b))
print(sess.run(tf.matmul(a,b)))
>>> [[-1.12130964 -1.02217746]
[ 0.85684788 0.5425666 ]]
>>> [[ 0.35249496 0.96118248]
[-1.55395389 -1.18111515]]
>>> [[-0.06559008 -0.11100233]
[ 0.51474923 -0.27813852]]
>>> [[-0.16202734 -0.16202734]
[-0.8864761 -0.8864761 ]]В примере выше мы используем конструкцию sess.run — это метод исполнения операций графа в сессии. В первой строчке я создал тензор из усеченного нормального распределения. Для него используется стандартная генерация нормального распределения, но из него исключается всё, что выпадает за пределы двух стандартных отклонений. Помимо этого генератора есть равномерное, простое нормальное, гамма и еще несколько других распределений. Очень характерная для TF штука — уже реализовано большинство популярных вариантов выполнения операции и, возможно, перед изобретением велосипеда стоит взглянуть на документацию. Второй тензор — это заполненный значением 0.5 многомерный массив размера 2х2 и это что-то похожее на numpy и его функции создания многомерных массивов.
Создадим теперь переменную на основе тензора:
v = tf.Variable(zeros_tensor)Переменная участвует в вычислениях в качестве узла вычислительного графа, сохраняет состояние, и ей нужна какая-нибудь инициализация. Так, если в следующем примере обойтись без первой строчки, то TF выкинет исключение.
sess.run(v.initializer)
v.eval()
>>> array([[ 0., 0., 0.],
[ 0., 0., 0.],
[ 0., 0., 0.]], dtype=float32)Операции над переменными создают вычислительный граф, который можно потом выполнить. Еще есть плейсхолдеры — объекты, которые параметризуют граф и отмечают места для подстановки внешних значений. Как написано в официальной документации, плейсхолдер — это обещание подставить значение потом. Создадим плейсхолдер и назначаем ему тип данных и размер:
x = tf.placeholder(tf.float32, shape=(4, 4))Еще такой пример использования. Здесь два плейсхолдера служат входными узлами для сумматора:
a = tf.placeholder("float")
b = tf.placeholder("float")
y = tf.multiply(a, b)
print(sess.run(y, feed_dict={a:100,b:500}))
>>> 50000.0В качестве примера создадим и вычислим несколько выражений.
x = tf.placeholder(tf.float32)
f = 1 + 2* x + tf.pow(x,2)
sess.run(f, feed_dict={x:10})
>>> 121.0И граф вычисления:
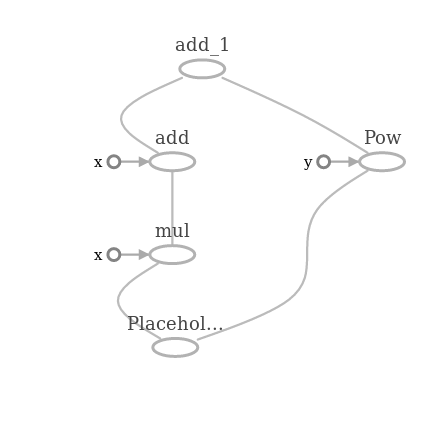
x и y, указывающие на операции в этой схеме — это дополнительные параметры, вместо которых могли бы быть ребра графа, но мы подставили в f скалярные значения 1 и 2 и это просто обозначение в графе для чисел. В этом примере мы создаем плейсхолдер и на его основе — граф выражения , а после этого выполняем вычисления графа в контексте текущей сессии. Я не указал форму в параметрах плейсхолдера и это значит, что можно подавать на вход тензоры любых размеров. Единственное, что необходимо указать — это тип тензора. Параметры при вычислении внутрь сессии передаются через feed_dict — словарь со всем, что необходимо для вычислений.
Попробуем собрать что-нибудь более практически значимое.
Вот, например, сигмоида:
x = tf.placeholder(dtype=tf.float32)
sigma = 1 / (1 + tf.exp(-x))
sigma.eval(feed_dict={x: np.linspace(-5,5) })И вот такой граф для неё.
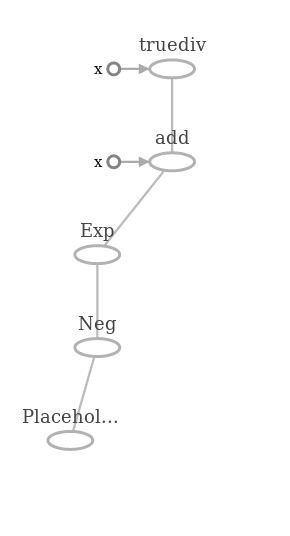
В фрагменте с запуском вычисления функции есть один момент, который отличает этот пример от предыдущих. Дело в том, что в плейсхолдер вместо одного скалярного значения мы передаем целый массив. TF обрабатывает все значения массива вместе, в рамках одного тензора (помним, что массив == тензор). Точно таким же образом мы можем передавать в граф объекты целыми батчами и поставлять нейронной сети картинки целиком.
В целом работа с тензорами напоминает работу с массивами в numpy. Однако, есть некоторые отличия. Когда мы хотим понизить размерность, каким-либо образом объединив значения в тензоре по определенному измерению, мы пользуемся теми функциями, которые начинаются с reduce_.
Если сравнить c API Theano — в TF нет деления на векторы и матрицы, но вместо этого приходится следить за размерностями тензоров в графе и есть механизм вывода формы тензора, который позволяет получить размерности еще до runtime.
Разберем для начала уже не раз упоминавшуюся здесь классическую линейную регрессию, с детальным описанием которой можно ознакомиться тут, однако для обучения будем использовать метод градиентного спуска.
Куда же без этой картинки
Начну с линейной регрессии, а потом добавлю полиномиальные признаки.
Данные будут синтетические — синус с нормальным шумом:
x = np.linspace(0,10, 1000)
y = np.sin(x) + np.random.normal(size=len(x))Выглядеть они будут примерно так:
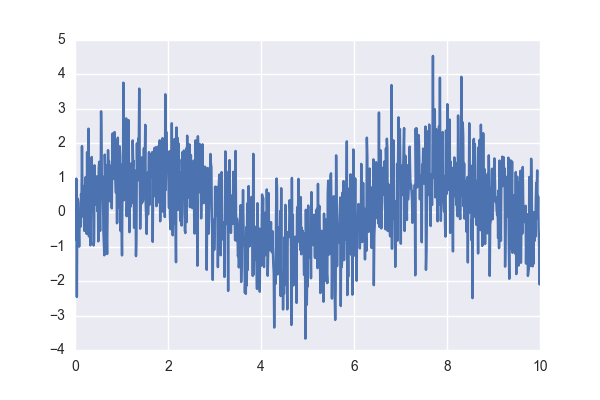
Я еще разобью выборку на обучающую и контрольную в пропорции 70/30, но этот и некоторые другие рутинные моменты оставлю в полном исходнике, ссылка на который будет чуть ниже.
Сначала построим простую линейную регрессию.
x_ = tf.placeholder(name="input", shape=[None, 1], dtype=tf.float32)
y_ = tf.placeholder(name= "output", shape=[None, 1], dtype=tf.float32)
model_output = tf.Variable(tf.random_normal([1]), name='bias') + tf.Variable(tf.random_normal([1]), name='k') * x_Тут я создаю два плейсхолдера для признака и ответа и формулу вида .
Нюанс — в плейсхолдере параметр формы (shape) содержит None. Размерность плейсхолдера означает, что плейсходер потребляет двумерные тензоры, но по одной из осей размер тензора не определен и может быть любым. Это сделано для того, чтобы пользователь мог передавать значения в граф сразу целыми батчами. Такие специфические размерности называют динамическими, TF рассчитывает действительную размерность связанных элементов во время выполнения графа.
Плейсхолдер для признака используется в формуле, а вот плейсхолдер для ответа я подставлю в функцию потерь :
loss = tf.reduce_mean(tf.pow(y_ - model_output, 2)) # функция потерьВ TF реализован десяток методов оптимизации. Мы будем использовать классический градиентный спуск, указав ему в параметрах скорость обучения.
Метод minimize создаст нам операцию, вычисление которой будет минимизировать функцию потерь.
gd = tf.train.GradientDescentOptimizer(0.001) #оптимизатор
train_step = gd.minimize(loss)Инициализация переменных — она необходима для дальнейших вычислений:
sess.run(tf.global_variables_initializer())Всё, наконец-то можно обучать. Я запущу 100 эпох обучения на обучающей части выборки, после каждого обучения буду устраивать контроль на отложенной части.
n_epochs = 100
train_errors = []
test_errors = []
for i in tqdm.tqdm(range(n_epochs)): # 100
_, train_err = sess.run([train_step, loss ], feed_dict={x_:X_Train.reshape((len(X_Train),1)) , y_: Y_Train.reshape((len(Y_Train),1))})
train_errors.append(train_err)
test_errors.append(sess.run(loss, feed_dict={x_:X_Test.reshape((len(X_Test),1)) , y_: Y_Test.reshape((len(Y_Test),1))}))Первое выполнение сессией одновременно операций train_step и loss делает сразу и обучение, и оценку ошибки на обучающей выборке, т.е. собственно оценку того, как хорошо мы запомнили выборку. Второе выполнение сессии — подсчет потерь на тестовой выборке. В параметре feed_dict я передаю в граф значения для плейсхолдеров и делаю reshape для того, чтобы массивы данных совпадали по размерности. Там, где в плейсхолдере стояло значение None, можно передать любое число. Тензоры с такими неопределенными размерами называются динамическими, и вот тут я их использую, чтобы передавать в граф батчи с примерами для обучения.
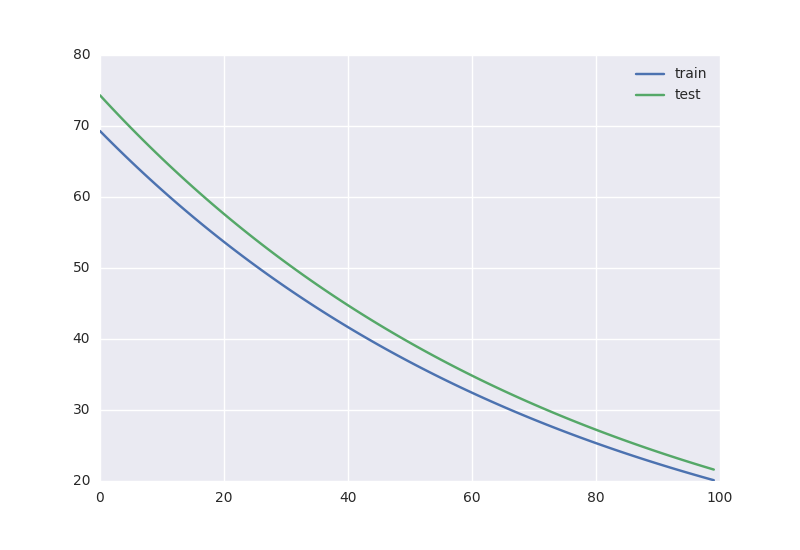
Получается вот такая динамика обучения:
В этом графе присутствуют вспомогательные переменные с градиентами и операции инициализации, они вынесены в отдельный блок.
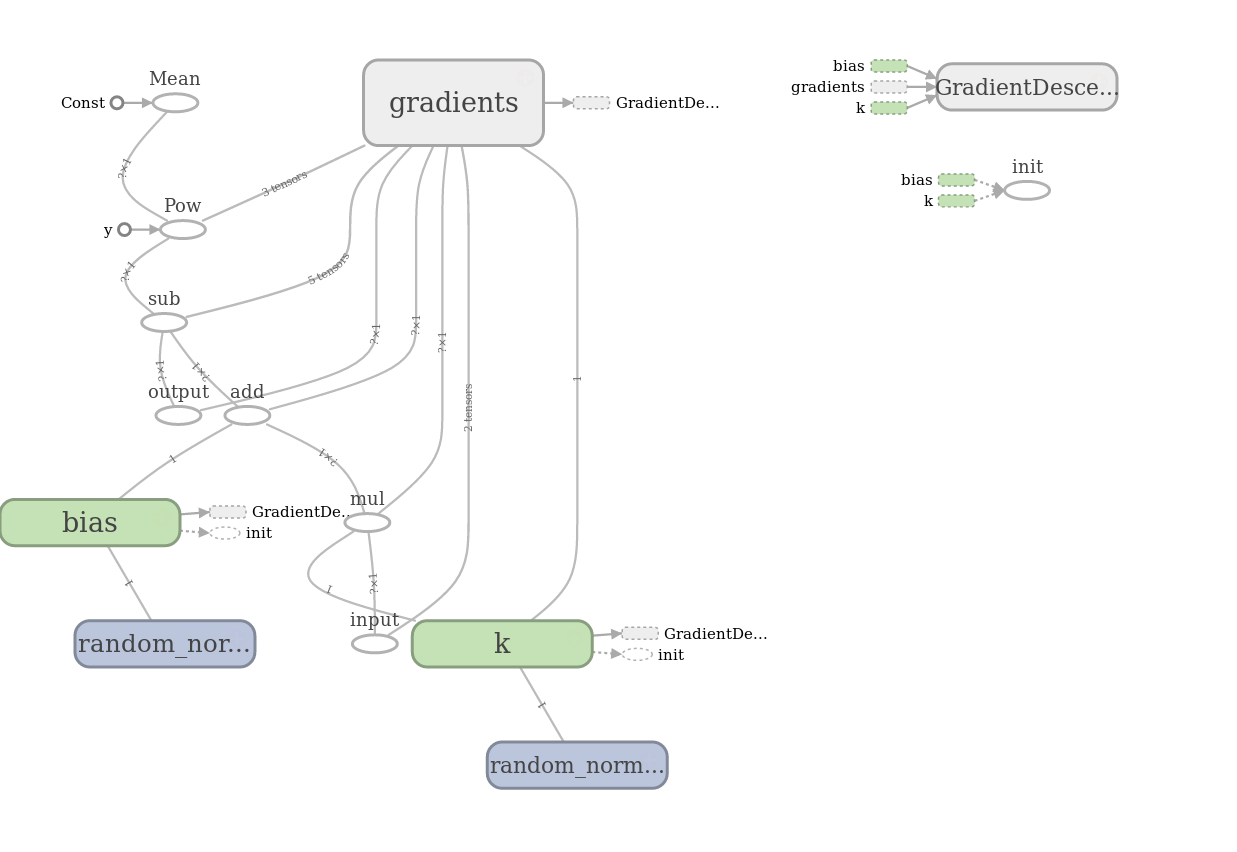
А вот и результаты вычисления модели:
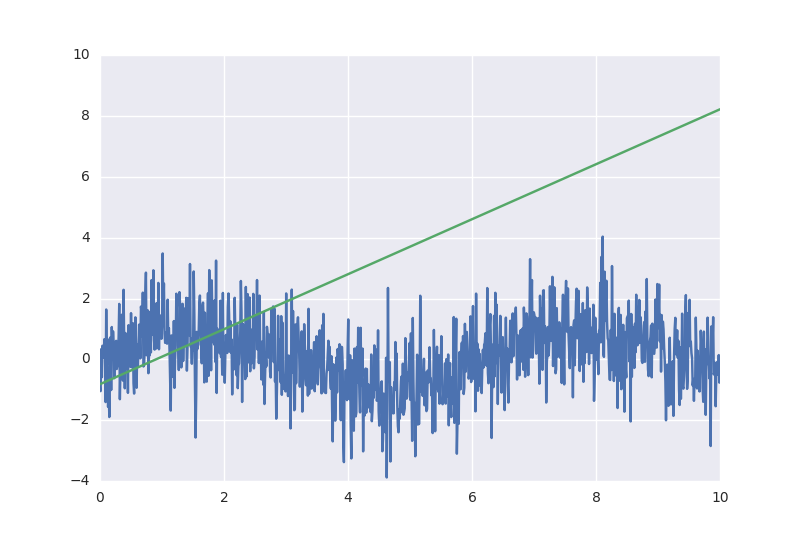
Значения для графика я вычислил вот таким способом:
sess.run(model_output, feed_dict={x_:x.reshape((len(x),1))})Тут в граф я передаю значение только для плейсхолдера x_ — остальное просто не нужно для вычисления выражения model_output.
Полный листинг программы есть тут. Результат получился предсказуемым для такой простой линейной модели.
Попробуем разнообразить регрессию полиномиальными признаками, регуляризацией и изменением скорости обучения модели.
В генерации набора данных добавим некоторое количество степеней и нормируем признаки с помощью PolynomialFeatures и StandardScaler из библиотеки scikit-learn. Первый объект создаст нам полиномиальных признаков сколько захотим, а второй нормирует их.
Для перехода к полиномиальной регрессии заменим всего несколько строк в графе вычислений:
order = 26 # степерь полинома
x_ = tf.placeholder(name="input", shape=[None, order], dtype=tf.float32)
y_ = tf.placeholder(name= "output", shape=[None, 1], dtype=tf.float32)
w = tf.Variable(tf.random_normal([order,1]), name='weights')
model_output = tf.matmul(x_,w)Фактически сейчас мы считаем . Очевидно, существует опасность переобучения модели на ровном месте, поэтому добавим регуляризационные штрафы на веса. Штрафы добавим к функции потерь (loss в примерах) в виде дополнительных слагаемых и получим почти что ElasticNet из sklearn.
loss = tf.reduce_mean(tf.square(y_ - model_output)) + 0.85* tf.nn.l2_loss(w) + 0.15* tf.reduce_mean(tf.abs(w)) Для самой популярной L2-регрессии существует отдельная функция l2_loss, а вот отбор признаков с помощью L1 придется реализовать вручную, но у нас это будет среднее по всем абсолютным значениям весов.
Ради примера добавлю еще одно существенное изменение, которое коснется темпа обучения. Довольно часто при обучении тяжелых нейросетей это просто необходимая мера для того, чтобы избежать проблем с обучением и получить приемлемый результат. Очень простая идея — по мере обучения постепенно понижать параметр шага, избегая больших неприятностей.
Вместо константного темпа будем использовать экспоненциальное затухание, которое я взял прямиком из документации:
learning_rate = tf.train.exponential_decay(starter_learning_rate, global_step, 100000, 0.96, staircase=True)Внутри функции скрывается формула:
decay_steps в нашем примере присвоено значение 100000, decay_rate — 0.96.
Получаем вот такие темпы снижения ошибок на обучении и контроле:
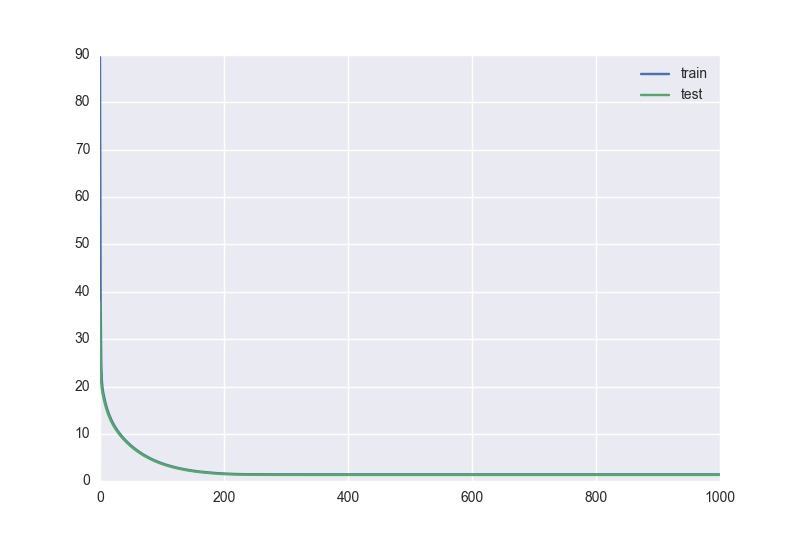
Помимо экспоненциального затухания есть и другие функции, которые позволяют снижать скорость обучения, и конечно ничто не мешает создать еще одну функцию под свои нужды.
Сама модель после обучения и разнообразных подборов параметров будет выглядеть как-то так:
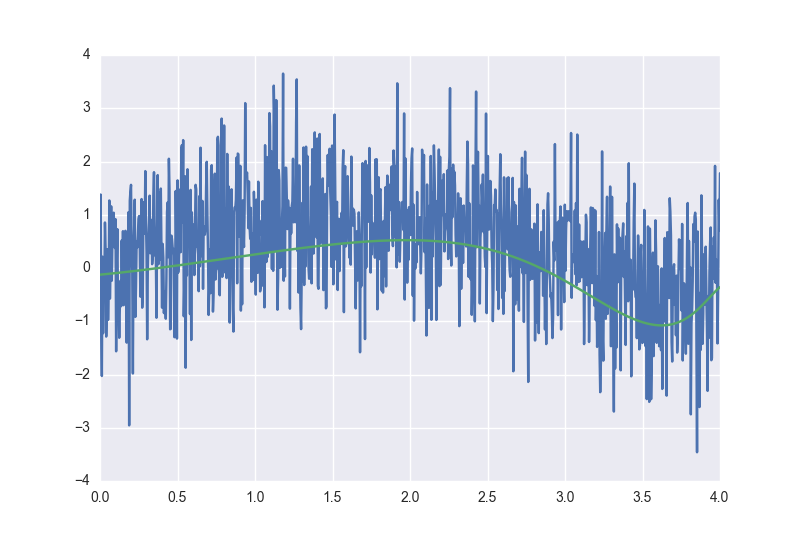
Для получения этого результата я изменял коэффициенты при регуляризации и скорости обучения. Перебор значений констант в формуле потерь — отличный способ увидеть своими глазами эффект работы регуляризаторов, крайне рекомендую поиграть с настройками в полном исходнике полиномиальной регрессии, он доступен тут.
Мы получили модель и было бы неплохо её сохранить. В TF всё достаточно просто — в API есть специальный объект-сериализатор, который делает две вещи:
Вот всё что нужно — это создать этот объект:
saver = tf.train.Saver()Сохранение состояния текущей сессии производится с помощью метода save:
saver.save(sess, "checkpoint_dir/model.ckpt")Уже как-то принято, что сохраненные состояния модели называют чекпойнтами, отсюда название папок и расширения файлов. Восстановление производится с помощью метода restore:
ckpt = tf.train.get_checkpoint_state(ckpt_dir)
if ckpt and ckpt.model_checkpoint_path:
print(ckpt.model_checkpoint_path)
saver.restore(session, ckpt.model_checkpoint_path)Сначала с помощью специальной функции получаем состояние чекпойнта (если вдруг в целевой директории нет сохраненной модели, функция вернет None). По умолчанию функция ищет файл checkpoint, но это поведение можно изменить с помощью параметра. После этого restore восстанавливает состояние графа.
Крайне полезная система в составе TF — web-dashboard, который позволяет собирать статистику из дампов и логов и наблюдать, что же всё-таки происходит во время вычислений. Крайне удобно то, что дашборд работает на веб-сервере и можно, например, запустив tensorboard на удаленной машине в облаке, наблюдать происходящее у себя в окне браузера.
Tensorboard умеет:
Обратная сторона медали — чтобы статистика попадала в дашборд, её нужно сохранять в логи (в формате protobuf) с помощью специального API. API не очень сложный, сгруппирован в tf.summary. Для сбора статистики нужно будет отдельно зарегистрировать интересующие переменные с помощью специальных функций и потом отдельно сохранить всё в лог.
Еще при использовании Tensorboard важно также не забывать про параметр name у переменных. Имя, которое будет присвоено переменной, потом будет использоваться для отрисовки графа, выбора в пользовательском интерфейсе дашборда, в общем, везде. Для небольших графов это не критично, но с ростом сложности задачи могут возникнуть проблемы с пониманием происходящего.
Есть несколько типов функций, которые сохраняют данные переменных различным образом:
tf.summary.histogram("layer_output", w_h)Данная функция позволит собрать гистограмму для выхода слоя и примерно оценить динамику изменений при обучении. Функция tf.summary.scalar("accuracy", learning_rate) будет сохранять число. Еще можно сохранять аудио и картинки.
Для сохранения логов нужно чуть больше: сначала нужно создать FileWriter для записи файла.
writer = tf.summary.FileWriter("./logs/nn_logs", sess.graph) # for 1.0
merged = tf.summary.merge_all()И объединить всю статистику в одном объекте.
Теперь нужно вот этот объект merged передать на выполнение в сессию и потом с помощью метода FileWriter добавить новые данные, полученные от сессии.
summary, op_result = sess.run([merged, op], feed_dict={X: X_train, Y: y_train,
p_keep_input: 1.0, p_keep_hidden: 1.0})
writer.add_summary(summary, i)Впрочем, для простого сохранения графа достаточно вот такого кода:
merged = tf.summary.merge_all(key='summaries')
if not os.path.exists('tensorboard_logs/'):
os.makedirs('tensorboard_logs/')
my_writer = tf.summary.FileWriter('tensorboard_logs/', sess.graph)И нюанс: по умолчанию Tensorboard локально доступен по адресу 127.0.1.1:6006. Надеюсь, сохранил читателям несколько секунд времени и нейронов этим замечанием.
Разберем каноничный пример с запоминанием функции xor, которую линейная модель не может усвоить из-за невозможности линейного разделения пространства признаков.
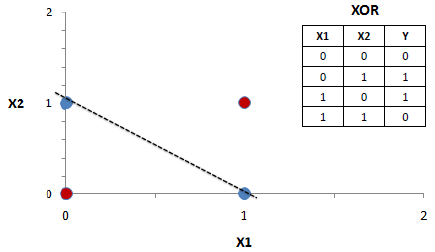
Многослойные сети усваивают функцию из-за того, что делают неявное преобразование пространства признаков в разделимое или же (в зависимости от реализации) делают нелинейное разбиение этого пространства. Мы реализуем первый вариант — создадим двухслойный перцептрон с нелинейной активацией слоев. Первый слой будет делать нелинейное преобразование, а второй слой — это практически линейная регрессия, которая работает на преобразованном пространстве признаков.
В качестве элемента нелинейности будем использовать функцию relu.
Определим структуру сети:
x_ = tf.placeholder(name="input", shape=[None, 2], dtype=tf.float32)
y_ = tf.placeholder(name= "output", shape=[None, 1], dtype=tf.float32)
hidden_neurons = 15
w1 = tf.Variable(tf.random_uniform(shape=[2,hidden_neurons ]))
b1 = tf.Variable(tf.constant(value=0.0, shape=[hidden_neurons ], dtype=tf.float32))
layer1 = tf.nn.relu(tf.add(tf.matmul(x_, w1), b1))
w2 = tf.Variable(tf.random_uniform(shape=[hidden_neurons ,1]))
b2 = tf.Variable(tf.constant(value=0.0, shape=[1], dtype=tf.float32))
nn_output = tf.nn.relu(tf.add(tf.matmul(layer1, w2), b2))В отличие от keras и других более высокоуровневых библиотек, TF, подобно Theano предполагает детальное определение каждого слоя как совокупности некоторых арифметических операций. Это верно не для всех видов слоёв, например, сверточные и dropout-слои определяются одной функцией, в то время как обычный полносвязный слой представляет собой объявление не только переменных для весов и сдвигов, но и самих операций (перемножение весов с выходом предыдущего слоя, добавление сдвига, применение функции активации).
Разумеется, довольно часто всё это оборачивается в подобную функцию:
def fully_connected(input_layer, weights, biases):
layer = tf.add(tf.matmul(input_layer, weights), biases)
return(tf.nn.relu(layer))При этом по моему собственному опыту объявление и инициализацию переменных удобнее оставлять снаружи: иногда требуется использовать их еще где-нибудь внутри графа (типичный пример — сиамские нейронные сети с общими весами) или же просто иметь доступ для простого логирования в файл и вывода текущих значений, а tensorboard по каким-то причинам пользоваться не хочется.
Используем элементарную функцию потерь:
gd = tf.train.GradientDescentOptimizer(0.001)
loss = tf.reduce_mean(tf.square(nn_output- y_))
train_step = gd.minimize(loss)и обучим:
x = np.array([[0,0],[1,0],[0,1],[1,1]])
y = np.array([[0],[1],[1],[0]])
for _ in range(20000):
sess.run(train_step, feed_dict={x_:x, y_:y})Получившийся граф:

В сравнении с регрессией практически ничего не изменилось: тот же процесс обучения, та же функция потерь. Единственная часть кода, которая сильно изменилась — это код построения вычислительного графа. Дошло до того, что у меня накопился набор скриптов под конкретные задачи, в которых я меняю только подачу данных и граф вычислений.
Конечно, в данном примере нет проверки на отложенной выборке. Убедиться в правильности работы сети можно с помощью вычисления выхода нейронной сети в графе:
sess.run(nn_output, feed_dict={x_:x})Полный код данного примера доступен тут. На ноутбуке пятилетней давности весь код отрабатывает за 5 секунд.
Конечно, в случае более сложных моделей добавляется валидация на отложенной выборке и слежение за качеством по мере обучения и встроенные в TF методы подачи данных в граф.
Довольно часто мир бывает несправедлив, и задача может не помещаться полностью в одно устройство. Или же менеджмент купил всего одну Tesla, и разработчики периодически вступают в конфликты из-за занятой карточки. В TF на такие случаи есть механизмы управления вычислениями. Внутри фреймворка устройства обозначаются как «/cpu:0», «/gpu:0» и т.д. Самое простое — можно указывать, где конкретно будет «жить» та или иная переменная:
with tf.device('/cpu:0'):
a = ... В этом примере переменная а отправится на процессор.
Еще можно передать в сессию конфигурационный объект, с помощью которого можно изменять проведение вычислений графа. Выглядит это примерно так:
cfg = tf.ConfigProto()
sess = tf.Session(config=cfg)В конфиге первым делом можно включить параметр log_device_placement, чтобы понимать, в какое вычислительное устройство отправилось вычисление той или иной части графа.
Допустим, в команде разработчиков можно договориться об ограничении потребления памяти GPU. Сделать это можно с помощью такого кода:
gpu_opts = tf.GPUOptions(per_process_gpu_memory_fraction=0.25)
sess = tf.Session(config=tf.ConfigProto(gpu_options=gpu_opts))В такой конфигурации сессия не будет потреблять более четверти памяти GPU, а это значит, что можно одновременно запустить расчеты еще нескольких моделей, а еще можно запустить модель считаться на CPU, но проще всего включить параметр allow_soft_placement, чтобы TF решал эти проблемы сам. Для этой части API документация еще довольно фрагментарна и некоторые ссылки ведут сразу на гитхаб в исходники конфигурационных классов. Часть свойств там отмечена как устаревшая, другая часть — как экспериментальная, поэтому тут будет нужна аккуратность.
TF буквально за год-полтора разросся настолько, что впору делать отдельные обзоры о применении сверточных и рекуррентных сетей, обучения с подкреплением и о применении фреймворка к различным задачам. В этом кратком обзоре не затронуты темы структур для чтения данных, свертки, разнообразные методы оптимизации и высокоуровневые библиотеки-обертки. Продолжить знакомство можно, попробовав для начала «поиграть» с настройками обучения и разобравшись с различными оптимизаторами. Ну и конечно попробовать TF в соревнованиях на Kaggle!
Автор выражает благодарность sovcharenko, Ferres и bauchgefuehl за помощь в подготовке текста.
UPD:
Jupyter-ноутбук со статьей и всеми исходниками доступен тут.