Автоматическая суммаризация текстов с помощью трансформеров Hugging Face. Часть 2
- вторник, 26 апреля 2022 г. в 00:37:12
Перед вами вторая часть из серии материалов, состоящей из двух публикаций. Здесь я предлагаю практическое руководство по архитектуре ML-проекта, освоение которого позволит вам оценить качество автоматического реферирования (суммаризации) текстов в той области, в которой вы работаете.

Для того чтобы ознакомиться с начальными сведениями о реферировании текстов, чтобы почитать обзор этого руководства, узнать, из раздела 1, о том, что является точкой отсчёта для оценки эффективности моделей — обратитесь к первому материалу.
Сегодняшняя публикация состоит из трёх частей, представленных, с применением сквозной нумерации, 2, 3 и 4 разделами. Здесь мы, соответственно, поговорим о реферировании без подготовки (с использованием предварительно обученной модели), об обучении предварительно обученной модели на нашем наборе данных, об оценке эффективности обученной модели.
В этом материале мы прибегнем к концепции обучения без подготовки (zero-shot learning, ZSL). Это значит, что мы будем пользоваться моделью, обученной реферированию текстов, но не видевшую ни одного примера из набора данных arXiv. Это немного похоже на то, как если некто, всю жизнь писавший пейзажи, пытается написать портрет. Он умеет рисовать, но тонкости написания портретов ему неизвестны.
Код, который мы будем тут рассматривать, можно найти в этом блокноте Jupyter Notebook.
В последние годы обучение без подготовки стало популярным из-за того, что оно позволяет использовать эталонные NLP-модели без дополнительного обучения. Их эффективность — это нечто совершенно удивительное. Так, недавно специалисты из Big Science Research Workgroup выпустили модель T0pp (произносится как «Tи ноль плюс плюс»). Эта модель создавалась специально для исследования возможностей применения обучения без подготовки для решения различных задач. В бенчмарке BIG-bench эта модель во многих случаях обходит модели, которые в шесть раз больше её. Ещё она способна показать результаты, лучшие, чем показывает GPT-3 (которая в 16 раз больше её), в некоторых других NLP-бенчмарках.
Ещё одним преимуществом ZSL является тот факт, что для использования таких моделей достаточно написать буквально пару строк кода. Испытав такую модель, мы создадим ещё одну точку отсчёта, опираясь на которую будем оценивать повышение эффективности модели после того, как мы осуществим её тонкую настройку с использованием наших данных.
Для того чтобы воспользоваться ZSL-моделями, мы можем прибегнуть к API Pipeline Hugging Face. Этот API позволяет пользоваться моделями для автоматического реферирования текстов, написав минимальный объём кода. API берёт на себя решение основных задач, связанных с обработкой данных в рамках NLP-модели:
Осуществляет препроцессинг текста, преобразование его в формат, понятный модели.
Передаёт модели текст, прошедший предварительную обработку.
Производит пост-процессинг результатов, выдаваемых моделью, приводя их к виду, понятному человеку.
Этот API использует модели для автоматического реферирования текста, которые имеются в коллекции моделей Hugging Face.
Для того чтобы воспользоваться этим API — напишем следующий код:
from transformers import pipeline
summarizer = pipeline("summarization")
print(summarizer(text))Вот и всё! Код загружает модель и локально, на компьютере разработчика, создаёт рефераты. Если вам интересно узнать о том, какая конкретно модель тут используется — можно либо заглянуть в исходный код, либо воспользоваться следующей командой:
print(summarizer.model.config.__getattribute__('_name_or_path'))После запуска этой команды окажется, что стандартная модель для реферирования текстов называется sshleifer/distilbart-cnn-12-6:

Страницу со сведениями о модели можно найти на сайте Hugging Face. Там, кроме прочего, можно узнать о том, что модель обучалась на двух наборах данных — CNN Dailymail и Extreme Summarization (XSum). Стоит отметить, что эта модель не знакома с набором данных arXiv, и то, что она используется лишь для реферирования текстов, которые похожи на те, на которых она обучалась (это, в основном, новостные статьи). Числа 12 и 6 в названии модели указывают, соответственно, на количество слоёв энкодера и декодера. Рассказ о том, что это за слои, выходит за рамки этой статьи. Подробности об этом можете почитать в данной публикации, подготовленной создателем модели.
Мы воспользовались моделью, применяемой API Pipeline по умолчанию, но вам я предлагаю испытать различные предварительно обученные модели. Все модели, подходящие для реферирования текстов, можно найти на сайте Hugging Face. Для того чтобы выбрать конкретную модель при вызове API Pipeline — можно указать её имя, воспользовавшись конструкцией такого вида:
summarizer = pipeline("summarization", model="facebook/bart-large-cnn")Мы пока не говорили о двух возможных подходах, применимых к реферированию текстов, об экстрактивном (extractive) и абстрактном (abstractive) реферировании. Экстрактивное реферирование — это стратегия, основанная на формировании реферата из фрагментов, взятых из исходного текста. А абстрактное реферирование предусматривает обобщение исходного текста с использованием новых предложений. Большинство моделей для реферирования текстов основано на системах генерирования новых текстов (это — модели, направленные на генерирование текстов на естественном языке, вроде, например, GPT-3). Получается, что модели для автоматического реферирования текста генерируют новые тексты, то есть они относятся к системам абстрактного реферирования.
Теперь, когда мы знаем о том, как пользоваться API Pipeline — мы воспользуемся им при обработке того же набора данных, который обрабатывали в первой публикации. Это позволит нам создать ещё один набор показателей, характеризующих качество модели, ещё одну точку отсчёта, позволяющую оценивать другие модели. Сделать это мы можем, воспользовавшись следующим циклом:
candidate_summaries = []
for i, text in enumerate(texts):
if i % 100 == 0:
print(i)
candidate = summarizer(text, min_length=5, max_length=20)
candidate_summaries.append(candidate[0]['summary_text'])С помощью параметров min_length и max_length мы управляем размерами реферата, генерируемого моделью. В данном примере параметр min_length установлен в значение 5, так как мы хотим, чтобы длина реферата составляла бы, как минимум, 5 слов. Оценив эталонные рефераты текстов (то есть — реальные заголовки материалов), мы определили, что 20 будет приемлемым значением для max_length. Но, напомню, это — лишь наша первая попытка применения модели. На экспериментальной фазе проекта эти два параметра могут и должны быть изменены для того чтобы проверить, повлияет ли это на эффективность работы модели.
Если вы уже знакомы с генерированием текстов, то вы, возможно, знаете о том, что на тексты, создаваемые моделями, влияет достаточно много параметров, а не только те два, что мы описали выше. Такие параметры, например, могут называться beam_search (лучевой поиск), sampling (сэмплирование), temperature (температура). Они позволяют нам лучше контролировать текст, генерируемый моделью. Например — делать стиль текста легче, уменьшать использование в нём повторяющихся конструкций. API Pipeline подобные вещи не поддерживает. Если заглянуть в его исходный код, то окажется, что там используются лишь параметры min_length и max_length. Правда, после того, как мы обучим и развернём собственную модель, у нас будет доступ к этим параметрам. Подробнее об этом мы поговорим в разделе №4.
После того, как мы сгенерировали рефераты с использованием ZSL-модели, мы снова можем прибегнуть к вычислению показателей ROUGE для сравнения рефератов, выданных моделью, с эталонными рефератами:
from datasets import load_metric
metric = load_metric("rouge")
def calc_rouge_scores(candidates, references):
result = metric.compute(predictions=candidates, references=references, use_stemmer=True)
result = {key: round(value.mid.fmeasure * 100, 1) for key, value in result.items()}
return resultПосле проведения этих вычислений на результатах, выданных ZSL-моделью, мы получили следующее:

Если сравнить эти результаты с теми, которые мы в предыдущей публикации решили считать базой для оценки эффективности моделей, то окажется, что ZSL-модель работает хуже нашей простой эвристической модели, которая просто выдаёт первые предложения обрабатываемых текстов. Опять же, это нельзя назвать неожиданностью. Хотя эта модель и знает о том, как реферировать новостные статьи, она никогда не сталкивалась с примером реферирования выдержек из научной публикации.
К настоящему моменту мы создали два набора базовых показателей. Один получен с применением простой эвристической модели, второй — с помощью ZSL-модели. Сравнивая показатели ROUGE, мы видим, что сейчас простая модель показывает себя лучше, чем модель, использующая технологии глубокого обучения.
rouge1 | rouge2 | rougeL | rougeLsum | |
Простая модель, использующая первое предложение (базовая линия) | 31,3 | 15,5 | 26,4 | 26,4 |
Модель с реферированием без подготовки | 30,3 | 14,0 | 26,1 | 26,1 |
В следующем разделе мы возьмём ту же самую модель, основанную на глубоком обучении, и попытаемся улучшить качество её работы. Сделаем мы это путём обучения модели на наборе данных arXiv (этот шаг ещё называют «тонкой настройкой модели»). Мы воспользуемся тем фактом, что модель уже обладает общими сведениями о реферировании текстов. Затем мы продемонстрируем ей множество примеров из набора данных arXiv. Модели глубокого обучения весьма хороши в деле идентификации паттернов в наборах данных после того, как эти модели учат на таких данных. Поэтому мы ожидаем, что наша модель, после обучения, будет лучше справляться с поставленной перед ней задачей.
В этом разделе мы обучим на нашем наборе данных ZSL-модель (sshleifer/distilbart-cnn-12-6), которой пользовались в предыдущем разделе для генерирования рефератов текстов без подготовки. Наша идея заключается в том, чтобы научить модель тому, как должны выглядеть рефераты выдержек из научных публикаций, показав ей множество примеров. Со временем модель должна идентифицировать в нашем наборе данных паттерны, что позволит ей создавать более качественные рефераты.
Стоит ещё раз отметить то, что если у вас имеются размеченные данные, в частности — тексты и соответствующие им рефераты, то вам стоит использовать для обучения модели именно эти данные. Только так модель может изучить паттерны, присущие вашим данным.
В этом блокноте можно найти полный код, используемый для обучения модели.
Обучение модели, подобной нашей, если учить её на ноутбуке, может занять несколько недель. Поэтому мы, вместо этого, воспользуемся средой для обучения и развёртывания моделей Amazon SageMaker и задачами обучения (training jobs). Подробности о данной среде можно узнать из этой публикации. Здесь я лишь кратко коснусь возможностей Amazon SageMaker, не считая того, что она позволяет пользоваться GPU-инстансами.
Представим, что в нашем распоряжении имеется кластер GPU-инстансов. В таком случае мы, для обучения модели, скорее всего, создадим Docker-образ. Это позволит нам с лёгкостью создавать реплики соответствующего окружения на разных машинах. Затем мы установим необходимые пакеты, а, так как мы планируем использовать несколько инстансов, нам понадобится настроить систему распределённого обучения моделей. Когда обучение будет завершено, нам нужно будет как можно быстрее отключить соответствующие компьютеры, так как подобные ресурсы достаточно дороги.
При использовании Amazon SageMaker мы от всего этого абстрагируемся. На самом деле, мы можем обучать модели так же, как уже описывали, задавая параметры обучения и вызывая единственный метод. Среда SageMaker позаботится обо всём остальном, включая остановку GPU-инстансов после завершения обучения ради экономии средств.
Кроме того, ранее в этом году Hugging Face и AWS объявили о партнёрстве. А это ещё сильнее упрощает задачу обучения моделей Hugging Face в среде SageMaker. Соответствующий функционал доступен благодаря созданию контейнеров Hugging Face AWS Deep Learning Containers (DLCs). Такие контейнеры включают в себя трансформеры и токенизаторы Hugging Face, а так же — библиотеку наборов данных. Это позволяет использовать данные ресурсы для обучения и проверки моделей. Список доступных DLC-образов Hugging Face можно найти здесь. Их поддерживают и регулярно обновляют, применяя к ним исправления безопасности. В этом GitHub-репозитории можно найти множество примеров того, как обучать модели Hugging Face с помощью этих DLC и с помощью Hugging Face Python SDK.
Мы, в качестве образца, воспользовались одним из этих примеров, так как там реализовано почти всё, что нам нужно: обучение модели для реферирования текстов на пользовательском наборе данных в распределённой среде (с использованием более чем одного GPU-инстанса).
Правда, нам, пользуясь этим примером, нужно учесть то, что в нём используется набор данных из коллекции наборов данных Hugging Face. А мы хотим пользоваться собственными данными, поэтому нам придётся немного поменять код в соответствующем блокноте.
Для того чтобы учесть тот факт, что мы используем при обучении модели собственный набор данных, нам понадобится воспользоваться каналами (channels). Подробности об этом можно найти здесь.
Лично меня термин «канал» слегка сбивает с толку, поэтому я, когда слышу «канал», думаю о «мэппинге», так как это помогает мне лучше представить себе происходящее. Объясню: как мы уже знаем, задача обучения разворачивает кластер инстансов Amazon Elastic Compute Cloud (Amazon EC2) и копирует в него Docker-образ. Но наш набор данных хранится в Amazon Simple Storage Service (Amazon S3), у этого Docker-образа нет к нему доступа. Задаче обучения нужно скопировать данные из Amazon S3 и поместить их в заданную папку образа. Делается это путём предоставления задаче сведений о том, где именно в Amazon S3 хранятся эти данные, и о том, в какое именно место образа их нужно скопировать для того чтобы к ним можно было бы обратиться при обучении модели. Получается, что мы настраиваем соответствие (мэппинг) того места в Amazon S3, где хранятся данные, с локальным путём образа.
Локальный путь можно указать при настройке задачи обучения, в разделе hyperparameters:
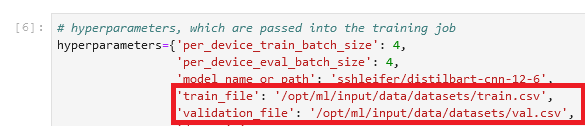
Затем мы сообщаем задаче обучения о том, где именно в Amazon S3 находятся данные. Делается это при вызове метода fit(), который запускает обучение модели:

Обратите внимание на то, что имя папки после /opt/ml/input/data совпадает с именем канала (datasets). Это позволяет задаче обучения скопировать данные из Amazon S3 в локальную папку.
Теперь мы готовы к запуску задачи обучения модели. Как уже было сказано, делается это путём вызова метода fit(). В нашем случае обучение заняло около 40 минут. В процессе обучения модели можно, пользуясь консолью SageMaker, наблюдать за его ходом и видеть дополнительные сведения о нём.

Теперь, когда модель обучена, пришло время оценить её эффективность.
Оценка эффективности модели, обученной на наших данных, очень похожа на то, чем мы уже занимались, оценивая ZSL-модель. Мы вызываем модель, она генерирует рефераты, а мы сравниваем их с эталонными рефератами, вычисляя показатели ROUGE. Но теперь модель находится на Amazon S3, в файле model.tar.gz (для того чтобы выяснить точный адрес файла — можно взглянуть на сведения о задаче обучения в консоли SageMaker). Как нам обратиться к этой модели и получить результаты обработки текста?
У нас есть два варианта: развернуть модель в среде SageMaker, или загрузить её на локальную машину, поступив так же, как при работе с ZSL-моделью. Тут я использую первый метод, разворачиваю модель в виде конечной точки SageMaker. Этот способ удобнее. Мы, кроме того, можем ускорить выдачу результатов работы модели путём выбора более мощного инстанса для конечной точки. Вот блокнот, ознакомившись с которым, вы можете узнать о том, как оценивать подобные модели локально.
Обычно развернуть обученную модель в SageMaker — это очень легко (можете снова взглянуть на пример с GitHub, подготовленный Hugging Face). После того, как модель будет обучена, вызывают estimator.deploy(), а всё остальное, в фоновом режиме, сделает SageMaker. Так как мы в этом руководстве решаем разные задачи в разных блокнотах Jupyter Notebook, нам надо, перед развёртыванием модели, найти задачу обучения и связанную с ней модель:

После того, как мы узнали о том, где именно находится модель, мы можем развернуть её в виде конечной точки SageMaker:
from sagemaker.huggingface import HuggingFaceModel
model_for_deployment = HuggingFaceModel(entry_point='inference.py',
source_dir='inference_code',
model_data=model_data,
role=role,
pytorch_version='1.7.1',
py_version='py36',
transformers_version='4.6.1',
)
predictor = model_for_deployment.deploy(initial_instance_count=1,
instance_type='ml.g4dn.xlarge',
serializer=sagemaker.serializers.JSONSerializer(),
deserializer=sagemaker.deserializers.JSONDeserializer()
)Развёртывание модели в SageMaker — это простая и понятная задача, так как тут используется набор инструментов, называемый SageMaker Hugging Face Inference Toolkit. Это — опенсорсная библиотека, направленная на развёртывание моделей, использующих трансформеры, в среде SageMaker. Обычно даже не нужно предоставлять системе скрипт для формирования результатов работы модели, так как библиотека сама решает эту задачу. Но в нашем случае этот набор инструментов снова использует API Pipeline, и, как было сказано во втором разделе, этот API не позволяет применять продвинутые приёмы генерирования текстов, вроде лучевого поиска и сэмплирования. Для того чтобы обойти эти ограничения — мы предоставляем системе собственный скрипт для формирования выходных данных модели.
Для получения первого набора показателей, характеризующих эффективность модели, мы, для формирования результатов, воспользуемся теми же параметрами, что и во втором разделе, при оценке ZSL-модели. Это позволяет нам сравнивать, как говорится, яблоки с яблоками:
candidate_summaries = []
for i, text in enumerate(texts):
data = {"inputs":text, "parameters_list":[{"min_length": 5, "max_length": 20}]}
candidate = predictor.predict(data)
candidate_summaries.append(candidate[0][0])Теперь посчитаем показатели ROUGE, чтобы сравнить то, что выдала модель, с эталоном:

Выглядит вдохновляюще! После первой попытки обучения модели, не настраивая гиперпараметры, мы смогли значительно улучшить показатели ROUGE.
rouge1 | rouge2 | rougeL | rougeLsum | |
Простая модель, использующая первое предложение (базовая линия) | 31,3 | 15,5 | 26,4 | 26,4 |
Модель с реферированием без подготовки | 30,3 | 14,0 | 26,1 | 26,1 |
Модель после тонкой настройки | 44,5 | 24,5 | 39,4 | 39,4 |
Теперь поэкспериментируем с моделью, прибегнем к более продвинутым приёмам, таким, как лучевой поиск и сэмплирование. Подробное описание смысла соответствующих параметров можно найти в этом материале. Попробуем воспользоваться некоторыми из новых параметров, назначив им значения, взятые практически случайным образом:
candidate_summaries = []
for i, text in enumerate(texts):
data = {"inputs":text,
"parameters_list":[{"min_length": 5, "max_length": 20, "num_beams": 50, "top_p": 0.9, "do_sample": True}]}
candidate = predictor.predict(data)
candidate_summaries.append(candidate[0][0])Запустив модель с этими параметрами, мы получили следующие результаты:

Результаты оказались не такими, как мы ожидали — показатели ROUGE, на самом деле, даже немного уменьшились. Но не позволяйте этому факту отбить у вас охоту экспериментировать с параметрами. Этот момент нашей работы представляет собой переход от окончания подготовки модели к началу экспериментов с ней.
Мы завершили первоначальную подготовку модели к работе и готовы перейти к экспериментальной фазе проекта. В этой серии публикаций, состоящей из двух частей, мы загрузили и подготовили данные, создали простую эвристическую модель, показатели которой служат точкой отсчёта для оценивания других моделей, создали ещё одну подобную модель, основанную на обучении без подготовки. Затем мы обучили ZSL-модель на наших данных и обнаружили значительное улучшение результатов её работы. Теперь пришло время экспериментов со всем тем, что мы создали, цель которых — улучшение рефератов текстов, генерируемых моделью. Проводя подобные эксперименты примите во внимание следующее:
Грамотно подходите к препроцессингу данных. Например, удаляйте стоп-слова и знаки препинания. Не стоит недооценивать эту часть работы. Во многих data-science-проектах предварительная обработка данных — это один из самых важных аспектов работы (а может — и самый важный). Дата-сайентисты обычно тратят на решение этой задачи большую часть своего времени.
Пробуйте различные модели. В этом руководстве мы воспользовались стандартной моделью для реферирования текстов (sshleifer/distilbart-cnn-12-6), но существует множество других моделей, рассчитанных на ту же задачу. Одна из них может подойти для вашей задачи лучше, чем стандартная модель.
Занимайтесь настройкой гиперпараметров. В ходе обучения модели мы использовали определённый набор гиперпараметров (скорость обучения, количество эпох и так далее). Стандартные значения параметров — это не истина в последней инстанции. Скорее — наоборот. С их значениями стоит поэкспериментировать для того чтобы разобраться с тем, как именно они воздействуют на эффективность работы вашей модели.
Используйте различные параметры для генерирования текста. Мы уже попробовали генерировать тексты с разными параметрами, воспользовавшись лучевым поиском и сэмплированием. Мы сделали это лишь один раз, с одним набором параметров и значений. Рекомендую вам попробовать разные параметры и поэкспериментировать с их значениями. Подробности об этом можно почитать здесь.
Надеюсь, что вы дочитали это руководство до конца, и что смогли вынести из него что-нибудь полезное.
Мы в wunderfund.io занимаемся высокочастотной алготорговлей с 2014 года. Высокочастотная торговля — это непрерывное соревнование лучших программистов и математиков всего мира. Присоединившись к нам, вы станете частью этой увлекательной схватки.
Мы предлагаем интересные и сложные задачи по анализу данных и low latency разработке для увлеченных исследователей и программистов. Гибкий график и никакой бюрократии, решения быстро принимаются и воплощаются в жизнь.
Сейчас мы ищем плюсовиков, питонистов, дата-инженеров и мл-рисерчеров.