https://habrahabr.ru/company/ruvds/blog/332194/- JavaScript
- Блог компании RUVDS.com
→ ArrayBuffer и SharedArrayBuffer в JavaScript, часть 1: краткий курс по управлению памятью
→ ArrayBuffer и SharedArrayBuffer в JavaScript, часть 2: знакомство с новыми объектами языка
→ ArrayBuffer и SharedArrayBuffer в JavaScript, часть 3: гонки потоков и Atomics

В
прошлый раз, рассматривая SharedArrayBuffer, мы говорили о том, что работа с этим объектом может привести к состоянию гонки потоков. Это усложняет разработку, поэтому мы ожидаем, что этим средством будут пользоваться создатели библиотек, имеющие опыт в многопоточном программировании. Они смогут применить новые низкоуровневые API для создания высокоуровневых инструментов, с которыми будут работать обычные программисты, не касаясь ни SharedArrayBuffer, ни Atomics.
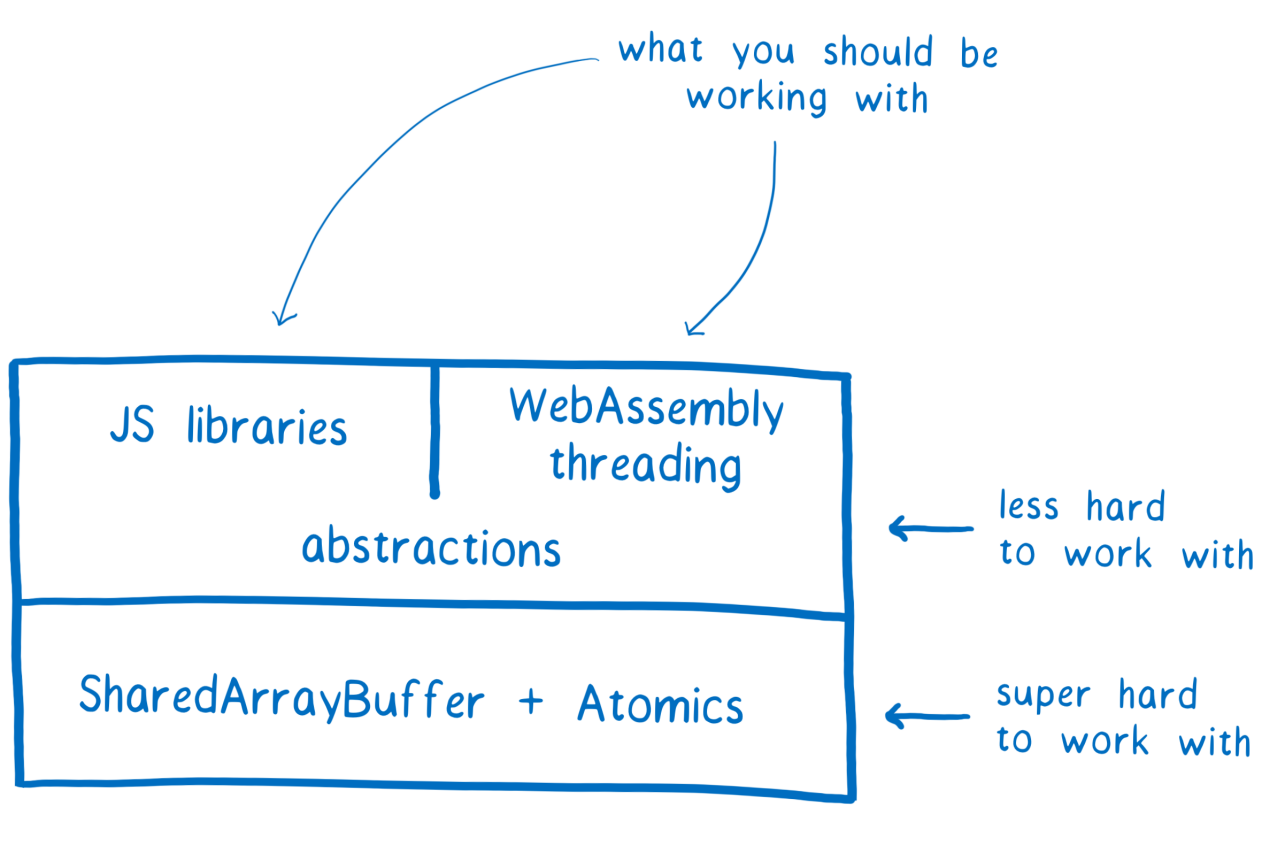 SharedArrayBuffer и Atomics как основа реализации многопоточности в JS-библиотеках и WebAssembly
SharedArrayBuffer и Atomics как основа реализации многопоточности в JS-библиотеках и WebAssembly
Если вы не относитесь к разработчикам библиотек, то, вероятнее всего, работать напрямую с Atomics и SharedArrayBuffer вам не следует. Однако, полагаем, вам будет интересно узнать, как всё это устроено. Поэтому в данном материале мы поговорим о состояниях гонок потоков, которые могут возникать при многопоточном программировании, и о том, как использование объекта Atomics поможет библиотекам, основанным на новых средствах JS, этих состояний избежать.
Начнём с более подробного разговора о том, что же такое гонка потоков.
Гонка потоков: классический пример
Состояние гонки потоков может возникнуть в ситуации, когда имеется переменная, доступ к которой есть у двух потоков. Предположим, первый поток, основываясь на значении переменной
fileExists, загружает некий файл, а второй проверяет, существует ли файл, и, если это так, устанавливает эту переменную в значение
true. В детали мы не вдаёмся, код проверки наличия файла опущен.
Изначально переменная, которую процессы используют для обмена данными, установлена в значение
false.
 Первый поток, слева, загружает файл, если переменная fileExists установлена в true, второй поток, после проверки существования файла, устанавливает эту переменную в true
Первый поток, слева, загружает файл, если переменная fileExists установлена в true, второй поток, после проверки существования файла, устанавливает эту переменную в true
Если код во втором потоке будет выполнен первым, установит переменную в true, первый поток загрузит файл.
 Сначала второй поток устанавливает переменную в значение true, потом второй поток загружает файл
Сначала второй поток устанавливает переменную в значение true, потом второй поток загружает файл
Однако, если код в первом потоке выполнится первым, он выведет сообщение об ошибке, содержащее сведения о том, что файл не существует.
 Если сначала, когда переменная ещё установлена в false, выполняется код в первом потоке, выводится сообщение об ошибке
Если сначала, когда переменная ещё установлена в false, выполняется код в первом потоке, выводится сообщение об ошибке
На самом же деле проблема заключается не в том, что файл найти не удалось. В нашем, весьма упрощённом случае, настоящая причина сообщения об ошибке — состояние гонки потоков.
Многие JS-разработчики сталкиваются с состоянием гонки такого рода даже в однопоточном коде. И, на самом деле, не нужно ничего знать о многопоточности для того, чтобы увидеть, почему возникают подобные ошибки.
Однако, существуют некоторые виды гонок потоков, которые невозможны в однопоточном коде, но могут возникать при разработке многопоточных программ, потоки которых пользуются общей памятью.
Различные виды гонок потоков и Atomics
Поговорим о различных видах гонок потоков, с которыми можно столкнуться в многопоточном коде, и о том, как Atomics может помочь их предотвратить. Надо отметить, что тут мы не стремимся рассмотреть абсолютно все возможные состояния гонок, но этот обзор поможет вам понять, зачем те или иные методы предусмотрены в API Atomics.
Прежде чем мы начнём, хотелось бы снова напомнить, обращаясь к обычным разработчикам, что не ожидается, что они будут напрямую использовать возможности Atomics. Многопоточная разработка отличается повышенной сложностью, мы полагаем, что новыми средствами JavaScript будут, в основном, пользоваться создатели библиотек.
 Многопоточное программирование таит в себе множество опасностей
Многопоточное программирование таит в себе множество опасностей
Теперь приступим к рассказу о состояниях гонок.
Гонка потоков при обработке отдельной операции
Предположим, имеется два потока, которые инкрементируют одну и ту же переменную. На первый взгляд может показаться, что ничего опасного тут нет, что результат нескольких подобных операций будет одним и тем же, вне зависимости от того, какой поток выполнит увеличение переменной первым.
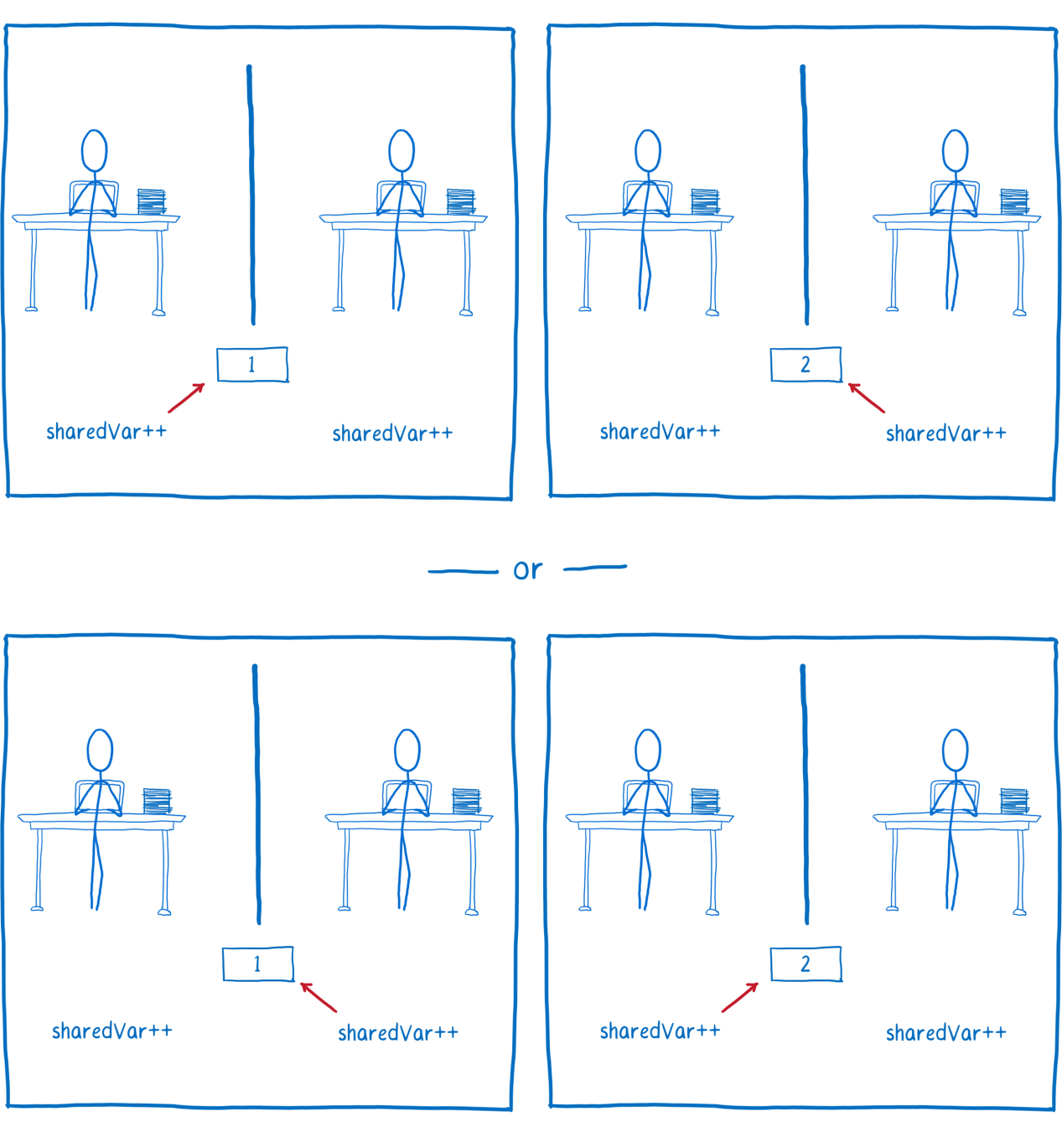 Два потока поочерёдно инкрементируют переменную
Два потока поочерёдно инкрементируют переменную
Хотя, в JS-программе, инкрементирование выглядит как одна операция, если взглянуть на скомпилированный код, окажется, что перед нами несколько операций. Процессору, для инкрементирования переменной, надо выполнить три операции.
Дело тут в том, что у компьютера имеются разные виды памяти. В данном случае речь идёт об обычной оперативной памяти, которая хранит данные сравнительно длительное время, и о регистрах процессора, которые используются для кратковременного хранения данных.
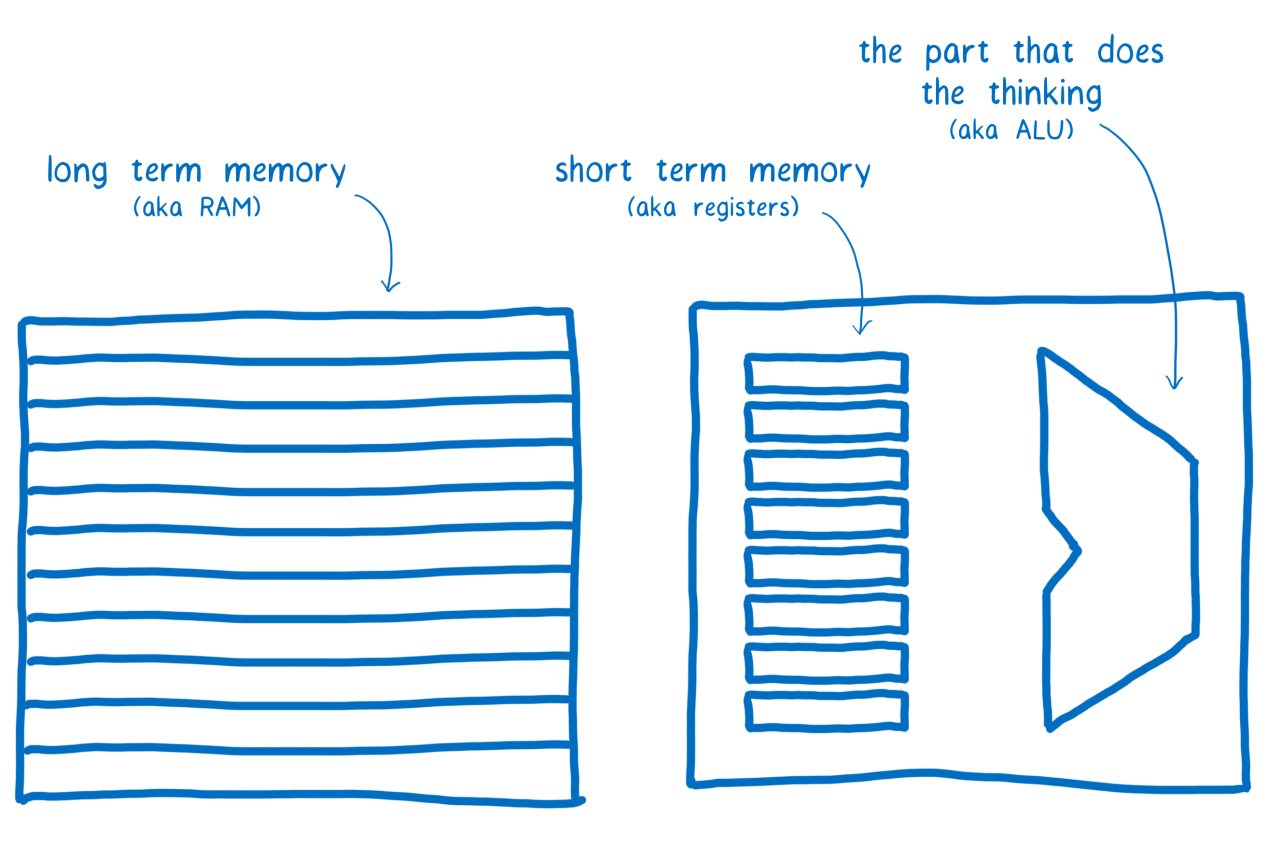 Оперативная память, регистры процессора и арифметико-логическое устройство
Оперативная память, регистры процессора и арифметико-логическое устройство
Наши два потока обладают общей оперативной памятью, но не регистрами процессора. Каждому потоку, для выполнения неких действий с данными, нужно сначала перенести их из оперативной памяти в регистры. Затем — выполнить вычисления, а уже после этого — вернуть данные обратно в оперативную память.
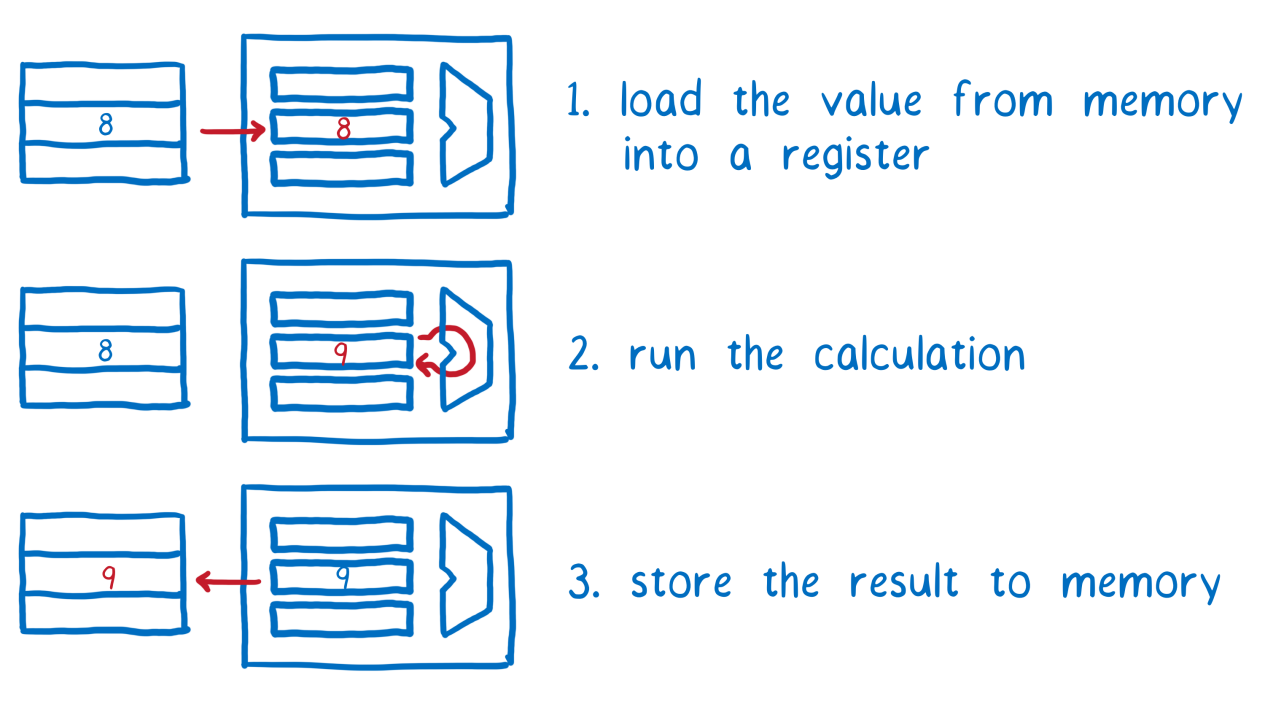 Выполнение действий с данными, хранящимися в оперативной памяти. Первый шаг — загрузка данных из памяти в регистр. Второй — выполнение вычислений. Третий — сохранение результата вычислений в оперативной памяти
Выполнение действий с данными, хранящимися в оперативной памяти. Первый шаг — загрузка данных из памяти в регистр. Второй — выполнение вычислений. Третий — сохранение результата вычислений в оперативной памяти
Если все необходимые низкоуровневые операции сначала выполнит первый поток, а затем — второй, мы получим ожидаемый результат.
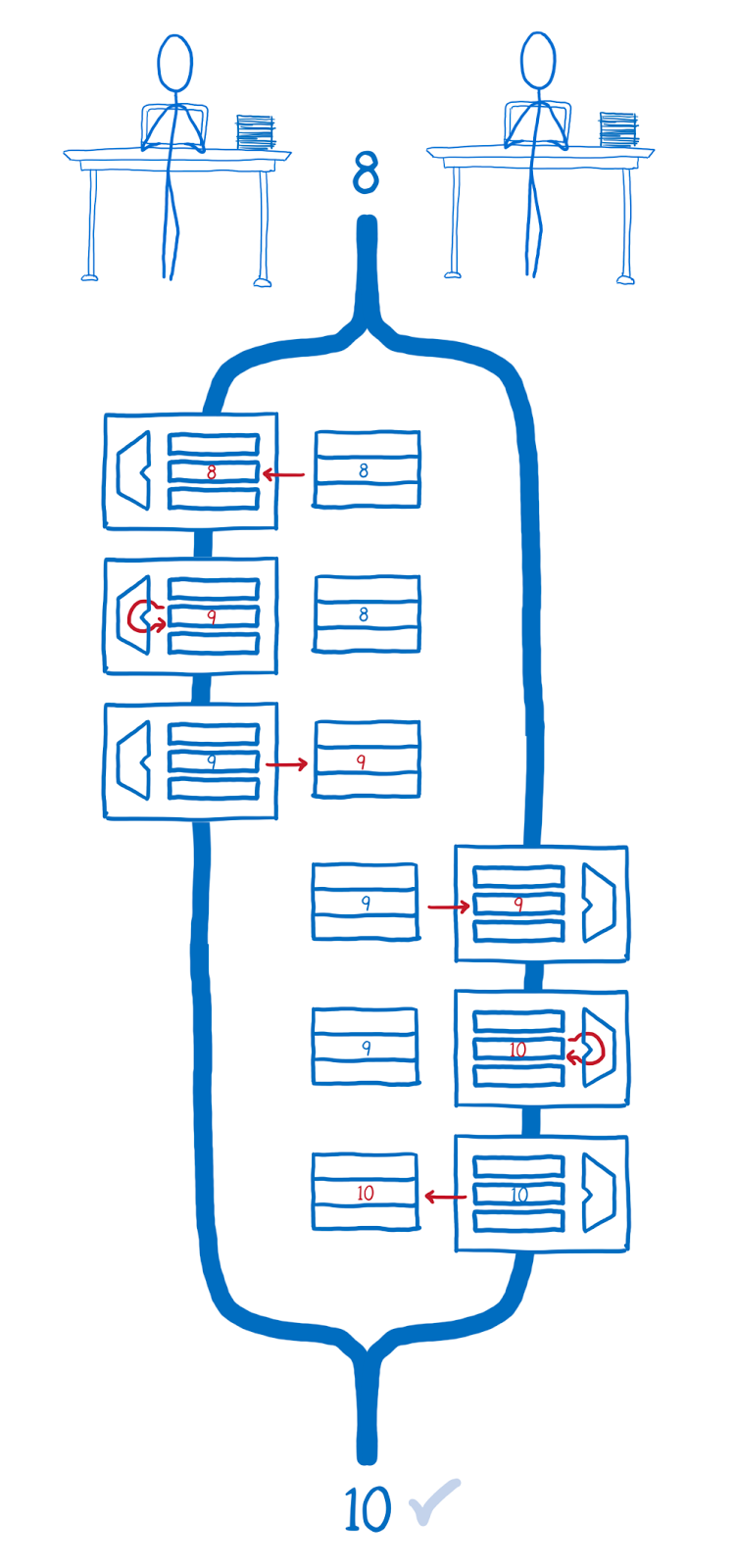 Сначала все операции по инкрементированию переменной выполняет первый поток, потом — второй
Сначала все операции по инкрементированию переменной выполняет первый поток, потом — второй
Но что, если операции, в которые вовлечены регистры, будут выполнены так, что одна из них начнётся до того, как окончится другая? Это приведёт к нарушению синхронизации состояния регистров и оперативной памяти. Например, может случиться так, что один из потоков не примет во внимание результаты вычислений другого и затрёт своими данными то, что он записал в память.
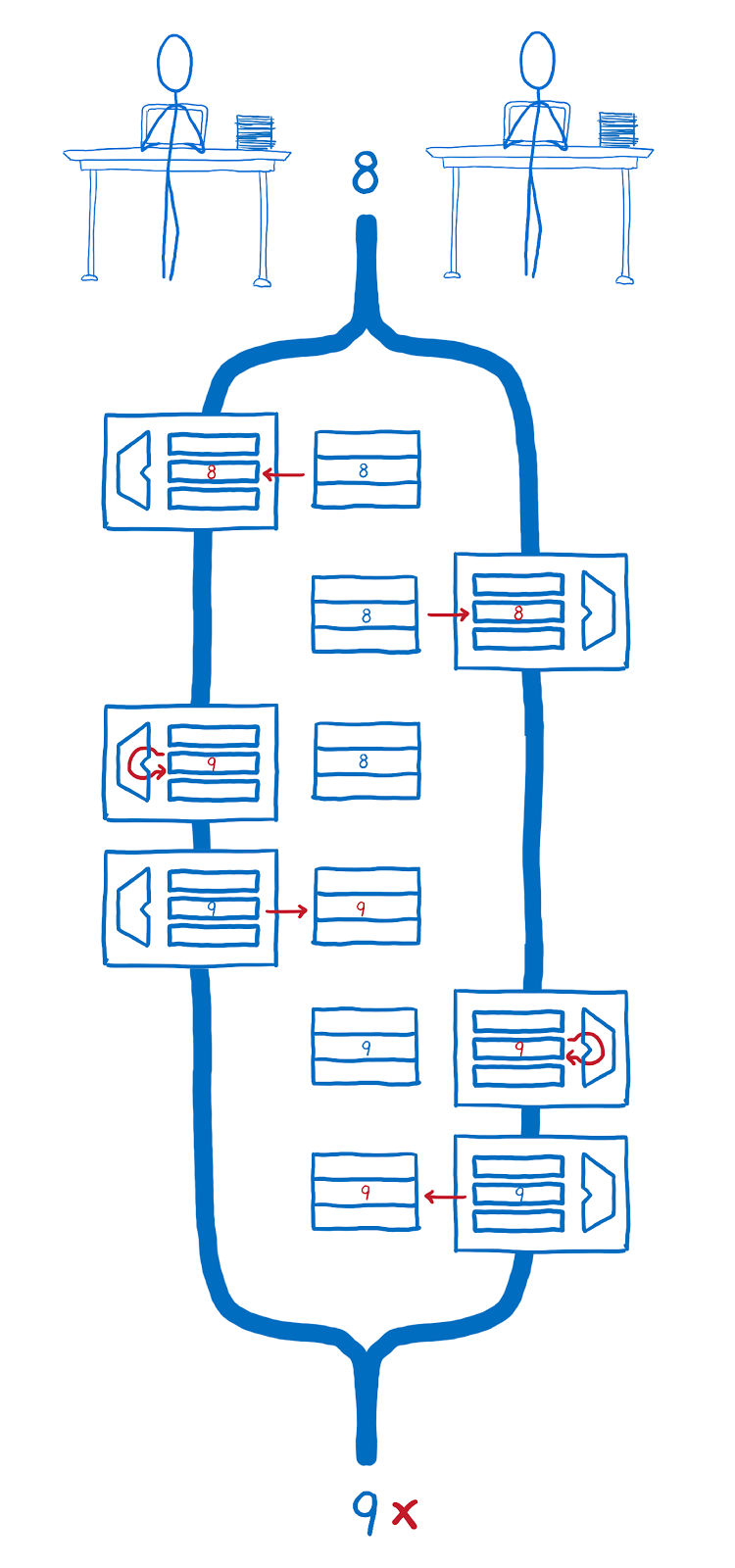 Гонка потоков и операции с регистрами
Гонка потоков и операции с регистрами
Избежать подобных ситуаций можно с помощью реализации так называемых «атомарных операций». Суть тут заключается в том, чтобы то, что для программиста выглядит как одна операция, а для компьютера — как несколько, выглядело бы как одна операция и для компьютера.
Атомарные операции позволяют превратить некие действия, которые могут включать в себя множество инструкций процессора, в нечто вроде единой неделимой инструкции. Эта атомарная «инструкция» сохраняет целостность даже если выполнение команд, из которых она состоит, приостанавливается, и, через некоторое время, возобновляется. Атомарные операции иногда сравнивают с атомами.
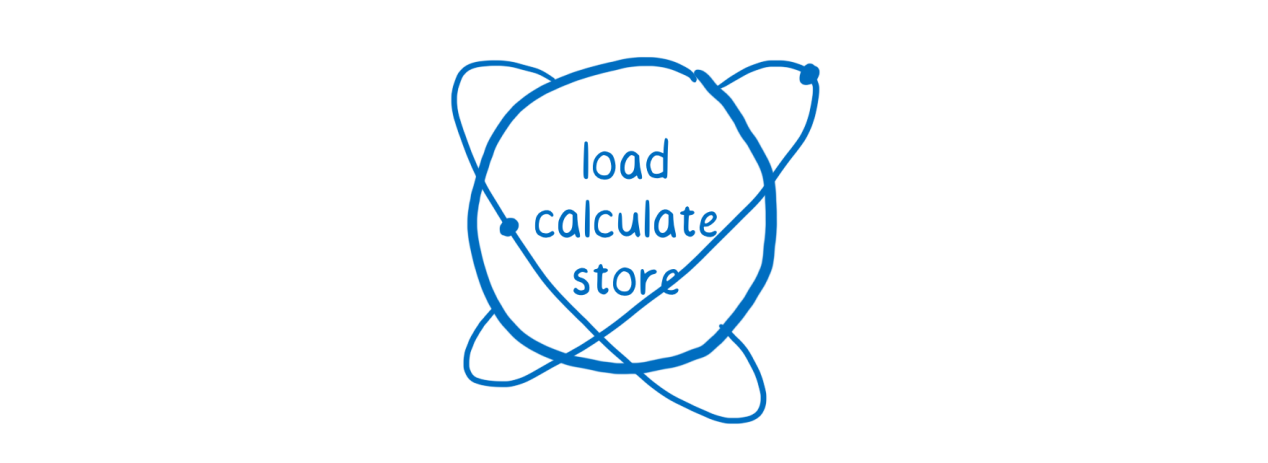 Набор инструкций, формирующих атомарную операцию
Набор инструкций, формирующих атомарную операцию
С использованием атомарных операций код для инкрементирования переменной будет выглядеть по-новому. Вместо обычного
sharedVar++ это будет нечто вроде
Atomics.add(sabView, index, 1). Первый аргумент метода
add представляет собой структуру данных для доступа к
SharedArrayBuffer (
Int8Array, например). Второй — это индекс, по которому
sharedVar находится в массиве. Третий аргумент — число, которое нужно прибавить к
sharedVar.
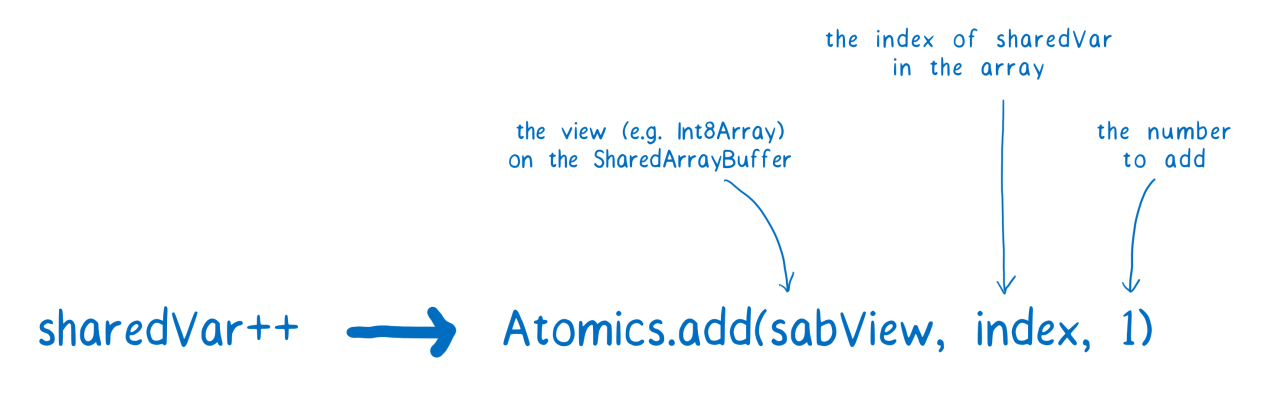 Атомарная операция, которая позволяет увеличить переменную на 1
Атомарная операция, которая позволяет увеличить переменную на 1
Теперь, когда мы пользуемся методом
Atomics.add, действия процессора, связанные с инкрементированием переменной по команде из одного потока, не смешиваются с операциями, инициированными из другого потока. Вместо этого сначала все необходимые действия, в рамках одной атомарной операции, выполняются первым потоком, после чего выполняются операции второго потока, опять же, заключённые в атомарную операцию.
 Сначала инструкции, необходимые для инкрементирования переменной, выполняет первый поток, затем — второй
Сначала инструкции, необходимые для инкрементирования переменной, выполняет первый поток, затем — второй
Вот методы Atomics, которые помогают избежать состояния гонок при выполнении отдельных операций.
Можно заметить, что список этот довольно-таки ограниченный. В нём, например, нет методов для выполнения деления или умножения. Однако, разработчики вспомогательных библиотек могут самостоятельно реализовать атомарные методы для выполнения различных операций.
Для реализации подобных вещей можно воспользоваться методом
Atomics.compareExchange. С помощью этого метода можно считать некое значение из SharedArrayBuffer, выполнить с ним какие-то действия и записать обратно только в том случае, если оно, во время выполнения действий с ним, не было изменено другим потоком. Если, при попытке записи, оказалось, что значение в SharedArrayBuffer изменилось, запись не выполняется, вместо этого можно взять новое значение и попытаться выполнить ту же операцию снова.
Состояние гонок при выполнении нескольких операций
Атомарные операции, о которых мы говорили выше, позволяют избежать состояния гонок при выполнении одиночных команд. Однако иногда нужно изменить несколько значений в объекте (с использованием нескольких операций) и быть при этом уверенным в том, что никто другой не попытается в то же самое время менять эти значения. В целом, это означает, что, в ходе каждого сеанса обновления состояния объекта, объект должен быть заблокирован и недоступен для других потоков.
Объект Atomics не предоставляет средств, которые позволяют напрямую реализовать подобный функционал, но он даёт инструменты, которые разработчики библиотек могут использовать для создания механизмов, позволяющих выполнять подобные операции. Речь идёт о создании высокоуровневых средств блокировки.
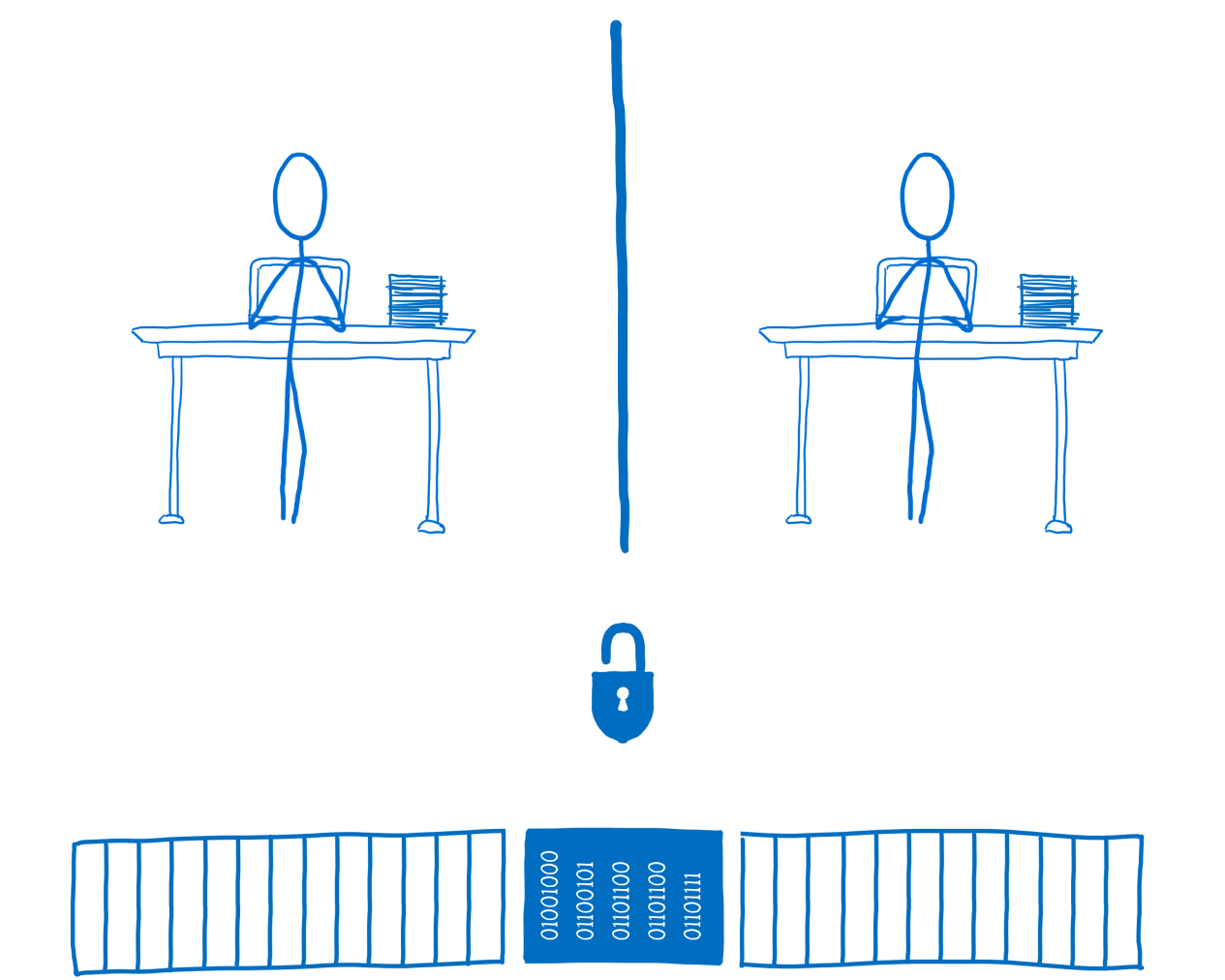 Два потока, общая область памяти и блокировка
Два потока, общая область памяти и блокировка
Если код хочет использовать общие данные, он должен захватить блокировку. На рисунке выше ни один из потоков не заблокировал общую область памяти, это представлено в виде открытого замка. После захвата поток может использовать блокировку для защиты данных от других потоков. Только он может получить доступ к этим данным или изменить их, пока блокировка активна.
Для того, чтобы создать механизм блокировок, авторы библиотек могут воспользоваться методами
Atomics.wait, и
Atomics.wake, а так же такими, как
Atomics.compareExchange и
Atomics.store.
Здесь можно взглянуть на базовую реализацию подобного механизма.
При таком подходе, показанном на следующем рисунке, поток №2 захватит блокировку данных и установит значение
locked в
true. Это означает, что поток №1 не сможет получить доступ к данным до тех пор, пока поток №2 их не разблокирует.
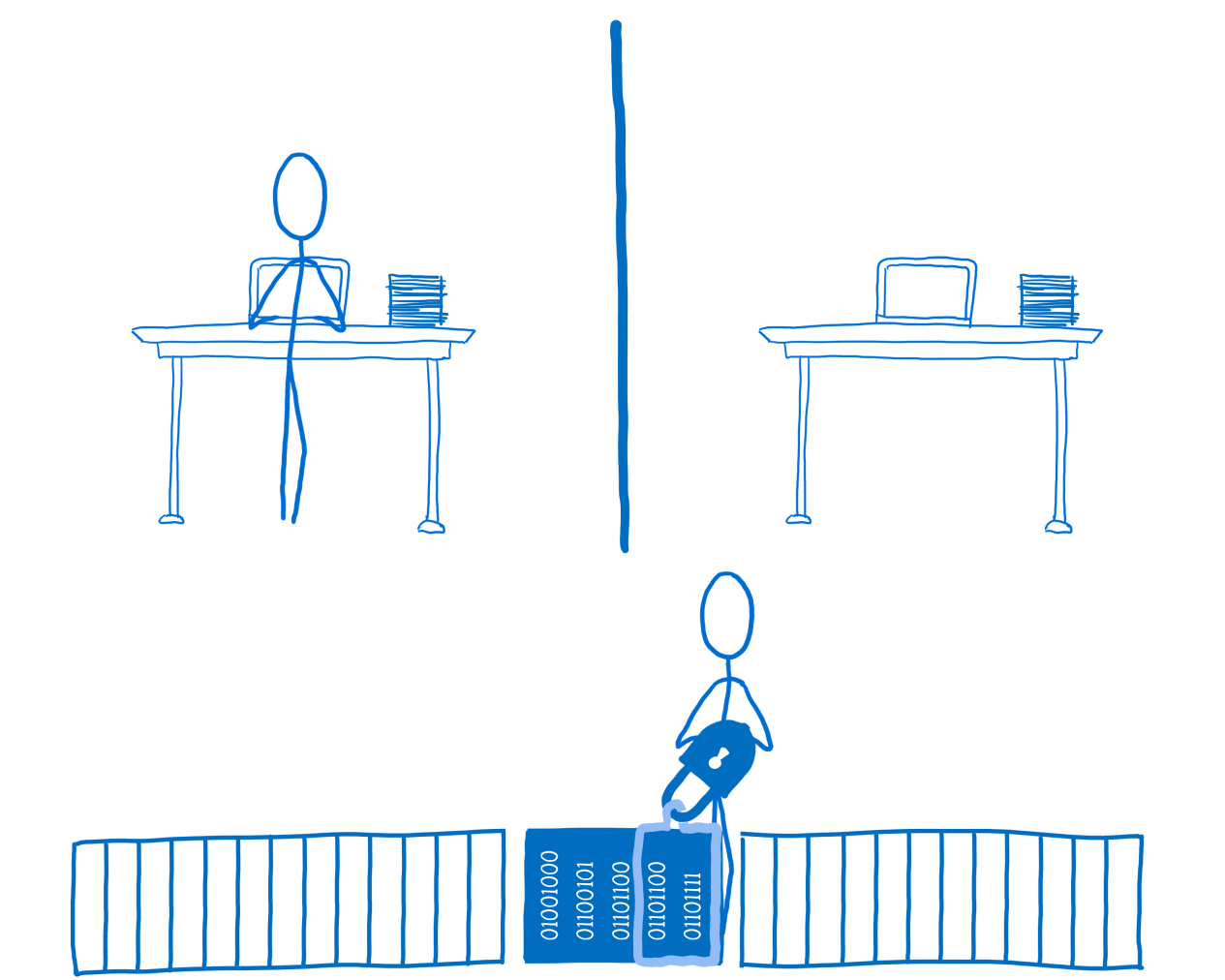 Поток №2 блокирует данные
Поток №2 блокирует данные
Если потоку №1 нужен доступ к данным, он попытается захватить блокировку. Но так как блокировка уже используется, сделать он этого не сможет. Поэтому потоку придётся ждать до тех пор, пока данные не окажутся разблокированными.
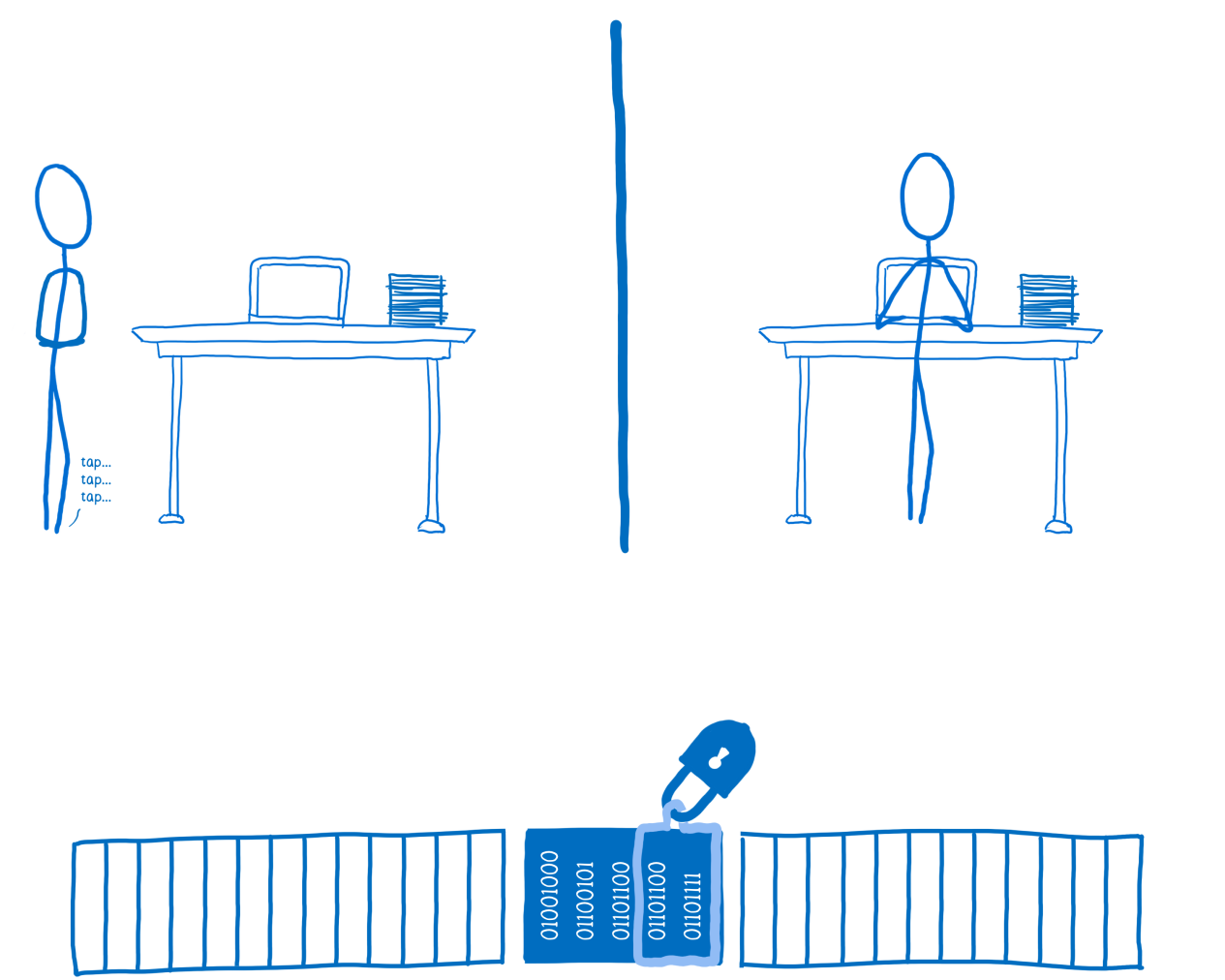 Поток №1 ожидает снятия блокировки
Поток №1 ожидает снятия блокировки
Как только поток №2 завершит работу, он снимет блокировку. После этого механизм блокировок оповестит ожидающие потоки о том, что они могут захватить блокировку.
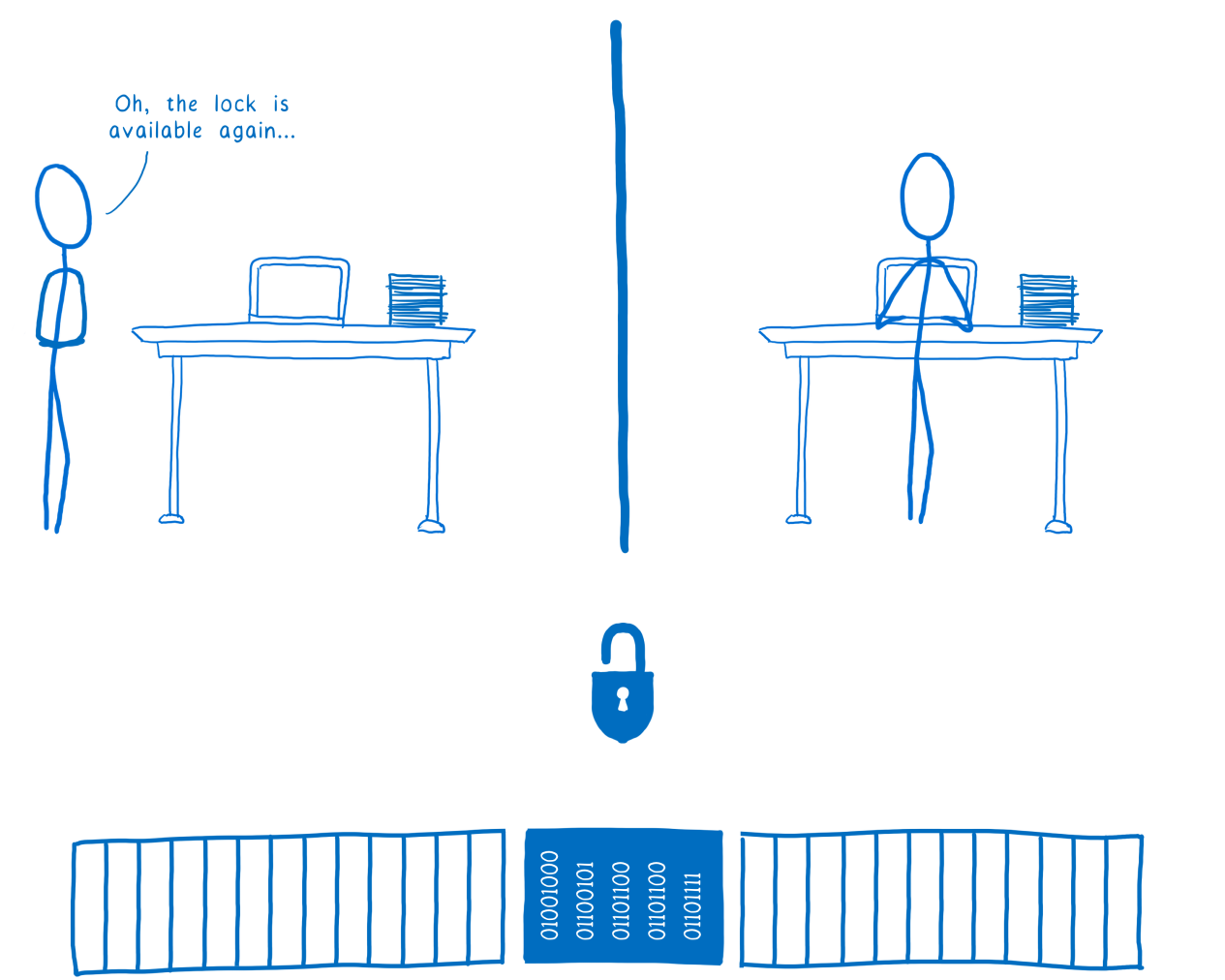 Поток №1 получил оповещение о том, что блокировка снята
Поток №1 получил оповещение о том, что блокировка снята
Теперь поток №1 может захватить блокировку и заблокировать данные для собственного использования.
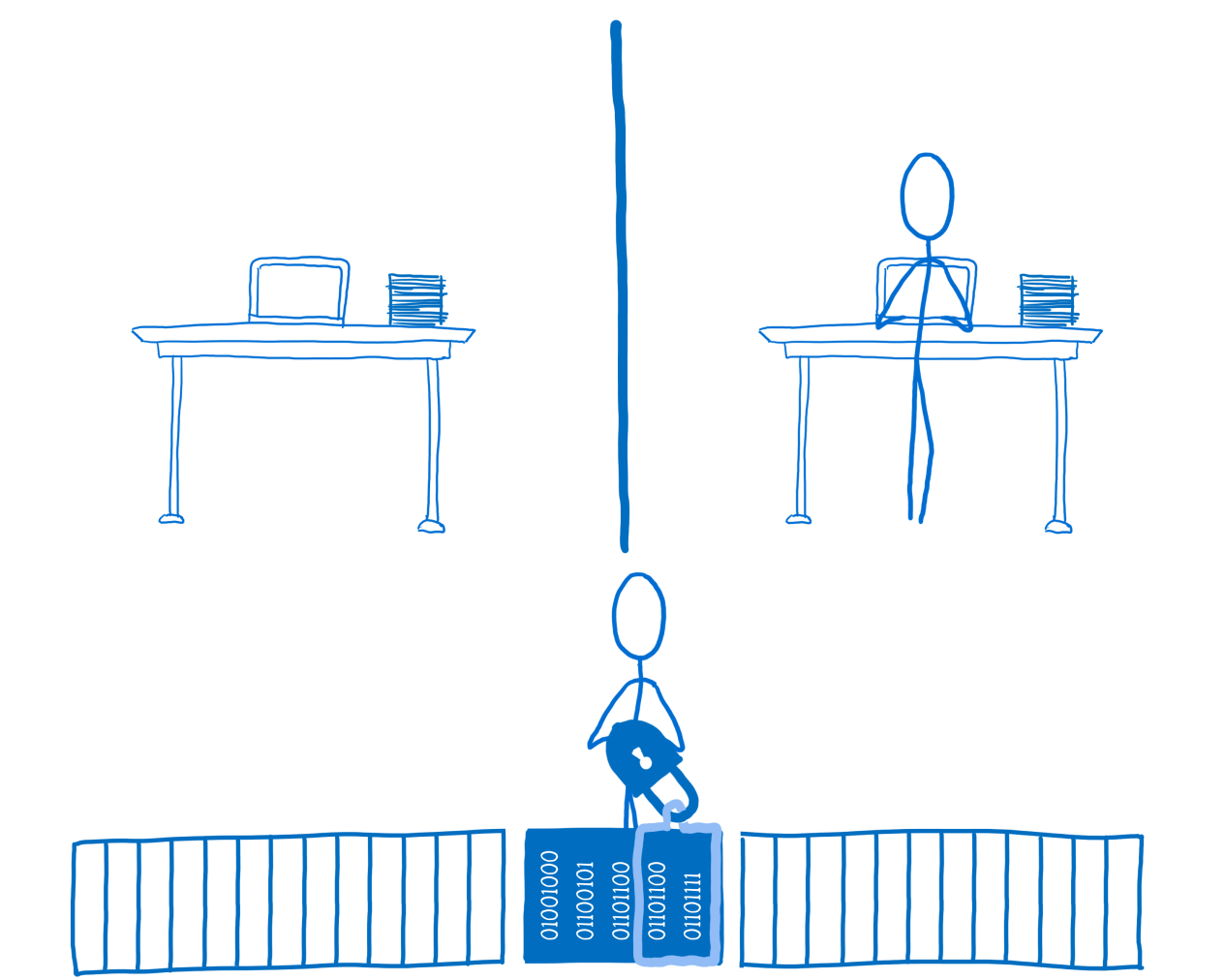 Поток №1 блокирует данные
Поток №1 блокирует данные
Библиотека, реализующая механизм блокировок, могла бы использовать различные методы объекта Atomics, однако, самыми важными из них являются
Atomics.wait и
Atomics.wake.
Состояние гонок, вызванное изменением порядка выполнения операций
Вот третья проблема синхронизации, в решении которой может помочь объект Atomics. Для кого-то она может оказаться полной неожиданностью.
Возможно, вы этого не знаете, но весьма велики шансы того, что команды программы, написанной вами, не будут выполняться в том порядке, в котором они идут в коде. И компиляторы, и процессор, меняют порядок выполнения кода для того, чтобы более рационально использовать ресурсы компьютера.
Например, предположим, что была написана некая функция, код которой вычисляет общую сумму по чеку. Завершив вычисления, мы устанавливаем соответствующий флаг.
 Фрагмент кода, выполняющего вычисления общей суммы и устанавливающего флаг, сигнализирующий об окончании выполнения операции
Фрагмент кода, выполняющего вычисления общей суммы и устанавливающего флаг, сигнализирующий об окончании выполнения операции
Для того, чтобы это скомпилировать, системе надо решить, какой регистр использовать для каждой переменной. После этого JS-код можно перевести в машинные инструкции.
 Упрощённый пример преобразования кода на JS в машинные инструкции
Упрощённый пример преобразования кода на JS в машинные инструкции
Пока всё выглядит так, как и ожидается.
Для тех, кто не очень хорошо разбирается в том, как компьютер работает на аппаратном уровне, как устроены конвейеры, которые используются для выполнения кода, может оказаться не вполне очевидным тот факт, что перед выполнением второй строки нашего кода, машине придётся немного подождать.
Большинство компьютеров разбивает процесс выполнения инструкций на несколько шагов. Это позволяет обеспечить постоянную загрузку всех механизмов процессора, что даёт возможность эффективно пользоваться ресурсами машины.
Вот описание этапов, из которых состоит выполнение инструкции.
Этап №1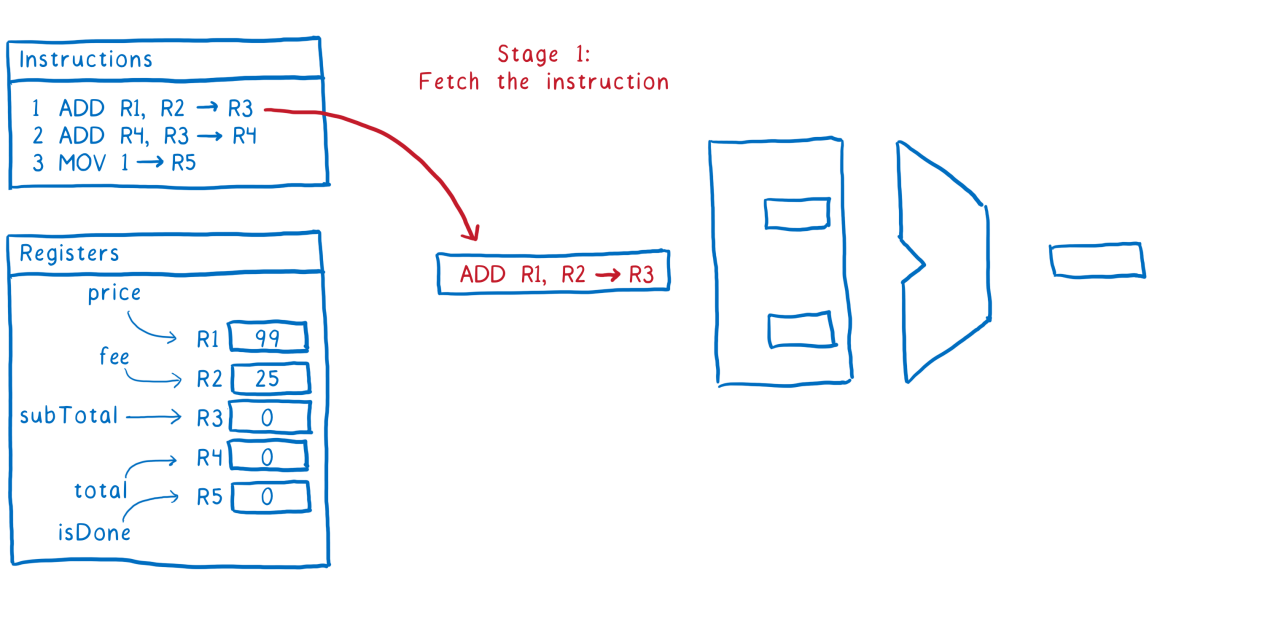 Выборка инструкции из памятиЭтап №2
Выборка инструкции из памятиЭтап №2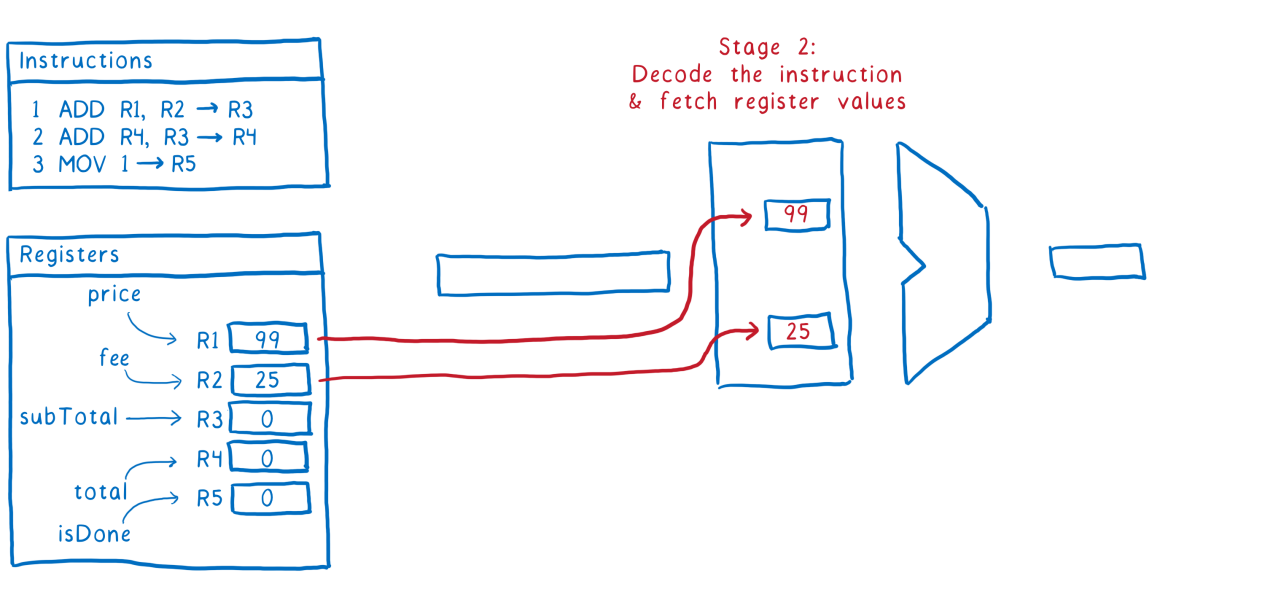 Декодирование инструкции, то есть, выяснение, какие именно действия нужно произвести для выполнения этой инструкции, и загрузка необходимых данных из регистровЭтап №3
Декодирование инструкции, то есть, выяснение, какие именно действия нужно произвести для выполнения этой инструкции, и загрузка необходимых данных из регистровЭтап №3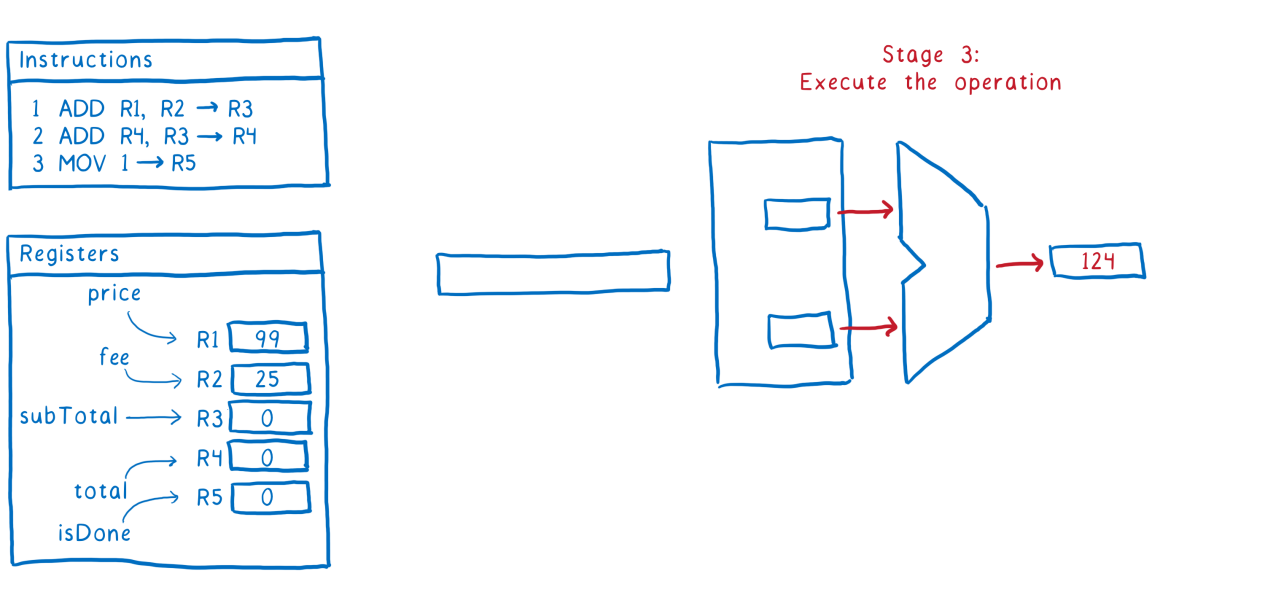 Выполнение инструкцииЭтап №4
Выполнение инструкцииЭтап №4 Запись результатов выполнения инструкции в регистры
Запись результатов выполнения инструкции в регистры
Вот, очень упрощённо, путь, который проходит по конвейеру первая инструкция. В идеале нам хотелось бы, чтобы выполнение второй инструкции шло сразу за первой. То есть, как только первая инструкция переходит к шагу №2, осуществляется выполнение шага №1 для второй инструкции, и так далее.
Проблема заключается в том, что инструкция №2 зависит от инструкции №1.
 Инструкции №2 нужно получить значение переменной subTotal из R3, но инструкция №1 ещё не записала туда результат вычислений
Инструкции №2 нужно получить значение переменной subTotal из R3, но инструкция №1 ещё не записала туда результат вычислений
В подобной ситуации можно приостановить обработку процессором инструкций до тех пор, пока инструкция №1 не обновит значение переменной
subTotal в регистре. Однако, при таком подходе пострадает производительность.
Для того, чтобы использовать ресурсы системы эффективно, множество компиляторов и процессоры меняют порядок выполнения операций. А именно, в нашем случае выполняется поиск инструкций, которые не используют переменные
subTotal и
total, и выполнение этих инструкций между инструкциями №1 и №2, которые следуют в коде друг за другом.
 Изменение порядка выполнения инструкций, инструкция №3 будет выполнена между инструкциями №1 и №2
Изменение порядка выполнения инструкций, инструкция №3 будет выполнена между инструкциями №1 и №2
Это позволяет, в идеале, не прерывать поток инструкций, следующих по конвейеру.
Так как третья строка кода не зависит ни от первой, ни от второй, компилятор или процессор могут решить, что вполне безопасно изменить порядок выполнения инструкций. Когда всё это происходит в однопоточном режиме, внутри функции, другой код не получит доступ к этим значениям до тех пор, пока не завершится выполнение всей функции.
Однако, если имеется ещё один поток, выполняющийся параллельно, всё меняется. Другому потоку не обязательно ждать до тех пор, пока функция завершит работу, для того, чтобы узнать состояние переменных. Эти изменения другой поток может заметить едва ли не сразу же после того, как они произойдут. В результате окажется, что флаг
isDone, видимый другому потоку, будет установлен до завершения вычислений.
codeisDone как флаг, указывающий на то, что вычисление
total завершено, и полученное значение готово к использованию в другом потоке, изменение порядка выполнения операций приведёт к состоянию гонки потоков.
Объект Atomics пытается решать некоторые из подобных странностей. В частности, использование атомарной операции записи напоминает установку забора между двумя фрагментами кода. Отдельные инструкции атомарных операций не смешиваются с другими операциями. В частности, вот две операции, которые часто используются для того, чтобы обеспечить выполнение операций по порядку:
Если обновление некоей переменной выполняется в коде JS-функции выше команды
Atomics.store, оно гарантированно будет завершено до того, как
Atomics.store сохранит значение переменной в памяти. Если даже порядок выполнения неатомарных инструкций будет изменён по отношению друг к другу, ни одна из них не будет перемещена ниже вызова
Atomics.store, размещённого в нижней части кода.
Аналогично, загрузка переменной после вызова
Atomics.load гарантированно будет выполнена после того, как
Atomics.load прочтёт её значение. Опять же, если даже порядок выполнения неатомарных инструкций будет изменён, ни одна из них не будет перемещена так, что будет выполнена до
Atomics.load, которая размещена в коде выше неё.
 Обновление переменной выше Atomics.store гарантированно будет выполнено до завершения Atomics.store. Загрузка переменной ниже Atomics.load гарантированно будет выполнена после того, как Atomics.load завершит работу
Обновление переменной выше Atomics.store гарантированно будет выполнено до завершения Atomics.store. Загрузка переменной ниже Atomics.load гарантированно будет выполнена после того, как Atomics.load завершит работу
Обратите внимание на то, что цикл
while из этого примера реализует циклическую блокировку, это весьма неэффективная конструкция. Если нечто подобное окажется в главном потоке приложения, программа может попросту зависнуть. В реальном коде, практически наверняка, циклическими блокировками пользоваться не стоит.
Итоги
Многопоточное программирование с разделяемой памятью — задача непростая. Существует множество ситуаций, которые могут вызывать состояние гонки потоков. Они, как драконы, поджидают неопытных разработчиков в самых неожиданных местах.
 Многопоточное программирование с разделяемой памятью полно опасностей
Многопоточное программирование с разделяемой памятью полно опасностей
Мы, в этой серии из трёх материалов, постоянно говорили о том, что новые средства языка позволяют разработчикам библиотек создать простые, удобные и надёжные инструменты, предназначенные для обычных программистов. Путь SharedArrayBuffer и Atomics во вселенной JavaScript только начинается, поэтому библиотеки, построенные на их основе, пока ещё не созданы. Однако, теперь у JS-сообщества есть всё необходимое для разработки таких библиотек.
Уважаемые читатели! Если вы — из тех высококлассных программистов, не понаслышке знающих о многопоточности, в расчёте на которых созданы SharedArrayBuffer и Atomics, уверены, многим новичкам будет интересно узнать о том, в каком направлении стоит двигаться для того, чтобы стать разработчиком качественных библиотек, реализующих параллельные вычисления. Поделитесь, пожалуйста, опытом.