http://habrahabr.ru/company/mailru/blog/254727/
На Хабре уже есть статьи о NoSQL СУБД
Tarantool и о том, как его используют в Mail.Ru Group (и не только). Однако нет рецептов того, как работать с Tarantool на Python. В своей статье я хочу рассказать о том, как мы готовим Tarantool Python в своих проектах, какие проблемы и сложности при этом возникают, плюсы, минусы, подводные камни и, конечно же, «в чем фишка». Итак, обо всем по порядку.

Tarantool представляет собой
Application Server для Lua. Он умеет хранить данные на диске, обеспечивает быстрый доступ к ним. Tarantool используется в задачах с большими потоками данных в единицу времени. Если говорить о цифрах, то это десятки и сотни тысяч операций в секунду. Например, в одном из моих проектов генерируется более 80 000 запросов в секунду (выборка, вставка, обновление, удаление), при этом нагрузка равномерно распределяется по 4 серверам с 12 инстансами Tarantool. Не все современные СУБД готовы работать с такими нагрузками. Кроме того, при таком количестве данных, очень дорого ожидание выполнения запроса, поэтому сами программы должны быстро переключаться от одной задачи к другой. Для эффективной и равномерной загрузки CPU сервера (всех его ядер) как раз нужен Tarantool и асинхронные приемы в программировании.
Как работает коннектор tarantool-python?
Прежде чем говорить об асинхронном коде на Python, нужно хорошее понимание того, как обычный синхронный код на Python взаимодействует с Tarantool. Я буду использовать версию Tarantool 1.6 под CentOS, его установка проста и тривиальна и подробно
расписана на сайте проекта, там же можно найти обширный
user guide. Хочу заметить, что в последнее время, с появлением хорошей документации, стало гораздо проще разбираться в запуске и использовании инстанса Tarantool. Ещё на Хабре совсем недавно появилась полезная статья «
Tarantool 1.6 — давай начнем».
Итак, Tarantool установлен, запущен и готов к работе. Для работы с Python 2.7 берём из pypi коннектор
tarantool-python:
$ pip install tarantool-python
Этого пока достаточно для решения наших задач. А какие они? В одном из моих проектов появилась необходимость «сложить» поток данных в Tarantool для дальнейшей их обработки, при этом размер одной пачки данных составляет примерно 1,5 КБайт. Прежде, чем приступать к решению задачи, следует хорошо изучить вопрос и провести испытания выбранных подходов и инструментов. Скрипт для тестирования производительности выглядит элементарно и пишется за пару минут:
import tarantool
import string
mod_len = len(string.printable)
data = [string.printable[it] * 1536
for it in range(mod_len)]
tnt = tarantool.connect("127.0.0.1", 3301)
for it in range(100000):
r = tnt.insert("tester", (it, data[it % mod_len]))
Всё просто: в цикле последовательно делаем 100 тысяч вставок в Tarantool. На моей виртуальной машине этот код выполняется в среднем за 32 секунды, то есть порядка трёх тысяч вставок в секунду. Программа несложная, и если полученной производительности хватает, то можно более ничего не делать, ведь, как известно, «преждевременная оптимизация — зло». Однако для нашего проекта этого оказалось мало, к тому же сам Tarantool может показать гораздо более
лучшие результаты.
Профилируем код
Прежде чем предпринимать необдуманные шаги, попробуем внимательно изучить наш код и то, как он работает. Спасибо моему коллеге
Dreadatour за его цикл статей о
профилировании Python-кода.
Перед запуском профайлера полезно понять, как работает программа, всё-таки лучший инструмент для профилирования — голова разработчика. Сам скрипт прост, изучать там особо нечего, попробуем «копнуть глубже». Если заглянуть в реализацию драйвера коннектора, то можно понять, что запрос упаковывается при помощи библиотеки
msgpack, отправляется в сокет при помощи вызова
sendall, а затем из сокета вычитывается длина ответа и сам ответ. Уже интереснее. Сколько же операций с сокетом Tarantool будет сделано в результате выполнения этого кода? В нашем случае для одного запроса
tnt.insert будет сделан один вызов
socket.sendall (отправили данные) и два вызова
socket.recv (получили длину ответа и сам ответ). Метод «пристального взгляда» говорит, что для вставки ста тысяч записей будет сделано 200k + 100k = 300k read/write системных вызовов. И профайлер (я использовал
cProfile и
kcachegrind для интерпретации результатов) подтверждает наши умозаключения:
Что можно поменять в этой схеме? В первую очередь, конечно, хочется уменьшить количество системных вызовов, то есть операций с сокетом Tarantool. Это можно сделать, сгруппировав запросы
tnt.insert в «пачку», и вызывать
socket.sendall для всех запросов сразу. Точно также можно вычитывать из сокета «пачку» ответов от Tarantool за один
socket.recv. При обычном, классическом стиле программирования это сделать не так просто: нужен буфер для данных, задержка, чтобы накапливать данные в буфер, и еще нужно без задержек по очереди возвращать результаты запросов. А что делать, если запросов было много и вдруг стало очень мало? Снова возникнут задержки, которые мы стремимся избежать. В общем, нужен принципиально новый подход, но самое главное — хочется оставить код исходной задачи таким же простым, каким он и был изначально. На помощь для решения нашей задачи приходят асинхронные фреймворки.
Gevent и Python 2.7
Мне приходилось иметь дело с несколькими асинхронными фреймворками:
twisted,
tornado,
gevent и прочие. На Хабре уже не раз поднимался вопрос сравнения и бенчмарков этих инструментов, например:
раз и
два.
Мой выбор упал на gevent. Основная причина заключается в эффективности работы с I/O-операциями и простоте написания кода. Хороший туториал по использованию этой библиотеки можно найти
здесь. А в
этом туториале есть классический пример быстрого краулера:
import time
import gevent.monkey
gevent.monkey.patch_socket()
import gevent
import urllib2
import json
def fetch(pid):
url = 'http://json-time.appspot.com/time.json'
response = urllib2.urlopen(url)
result = response.read()
json_result = json.loads(result)
return json_result['datetime']
def synchronous():
for i in range(1,10):
fetch(i)
def asynchronous():
threads = []
for i in range(1,10):
threads.append(gevent.spawn(fetch, i))
gevent.joinall(threads)
t1 = time.time()
synchronous()
t2 = time.time()
print('Sync:', t2 - t1)
t1 = time.time()
asynchronous()
t2 = time.time()
print('Async:', t2 - t1)
На моей виртуальной машине для этого теста получились такие результаты:
Sync: 1.529
Async: 0.238
Неплохой прирост производительности! Чтобы заставить работать синхронный код асинхронно с помощью gevent, понадобилось обернуть вызов фукции
fetch в
gevent.spawn, как бы распараллелив скачивание самих URL-ов. Потребовалось также выполнить
monkey.patch_socket(), после чего все вызовы для работы сокетами становятся кооперативными. Таким образом, пока один URL скачивается и программа ждёт ответа от удалённого сервиса, движок gevent переключается на другие задачи и вместо бесполезного ожидания пытается скачивать другие доступные документы. В недрах Python все gevent threads исполняются последовательно, но за счет того, что нет ожиданий (системных вызовов
wait), итоговый результат получается быстрее.
Выглядит неплохо, а самое главное — такой подход очень хорошо подошел и для нашей задачи. Однако драйвер tarantool-python не умеет из коробки работать с gevent, и мне пришлось поверх него написать коннектор gtarantool.
Gevent и Tarantool
Коннектор
gtarantool работает с gevent и Tarantool 1.6 и уже сейчас доступен на pypi:
$ pip install gtarantool
Тем временем, новое решение нашей задачи принимает такой вид:
import gevent
import gtarantool
import string
mod_len = len(string.printable)
data = [string.printable[it] * 1536
for it in range(mod_len)]
cnt = 0
def insert_job(tnt):
global cnt
for i in range(10000):
cnt += 1
tnt.insert("tester", (cnt, data[it % mod_len]))
tnt = gtarantool.connect("127.0.0.1", 3301)
jobs = [gevent.spawn(insert_job, tnt)
for _ in range(10)]
gevent.joinall(jobs)
Что изменилось по сравнению с синхронным кодом? Мы разделили вставку 100k записей между десятью асинхронными «зелеными» потоками, каждый из которых делает в цикле около 10k вызовов
tnt.insert, и все это — через один коннект к Tarantool. Время выполнения программы сократилось до 12 секунд, что почти в 3 раза эффективнее синхронной версии, а количество вставок данных в БД выросло до 8 тысяч в секунду. Почему же такая схема работает быстрее? В чем фишка?
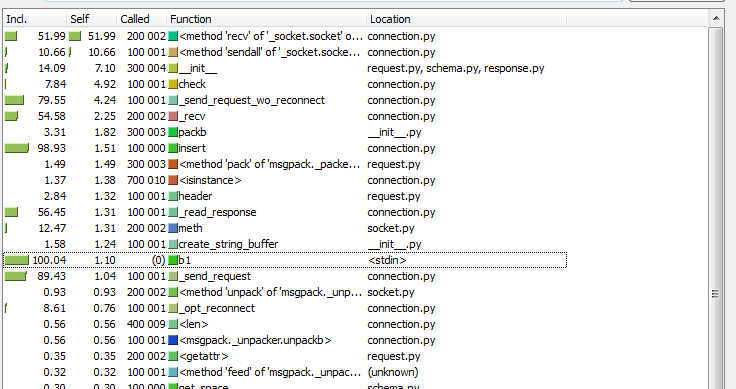
Коннектор gtarantool внутри использует буфер запросов в сокет Tarantool и отдельные «зеленые потоки» чтения/записи в этот сокет. Пробуем посмотреть на результаты в профайлере (на этот раз я использовал
Greenlet Profiler — это адаптированный профайлер yappi для greenlets):
Анализируя результаты в kcachegrind мы видим, что количество вызовов
socket.recv уменьшилось со 100k до 10k, а количество вызовов
socket.send упало с 200k до 2,5k. Собственно, это и делает работу с Tarantool более эффективной: меньше тяжёлых системных вызовов за счёт более лёгких и «дешёвых» гринлетов. А самое главное и приятное то, что код исходной программы остался, фактически, «синхронным». В нём нет никаких уродливых twisted-callbacks.
Этот подход мы успешно используем в своем проекте. В чем еще профит:
- Мы отказались от fork-ов. Можно использовать несколько Python-процессов, а в каждом процессе использовать один коннект gtarantool (или пул соединений).
- Внутри greenlets переключение происходит гораздо быстрее и эффективнее, чем переключение между Unix-процессами.
- Уменьшение количества процессов позволило сильно сократить потребление памяти.
- Уменьшение количества операций с Tarantool-сокетом повысило эффективность работы с самим Tarantool, он стал потреблять меньше CPU.
А что же с Python 3 и Tarantool?
Одно из отличий между различными асинхронными фреймворками — способность работать под Python 3. Например, gevent его не поддерживает. Более того, библиотека tarantool-python тоже не будет работать под Python 3 (ещё не успели портировать). Ну как же так?
Путь джедая тернист. Очень хотелось сравнить асинхронную работу с tarantool из-под второй и третьей версии Python, и тогда я принял решение переписать всё на Python 3.4. После Python 2.7 было немного непривычно писать код:
- не работает print “foo”
- все строки – это объекты класса str
- нет типа long
- …
Но привыкание прошло успешно, и теперь я стараюсь сразу писать код для Python 2.7 так, чтобы он без изменений работал и на Python 3.
Коннектор tarantool-python пришлось немного доработать:
- StandartError заменил на Exception
- basestring заменил на str
- xrange заменил на range
- long — удалил
Получился
форк синхронного коннектора, работающий под Python 3.4. После тщательной проверки этот код, возможно, будет влит в основную ветку библиотеки, а пока установить его можно прямо с Гитхаба:
$ pip install git+https://github.com/shveenkov/tarantool-python.git@for_python3.4
Первые результаты бенчмарков не вызвали восторга. Обычный синхронный вариант вставки 100k записей, размером в 1,5 Кбайт стал выполняться в среднем чуть больше минуты — в два раза дольше, чем такой же код под второй версией Python! На помощь снова приходит профилирование:
Ого! Ну и откуда взялись 400k вызовов
socket.recv? А откуда 200k вызовов
socket.sendall? Пришлось снова погрузиться в код коннектора tarantool-python: как оказалось, это результат работы Python-строк и байт в качестве ключей dict. Для примера можно сравнить такой код:
Python 3.4:
>>> a=dict()
>>> a[b"key"] = 1
>>> a["key"]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 'key'
Python 2.7:
>>> a=dict()
>>> a[b"key"] = 1
>>> a["key"]
1
Подобные мелочи представляют собой яркий пример сложности портирования кода на Python 3, и даже тесты тут не всегда помогают, ведь формально всё работает, однако работает в два раза медленнее, а для наших реалий это существенная разница. Чиним код, добавляем «пару байт» в коннектор (ссылка на изменения в
коде коннектора, а также еще одно
изменение) — есть результат!
Ну что же, теперь неплохо! Синхронный вариант коннектора начал справляться с задачей в среднем за 35 секунд, что чуть медленней Python 2.7, но с этим уже можно жить.
Переходим на asyncio в Python 3
Asyncio – это корутины для Python 3 «из коробки». Есть
документация, есть примеры, есть готовые
библиотеки для asyncio и Python 3. На первый взгляд всё достаточно сложно и запутанно (по крайней мере, по сравнению с gevent), однако при дальнейшем рассмотрении всё становится на свои места. И вот, после некоторых усилий, я написал версию коннектора к Tarantool для asyncio –
aiotarantool.
Этот коннектор так же доступен через pypi:
$ pip install aiotarantool
Хочу отметить, что код нашей исходной задачи на asyncio стал немного сложнее её первоначальной версии. Появились конструкции
yield from, появились декораторы
@asyncio.coroutine, но в целом он мне нравится, а отличий от gevent не так много:
import asyncio
import aiotarantool
import string
mod_len = len(string.printable)
data = [string.printable[it] * 1536
for it in range(mod_len)]
cnt = 0
@asyncio.coroutine
def insert_job(tnt):
global cnt
for it in range(10000):
cnt += 1
args = (cnt, data[it % mod_len])
yield from tnt.insert("tester", args)
loop = asyncio.get_event_loop()
tnt = aiotarantool.connect("127.0.0.1", 3301)
tasks = [asyncio.async(insert_job(tnt))
for _ in range(10)]
loop.run_until_complete(asyncio.wait(tasks))
loop.close()
Этот вариант справляется с задачей, в среднем, за 13 секунд (получается порядка 7,5k вставок в секунду), что чуть медленнее версии на Python 2.7 и gevent, но гораздо лучше всех синхронных версий. В aiotarantool есть одно небольшое, но очень важное отличие от других библиотек, доступных на
asyncio.org: вызов
tarantool.connect делается вне
asyncio.event_loop. На самом деле этот вызов не создает настоящего коннекта: он будет сделан позже, внутри одной из корутин при первом вызове
yield from tnt.insert. Такой подход мне показался проще и удобнее при программировании на asyncio.
По традиции, результаты профилирования (я использовал
yappi профайлер, но есть подозрение, что он не совсем правильно считает количество вызовов функций при работе с asyncio):
В результате мы видим 5k вызовов
StreamReader.feed_data и
StreamWriter.write, что, несомненно, гораздо лучше, чем 200k вызовов
socket.recv и 100k вызовов
socket.sendall в синхронном варианте.
Сравнение подходов
Привожу результаты сравнения рассмотренных вариантов работы с Tarantool. Код бенчмарков можно найти в каталоге tests библиотек
gtarantool и
aiotrantool. В бенчмарке выполняется вставка, поиск, изменение и удаление 100 000 записей размером 1,5 Кбайт. Каждый тест запускался десять раз, в таблицах приведено среднее округлённое значение, поскольку важны не точные цифры (они зависят от конкретного железа), а их соотношение.
Сравниваются:
- синхронный tarantool-python под Python 2.7;
- синхронный tarantool-python под Python 3.4;
- асинхронный вариант с gtarantool под Python 2.7;
- асинхронный вариант с aiotarantool под Python 3.4.
Время выполнения теста, в секундах (меньше — лучше):
Операция
(100k записей) |
tarantool-python
2.7 |
tarantool-python
3.4 |
gtarantool
(gevent) |
aiotarantool
(asyncio) |
|---|
| insert |
34 |
38 |
11 |
13 |
|---|
| select |
23 |
23 |
10 |
13 |
|---|
| update |
34 |
33 |
10 |
14 |
|---|
| delete |
35 |
35 |
10 |
13 |
|---|
Количество операций в секунду (больше — лучше):
Операция
(100k записей) |
tarantool-python
2.7 |
tarantool-python
3.4 |
gtarantool
(gevent) |
aiotarantool
(asyncio) |
|---|
| insert |
3000 |
2600 |
9100 |
7700 |
|---|
| select |
4300 |
4300 |
10000 |
7700 |
|---|
| update |
2900 |
3000 |
10000 |
7100 |
|---|
| delete |
2900 |
2900 |
10000 |
7700 |
|---|
Производительность gtarantool немного лучше, чем у aiotarantool. Мы используем gtarantool уже давно, это проверенное решение на больших нагрузках, однако gevent не поддерживается в Python 3. Кроме того, следует помнить, что gevent — сторонняя библиотека, требующая компиляции при установке. Asyncio привлекает своей скоростью и новизной, она идёт в Python 3 «из коробки», и в ней отсутствуют «костыли» в виде «monkey.patch». Но под реальной нагрузкой aiotarantool в нашем проекте пока ещё не работал. Всё впереди!
Выжимаем из сервера максимум
Для максимально эффективного использования ресурсов нашего сервера попробуем немного усложнить код нашего бенчмарка. Сделаем одновременное удаление, вставку, изменение и выборку данных (достаточно распространённый профиль нагрузки) в одном Python-процессе, а самих таких процессов создадим несколько, скажем, 22 (магическое число). Если всего ядер на машине 24, то одно ядро оставим системе (на всякий случай), одно ядро отдаем на откуп Tarantool (ему хватит!), а оставшиеся 22 забираем под процессы Python. Сравнение будем делать и на gevent, и на asyncio, код бенчмарков можно найти
здесь для gtarantool, и
здесь для aiotarantool.
Очень важно наглядно и красиво отобразить результаты для последующего их сравнения. Самое время оценить возможности новой версии Tarantool 1.6: фактически он является интерпретатором Lua, а это значит, что мы можем запускать абсолютно любой код Lua прямо в базе. Пишем простейшую программу, и наш Tarantool уже умеет отправлять любую свою статистику в
graphite. Добавляем код в наш init-скрипт запуска Tarantool (в реальном проекте, конечно, такие вещи лучше выносить в отдельный модуль):
fiber = require('fiber')
socket = require('socket')
log = require('log')
local host = '127.0.0.1'
local port = 2003
fstat = function()
local sock = socket('AF_INET', 'SOCK_DGRAM', 'udp')
while true do
local ts = tostring(math.floor(fiber.time()))
info = {
insert = box.stat.INSERT.rps,
select = box.stat.SELECT.rps,
update = box.stat.UPDATE.rps,
delete = box.stat.DELETE.rps
}
for k, v in pairs(info) do
metric = 'tnt.' .. k .. ' ' .. tostring(v) .. ' ' .. ts
sock:sendto(host, port, metric)
end
fiber.sleep(1)
log.info('send stat to graphite ' .. ts)
end
end
fiber.create(fstat)
Запускаем Tarantool и автоматически получаем графики со статистикой. Круто? Мне очень понравилась эта фича!
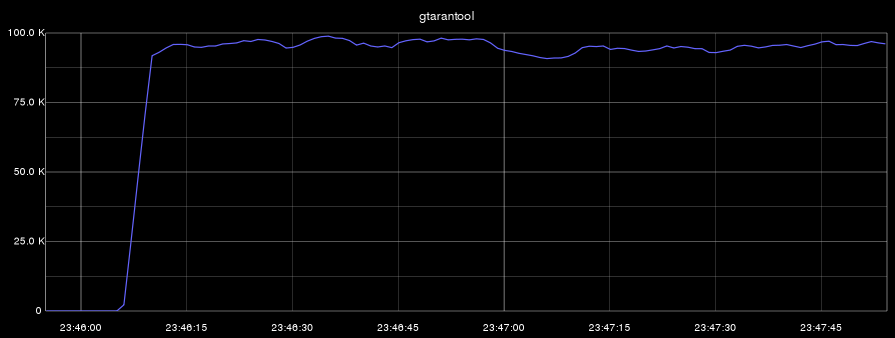
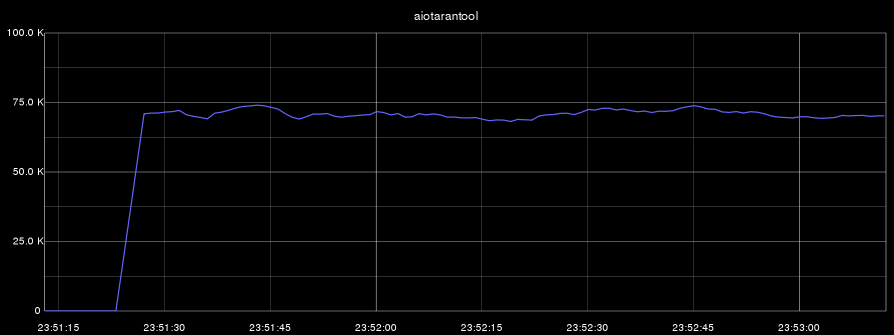
Теперь проведем два бенчмарка: в первом будем выполнять одновременное удаление, вставку, изменение и выборку данных. Во втором бенчмарке будем выполнять только выборку. На всех графиках по оси абсцисс — время, а по оси ординат — количество операций в секунду:
- gtarantool (insert, select, update, delete):
- aiotarantool (insert, select, update, delete):
- gtarantool (select only):
- aiotarantool (select only):
Напомню, что процесс Tarantool использовал только одно ядро. В первом бенчмарке загрузка CPU (этого ядра) при этом составляла 100%, а во втором тесте процесс Tarantool утилизировал своё ядро только на 60%.
Полученные результаты позволяют нам сделать вывод о том, что рассмотренные в статье приёмы подходят для работы с большими нагрузками в наших проектах.
Выводы
Примеры в статье носят, конечно, искусственный характер. Настоящие задачи немного сложнее и разнообразнее, но их решения в общем случае выглядят именно так, как показано в приведённом коде. Где можно применить такой подход? Там, где требуется «много-много, очень много запросов в секунду»: в этом случае для эффективной работы с Tarantool понадобится асинхронный код. Корутины эффективны там, где есть ожидание событий (системных вызовов), и классический пример такой задачи — краулер.
Писать код на asyncio или gevent не так сложно, как кажется, но обязательно нужно уделять много внимания профилированию кода: часто асинхронный код работает вовсе не так, как ожидалось.
Tarantool и его протокол очень хорошо подходят для работы с асинхронным стилем разработки. Стоит только погрузиться в мир Tarantool и Lua, и можно бесконечно удивляться их мощным возможностям. Код на Python может эффективно работать с Tarantool, а в Python 3 заложен хороший потенциал для разработки на корутинах asyncio.
Надеюсь, что материал этой статьи принесет пользу сообществу и пополнит базу знаний о Tarantool и об асинхронном программировании. Думаю, что asyncio и aiotarantool дойдут до использования в продакшен и в наших проектах, и мне будет чем ещё поделиться с читателями Хабра.
Ccылки, которые использовались при написании статьи:
Ну и, конечно, версии коннекторов для Tarantool:
Самое время попробовать их у себя в деле!