https://habr.com/ru/post/524388/- Python
- Обработка изображений
- Машинное обучение
- Облачные сервисы
- Kubernetes
Не так давно я писал про
волейбольный сервис, теперь пришло время описать его с технической точки зрения.
Возможно, общественное сознание найдет изъяны в архитектуре и подтолкнет к лучшим решениям.
Краткое описание функциональности:
- пользователь загружает видео с записью волейбольной игры
- один хитрый алгоритм распознает мяч на кадрах
- другой хитрый алгоритм выделяет розыгрыши
- розыгрыши компонуются в отдельные видеофайлы
- файлы с розыгрышами собираются в дайджест всей игры
- все видео заливается в облако
- пользователи смотрят/качают/шарят клипы с самыми классными розыгрышами
Например, такими:

Теперь, как это все работает.
Технологии
Все написано на python, веб-сервис — Django/Gunicorn.
Интенсивно используются OpenCV и FFMpeg.
База данных — Postgres.
Кэш и очередь — Redis.
Альфа
В самой первой версии было 3 компонента:
- Front — Веб сервис (Django), с которым взаимодействуют конечные пользователи
- Videoproc (Vproc) — Ядро алгоритма, python + opencv, которое содержит все алгоритмы треккинга мяча и логику нарезки на розыгрыши
- Clipper — Сервис генерации видео на основе выхлопа Vproc, используя ffmpeg
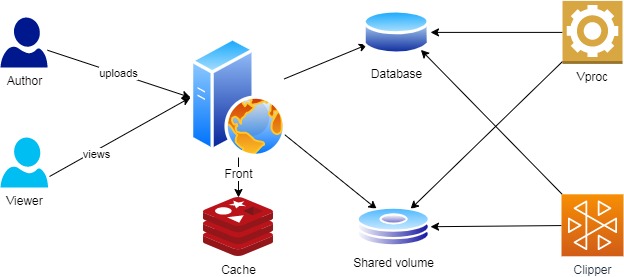
Разработка велась локально, я поставил на домашний десктоп Ubuntu, а на нее
microk8s и получил маленький Кубернетес-кластер.
Здесь я столкнулся с тем, что кадры, которые видит opencv не очень совпадают с временем, которое видит ffmpeg из-за особенностей кодеков, поэтому высчитать время в оригинальном файле из номера кадра оказалаось невозможно.
Из-за этого пришлось сохранять кадры, что сильно замедлило процесс и потребовало дальнейших архитектурных изменений.
Параллельная обработка
Как уже упоминалось, время обработки в 3 раза превышает время игры. Профайлер показал, что, большая часть времени тратится при записи кадров на диск, сам же разбор кадров примерно в два раза быстрее.
Логично распараллелить эти две работы.
По начальной задумке пока vproc разбирает кадры через opencv, ffmpeg параллельно записывает все на диск, а clipper собирает из них видео.
Но с ffmpeg нашлись две проблемы:
- Кадры из ffmpeg не идентичны кадрам из opencv (это не всегда так, зависит от кодека видеофайла)
- Количество кадров в записи может быть слишком большим — например час видео при хорошем fps — это порядка 200K файлов, что многовато для одного каталога, даже если это ext4. Городить разбиение на поддиректории и потом склеивать при компоновке видео — не хотелось усложнять
В итоге вместо ffmpeg появился пятый
элемент компонент — Framer. Он запускается из vproc, и листает кадры в том же видеофайле, ожидая пока vproc найдет розыгрыши. Как только они появились — framer выкладывает нужные кадры в отдельную директорию.
Из дополнительных плюсов — ни одного лишнего кадра не эспортируется.
Мелочь, но все таки.
По производительности (на 10-минутном тестовом видео):
Было:
Completed file id=73, for game=test, frames=36718, fps=50, duration=600 in 1677 sec
Стало:
Completed file id=83, for game=test, frames=36718, fps=50, duration=600 in 523 sec + framer time 303
Выигрыш в два раза, очень хорошо. Если писать в несколько потоков, то наверное можно выжать еще чуть. Если хранить кадры в памяти и генерить из них видео через API, то скорее всего можно ускориться значительно.
Digital Ocean
Дальше я стал выбирать хостинг. Понятно, что основные варианты — GKE, AWS, Azure, но многие авторы мелких проектов жалуются на непрозрачное ценообразование и, как следствие, немаленькие счета.
Основная засада здесь — цена за исходящий трафик, она составляет порядка $100/Tb, а поскольку речь идет о раздаче видео, вероятность серьезно попасть очень неиллюзорна.
Тогда я решил глянуть второй эшелон — Digital Ocean, Linode, Heroku. На самом деле Kubernetes-as-service уже не такая редкая вещь, но многие варианты не выглядят user-friendly.
Больше всего понравился Digital Ocean, потому что:
- Managed Kubernetes
- Managed Postgres
- S3 хранилище с бесплатным(!) CDN + 1 TB/месяц
- Закрытый docker registry
- Все операции можно делать через API
- Датацентры по всему миру
При наличии CDN веб-серверу уже не было надобности раздавать видео, однако кто-то должен был это видео опубликовать.
Так в архитектуре появился четвертый компонент — Pusher.
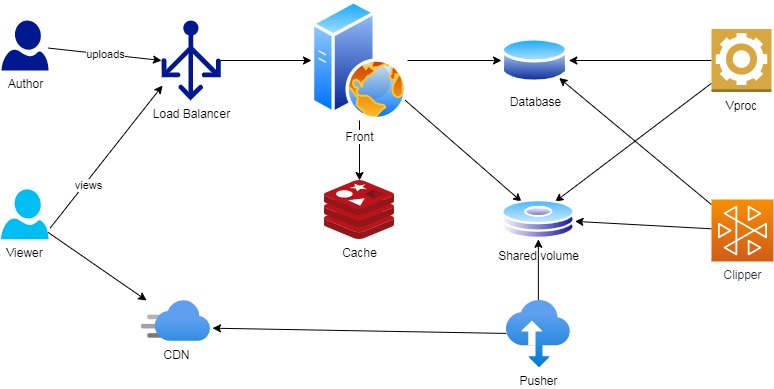
Однако серьезным недостатком оказалась
невозможность смонтировать один и тот же диск на несколько машин одновременно.
Сам DO
предлагает в таких случаях использовать NFS через выделенный контейнер, но пока решил не заморачиваться, ибо, как упоминалось выше, назревает специальное решение для видео кадров, и если уже городить отдельный контейнер, то для него.
Тем не менее, отсутствие общего диска серьезно повлияло на архитектуру.
Если с передачей загружаемого файла, можно было выкрутиться через S3, то гонять туда-сюда сотни тысяч кадров не выглядело блестящим вариантом.
В итоге, пришлось привязать все стадии обработки конкретной видео к одной ноде, что конечно уменьшило общую масштабируемость системы.
Логи и метрики
Запустив кластер в облаке, я стал искать решение для сбора логов и метрик. Самостоятельно возиться с хостингом этого добра не хотелось, поэтому целью был free-tier в каком-нибудь облаке.
Такое есть не у всех: Модная Grafana хочет $50 в месяц, выходящий из моды Elastic — $16, Splunk даже прямо не говорит.
Зато внезапно оказалось что New Relic, также известный своими негуманными ценами, теперь предоставляет первые 100G в месяц бесплатно.
Видео
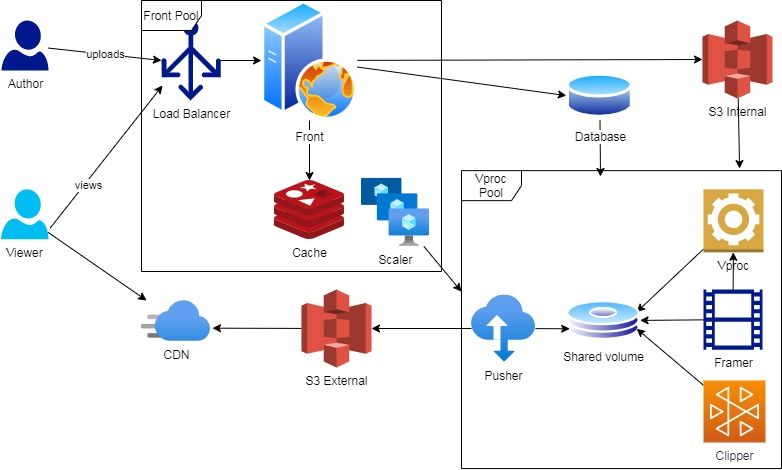
Вполне естественным решением виделось разделить кластер на два node-pool'а:
- front — на котором крутятся веб-сервера
- vproc — где обрабатывается видео
Фронтовой пул, понятно, всегда онлайн, а вот процессинговый не так прост.
Во-первых, обработка видео требует серьезных ресурсов (= денег), а во-вторых, обрабатывать приходится нечасто (особенно в стадии зарождения проекта).
Поэтому хочется включать процессинг только, чтобы обработать видео (время обработки — 3x от продолжительности действа).
Кубернетес формально поддерживает autoscale 0, но как именно это реализуется — я не нашел, зато нашлась
такая дискуссия на Stack Overflow.
В итоге пришлось нагородить еще один под во фронтовом пуле, единственной задачей которого является посматривать в постгрес иногда и включать/выключать процессинговый пул в зависимости от того, что в базе оказалось.
У DigitalOcean есть
неофициальный клиент для питона, но он уже давно не обновлялся, а Kubernetes API там не присутствует в принципе.
Я сделал на коленке
клиент для себя, он покрывает процентов десять возможностей, но вдруг кому пригодится для старта.
В итоге диаграмм разрослась вот так:
DevOps
Несмотря на великое множество CI/CD инструментов, в разработке не нашлось ничего удобнее Jenkins.
А для управления DigitalOcean'ом идеально подошли Github Actions.
Ссылки