https://habr.com/ru/post/466263/- Высокая производительность
- Python
- Программирование
- DevOps
- Микросервисы
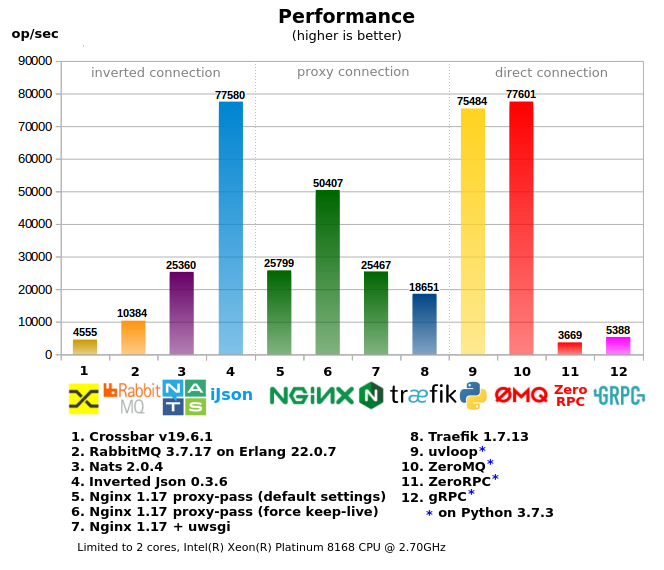
Сравниение различных инструментов (RabbitMQ, Crossbar.io, Nats.io, Nginx и др.) для организации RPC между микросервисами.
1. Тесты
Все инструменты поделены на 3 группы:
- «Direct connection» — когда клиент напрямую обращается к воркеру, в проектах с многочисленным количеством воркеров/сервисов является самым сложным в конфигурировании, требует «умного клиента», т.е. клиент при вызове должен обладать информацией как и куда отпавлять запрос (либо нужен дополнительный локальный прокси), как правило производит наименьшую нагрузку на сеть.
- «Proxy connection» — вариант с единой входной точкой, простой клиент, но при этом сохраняются сложности на стороне воркеров/серисов — проброс и выделение портов, регистрация адресов на прокси, более сложная настройка фаервола, зачастую используются дополнительные иструменты для управления за всем этим хозяйством.
- «Inverted connection» — единая точка входа как для клиентов так и для воркеров (может рассматриваться как ESB), наиболее простая настройка сети.
- Использование памяти и процесора взято из `docker stats`
- В «2-core» тесте сервер и клиенты с ворерками разделены по разным ядрам, чтобы уменшить влияние друг на друга, поэтому сервер ограничен 2-мя ядрами через taskset (multi-core тест без ограничений)
Некоторые мысли по бенчмарку ниже.
2. MQ или RPC
Хоть эти 2 способа комуникации разные, иногда первый используется вместо второго и наоборот.
Если попробовать очертить границы, когда что использовать, то может получится что-то такое:
- RPC (вызов процедуры) — когда клиент требует ответ немедленно (в короткий отрезок времени), когда воркер должен ответить пока клиент ждет ответ, и если клиент ушел (по таймауту), то этот ответ уже не нужен (это почему не нужно сохранять «запрос», как это часто делается в MQ системах).
Например когда вы делаете некий запрос в БД — вы делаете RPC, вы не захотите использовать MQ для этого.
- MQ — когда ответ не нужен (немедленно), когда нужно просто выполнить какую-то задачу в конечном итоге или просто передать данные.
Например для рассылки писем вы можете отправить задачу через MQ
3. RPC over RabbitMQ
RabbitMQ часто используется для организации RPC, но как и подобные MQ системы создает дополнительный оверхед, из-за чего его использование получается не очень производительным.
Если вы используете «очередь» для RPC, то вам необходимо чистить каналы, т.к. если воркер упал на какое-то время, то после перезапуска он может получить кучу неактуальных задач, т.к клиенты все это время слали запросы и кроме того, впустую ждали ответа т.к. воркер был не активен. Итого воркер получит задачу даже если клиент ушел до того, так же и с клиентом, если не чисить канал клиента, то он может забиться не принятыми ответами от воркера, хотя в RabbitMQ можно закрывать клиентский канал, но при этом катастрофически падает производительность.
Так же нужно делать пинг воркера, чтобы знать жив ли он.
Кроме того ресурсы тратятся на работу с каналами, когда в RPC системах данные просто пересылаются воркеру и обратно.
4. Inverted Json
Сущесвтует множество различных MQ систем, но не так много Job-серверов (RPC), таких как Gearman/Crossbar.io — это очень маленький выбор, поэтому разрабочики часто берут MQ системы для RPC.
Поэтому был создан
Inverted JSON (iJson) — прокси сервер с http интерфейсом, где клиенты и воркеры подключаются как сетевой клиент: [client] -> [Inverted Json] < — [worker], написан на C/C++, использует epoll, конечные автоматы для роутинга, потоковый парсер json, слайсы вместо строк* и пр. способы для лучшей производительности.
Преимущества Inverted JSON перед RabbitMQ:
- Не нужно чистить каналы клиента и воркера от не принятых сообщений
- Не обязательно пинговать воркер, клиент получит ошибку немедленно если воркер отключится (при keepalive соединении)
- Проще апи — просто http запрос (как правило уже поддерживается всеми языками и фреймворками)
- Быстрее работает и потребляет меньше памяти
- Более простой способ отправлять команды на конкретный воркер (например если в очереди несколько воркеров, а работать надо с одним конкретным)
Другая информация о Inverted Json
- Возможность передавать бинарные данные (не только json, как может показаться из названия)
- Не обязательно указывать id если воркер подключен как keep-alive, Inverted Json просто соединяет клиент и воркер напрямую.
- Возможность «подписки» на несколько комманд (каналов), подписка на паттерн (например command/*) без потери производительности.
- Docker образ всего 2.6 Мб (slim версия)
- Ядро Inverted Json всего ~1400 строк кода (v0.3), меньше кода — меньше багов ;)
- Inverted JSON не модифицирует тело запроса (body), а пересылает как есть.
5. Попробуйте Inverted Json за 3 минуты
Вы можете попробовать Inverted Json прямо сейчас если у вас есть
Docker и
curl:

Описание из картики:
1) Запуск docker образа
Inverted Json на 80 порту (можете выбрать любой), --log 32 логирует входяшие запросы:
$ docker run -it -p 80:8001 lega911/ijson --log 32
2) Регестрируем воркер для задачи «calc/sum», и ждем задачу:
$ curl localhost/rpc/add -d '{"name": "calc/sum"}'
3) Клиент делает RPC запрос calc/sum:
$ curl localhost/calc/sum -d '{"id": 15, "data": "2+3"}'
4) Воркер получает задачу `{«id»: 15, «data»: «2+3»}` — данные без изменения, теперь нужно отправить результат на тот же id:
$ curl localhost/rpc/result -d '{"id": 15, "result": 5}'
… и клиент получает результат как есть
`{"id": 15, "result": 5}`
5.1. JsonRPC
JsonRPC 2 не поддерживается, но есть некоторые зачатки, например клиент может отправлять запросы наподобии (url /rpc/call):
{"jsonrpc": "2.0", "method": "calc/sum", "params": [42, 23], "id": 1}
принимать ошибки типа:
{"jsonrpc": "2.0", "error": {"code": -32601, "message": "Method not found"}, "id": null}
Впрочем если будет спрос, то поддержка JsonRPC может быть улучшена.
5.2. Пример клиента и воркера на Python
# client.py
import requests
print(requests.post('http://127.0.0.1:8001/test/command', json={'id': 1, 'params': 'Hello'}).json())
# worker.py
import requests
while True:
request = requests.post('http://127.0.0.1:8001/rpc/add', json={'name': '/test/command'}).json()
response = {
'id': request['id'],
'result': request['params'] + ' world!'
}
requests.post('http://127.0.0.1:8001/rpc/result', json=response)
А тут вы можете найти пример в режиме «worker mode», который является более производительным и компактным.
6. Некоторые мысли о результате бенчмарка
- Crossbar.io: основан на python, поэтому он не так быстр и не может использовать несколько ядер из-за GIL.
- RabbitMQ: RPC поверх MQ, что накладывает дополнительный оверхед. Быстрое падение производительности при повышении нагрузки (в тесте не отражено).
- Nats: показал себя не плохо, хотя уступает Inverted Json, т.к. RPC over MQ, так же будет иметь те же проблемы.
- Inverted Json: достиг сетевого лимита (т.е. запуск нескольких копий тестов на разных ядрах, суммарно не дает больший результат), показал самое эффективное использование памяти и процессора относительно производительности.
- Nginx: при proxy-pass производительность быстро падает если не включен keep-alive режим (выключен по умолчанию), связано с тем что linux не дает открывать/закрывать много сокетов в короткий промежуток времени (в тесте это не отражено).
- Traefik: очень прожорлив, использовал 600% CPU в пике, по скорости уступет nginx
- uvloop (под asyncio) — дает очень хорошую производительность, т.к. большая часть написана на C/C++, для RPC является более предпочтительным чем ZeroMQ
- ZeroMQ — сам воркер написан на Python, поэтому он уперся в ядро, хотя многопроцессорный тест потребляет более 100% CPU, это за счет того что сам zeromq написан на C/C++ без захвата GIL. Дает большую производительность, но с другой сторны, если воркер будет делать не просто a+b, любое усложнение приведет к значительному снижению RPC, т.к. упрется в ядро ещё раньше.
- ZeroRPC: заявлено как легкая обертка над ZeroMQ, в реальности потеряно 95% производительности от ZeroMQ, похоже что она не такая уж и легкая.
- GRPC: вариант для питона производит много шаблонного питон кода, т.е. обрабочик получается тяжелым и быстро упирается в CPU, для компиллируемых языков вероятно такой проблемы нет.
- 2-core и multi-core тесты, в multi-core некоторые показатели снизились, потому что приходится конкурировать за CPU ресурсы с клиентским тестовым кодом, с другой стороны некоторые тесты дали большую производительность, например Traefik, который съел 600% CPU
7. Заключение
Если у вас большая компания и много сотрудников, тогда вы можете позволить себе поддерживать разные сложные инструменты для организации прямых соединиений между микросервисами, что может дать эффективную комуникацию.
А для маленьких компаний и стартапов, где небольшим колективом нужно решать задачи из разных сфер, Inverted Json может съэкономить время и ресурсы.
Для развития Inverted Json, в планах стоит поддержка pubsub, kubernetes, и другие интересные идеи.
Если вам интересен проект или просто хотите помочь автору, вы можете поставить звездочку на
github проекте, спасибо.
PS:
- На создание этой статьи включая тесты ушло времени больше чем на создание самого Inverted Json
- Прототипы Inverted Json так же были написаны на 1. python + asyncio + uvloop, 2. на GoLang
- Тесты были просмотрены разными специалистами
- «слайсы вместо строк» — в большинстве случаев при парсинге http/json идет не копирование даннных в строки, а используется ссылка на исходные данные, таким образом не происходит лишнее выделение и копирование памяти.
- Если вы будете тестировать — не используйте requests в python, он очень медленный, лучше pycurl, в тестах используется этот врапер.
- Бенчмарк находится тут
- Исходники тут


