http://habrahabr.ru/post/219579/
Всем привет!

Друзья, не мне вам рассказывать, да и сами вы знаете о том, как делается backend для серверных/клиент-серверных приложений. В нашем идеальном мире всё начинается с проектирования архитектуры, затем выбираем площадку, затем прикидываем нужное количество машин, как виртуальных, так и нет. Затем происходит сам процесс поднятия архитектуры для разработки/тестирования. Всё готово? Ну поехали писать код, делать первый коммит, обновлять код на сервере из репозитория. Открыли консоль/браузер проверили и поехало. Пока всё просто, а что дальше?
С течением времени архитектура неизбежно растёт, появляются новые сервисы, новые сервера и тут уже пора подумать о масштабируемости. Серверов чуть больше чем 1?, — надо бы как то логи все вместе собирать. Сразу в голову лезут мысли про аггрегатор логов.
А когда что-то, не дай бог, падает, сразу приходят мысли о мониторинге. Знакомо, не так ли? Вот и я с друзьями наелся этого. А когда ты в команде — появляются и другие сопутствующие проблемы.
Можно сразу подумать что мы ничего не слышали про aws, jelastic, heroku, digitalocean, puppet/chief, travis, git-hooks, zabbix, datadog, loggly… Уверяю вас это не так. Мы пытались подружиться с каждой из этих систем. Точнее мы настраивали каждую из этих систем для себя. Но не получали должного эффекта. Всегда появлялись какие то подводные камни и часть работы хотелось бы, как минимум, автоматизировать.
Живя в таком мире довольно большое количество времени, мы подумали — «ну мы же разработчики, давай-те сделаем с этим что-то». Прикинув проблемы, сопровождающие нас на каждом этапе создания и развития проекта — выписали их на отдельной страничке и превратили их в фичи будущего сервиса.
И спустя 2 месяца из этого родился сервис —
lastbackend.com:

Проектирование
Мы начали с самой первой проблемы при построении серверной системы, а именно с построения визуальной схемы проекта. Не знаю как вам, но для меня видеть какой элемент, с каким связан, как текут потоки данных вызывает восхищение, в сравнении со списком серверов и настроенного окружения в вики или в гугл доке. Но судить вам.
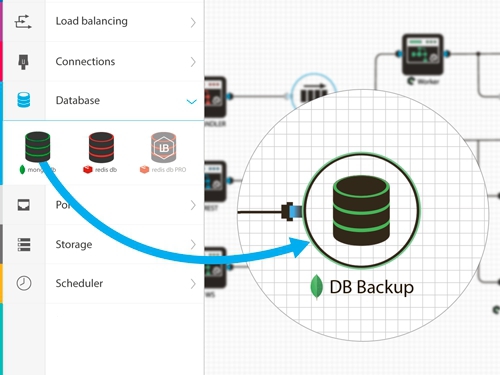
Сам процесс проектирования схемы до боли простой и интуитивный: слева список элементов backend-а, справа рабочее поле. Вот просто берём и перетаскиваем. Надо дать возможность node.js элементу подключиться к mongodb? Пожалуйста — берем и мышкой проводим соединение.

Настройка и масштабирование
Каждый элемент в системе уникален, его необходимо настроить и если надо включить его авто-масштабирование. Если элемент является балансировщиком нагрузки, есть место где указываются правила выбора upstream-а. Если элемент имеет исходный код — указываем его репозиторий, переменные окружения, зависимости. Система сама его скачает, установит, запустит.
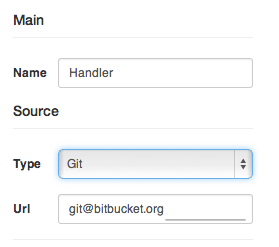
И конечно же мы подумали и об авто-деплое — изменились исходники в определённой ветке — хитро и быстро обновили элемент. Мы старались всё сделать удобным, ведь сами пользуемся и первыми видим все недостатки.
Развёртывание
И вот самый интересный момент. Когда схема готова и настроена, её развёртывание занимает несколько секунд. Иногда бывает дольше, а иногда вообще моментально. Всё зависит от типов элементов и его исходного кода. Мы в основном программируем на node.js и наши схемы разворачиваются за пару секунд. Самый захватывающий момент — видеть как все настроенные элементы на схеме «оживают» и загораются индикаторы, указывающее текущее состояние элемента.
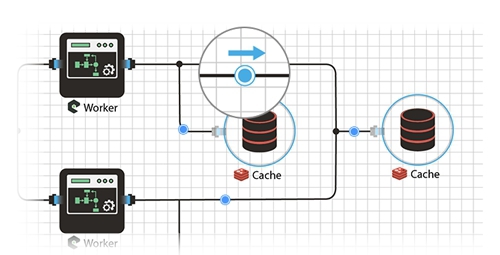
Забыл добавить, что мы имеем возможность запускать каждый элемент, у различного хостера/дата-центре. Например для балансировки траффика между странами, можно один элемент запустить в одной стране, другой во второй, а базу данных к примеру где нибудь по центру разместить. Пример конечно не очень, но в целом, думаю, возможность довольно полезная, особенно если знать как и где её применить.
Вот в принципе и основная часть, позволяющая быстро, красиво и без проблем поднять серверную часть какого либо проекта, однако мы сразу вспомнили про дальнейшие проблемы, а именно:
Аггрегация логов
Каждый элемент аггрегирует лог в единое хранилище логов, где можно их смотреть и анализировать, делать поиск и выборки. Теперь нет необходимости подключаться по ssh и grep-ом искать какую либо затаившуюся информацию, или просто анализировать данные
Мониторинг и система оповещения
Естественно нам и самим охота поехать на рыбалку или просто отдохнуть зная, что если что-то происходит не то, тебе об этом обязательно доложат. Вот мы и делаем так, что бы обо всех сбоях была моментальная информация. Теперь и голова не болит, о том, что можешь пропустить что нибудь важное.
Резюме
Вот в принципе основные проблемы, которые мы старались и стараемся решить нашим сервисом и хоть как то облегчить жизнь брату-разработчику.
Естественно у меня не получилось перечислить все фичи, постарался выделить только главные, однако в комментариях могу более подробно ответить на все вопросы и пожелания.
Спасибо за внимание. Очень хотелось бы первым делом прочитать
ваше мнение, ответить на
ваши вопросы, записать
ваши советы и пожелания, а так же всем
выдать доступ в закрытое бета тестирование сервиса, которое по предварительным планам начнётся на майских праздниках.
Получить приглашение на бету можно прямо по этой ссылке. В день открытия тестирования — придёт письмо с данными доступа.PS
Так же друзья, если интересно, можем начать серию технических статей по стеку используемых технологий, а именно node.js, mongodb, redis, sockets, angular, svg и т.п.