Apache Airflow: делаем ETL проще
- вторник, 28 июля 2020 г. в 00:27:08
Привет, я Дмитрий Логвиненко — Data Engineer отдела аналитики группы компаний «Везёт».
Я расскажу вам о замечательном инструменте для разработки ETL-процессов — Apache Airflow. Но Airflow настолько универсален и многогранен, что вам стоит присмотреться к нему даже если вы не занимаетесь потоками данных, а имеете потребность периодически запускать какие-либо процессы и следить за их выполнением.
И да, я буду не только рассказывать, но и показывать: в программе много кода, скриншотов и рекомендаций.
Что обычно видишь, когда гуглишь слово Airflow / Wikimedia Commons
Apache Airflow — он прямо как Django:
— только лучше, да и сделан совсем для других целей, а именно (как написано до ката):
Мы используем Apache Airflow так:
cron, который запускает процессы консолидации данных на ODS, а также следит за их обслуживанием.До недавнего времени наши потребности покрывал один небольшой сервер на 32 ядрах и 50 GB оперативки. В Airflow при этом работает:
А о том, как мы расширялись, я напишу ниже, а сейчас давайте определим über-задачу, которую мы будем решать:
Есть три исходных SQL Server’а, на каждом по 50 баз данных — инстансов одного проекта, соответственно, структура у них одинаковая (почти везде, муа-ха-ха), а значит в каждой есть таблица Orders (благо таблицу с таким названием можно затолкать в любой бизнес). Мы забираем данные, добавляя служебные поля (сервер-источник, база-источник, идентификатор ETL-задачи) и наивным образом бросим их в, скажем, Vertica.
Поехали!
Когда деревья были большими, а я был простым SQL-щиком в одном российском ритейле, мы шпарили ETL-процессы aka потоки данных с помощью двух доступных нам средств:
Informatica Power Center — крайне развесистая система, чрезвычайно производительная, со своими железками, собственным версионированием. Использовал я дай бог 1% её возможностей. Почему? Ну, во-первых, этот интерфейс где-то из нулевых психически давил на нас. Во-вторых, эта штуковина заточена под чрезвычайно навороченные процессы, яростное переиспользование компонентов и другие очень-важные-энтерпрайз-фишечки. Про то что стоит она, как крыло Airbus A380/год, мы промолчим.
SQL Server Integration Server — этим товарищем мы пользовались в своих внутрипроектных потоках. Ну а в самом деле: SQL Server мы уже используем, и не юзать его ETL-тулзы было бы как-то неразумно. Всё в нём в хорошо: и интерфейс красивый, и отчётики выполнения… Но не за это мы любим программные продукты, ох не за это. Версионировать его dtsx (который представляет собой XML с перемешивающимися при сохранении нодами) мы можем, а толку? А сделать пакет тасков, который перетащит сотню таблиц с одного сервера на другой? Да что сотню, у вас от двадцати штук отвалится указательный палец, щёлкающий по мышиной кнопке. Но выглядит он, определенно, более модно:

Мы безусловно искали выходы. Дело даже почти дошло до самописного генератора SSIS-пакетов...
… а потом меня нашла новая работа. А на ней меня настиг Apache Airflow.
Когда я узнал, что описания ETL-процессов — это простой Python-код, я только что не плясал от радости. Вот так потоки данных подверглись версионированию и диффу, а ссыпать таблицы с единой структурой из сотни баз данных в один таргет стало делом Python-кода в полтора-два 13” экрана.
Давайте не устраивать совсем уж детский сад, и не говорить тут о совершенно очевидных вещах, вроде установки Airflow, выбранной вами БД, Celery и других дел, описанных в доках.
Чтобы мы могли сразу приступить к экспериментам, я набросал docker-compose.yml в котором:
apache/airflow:1.10.10-python3.7, а мы и не против);./dags мы будет складывать наши файлы с описанием дагов. Они будут подхватываться на лету, поэтому передёргивать весь стек после каждого чиха не нужно.Кое-где код в примерах приведен не полностью (чтобы не загромождать текст), а где-то он модифицируется в процессе. Цельные работающие примеры кода можно посмотреть в репозитории https://github.com/dm-logv/airflow-tutorial.
version: '3.4'
x-airflow-config: &airflow-config
AIRFLOW__CORE__DAGS_FOLDER: /dags
AIRFLOW__CORE__EXECUTOR: CeleryExecutor
AIRFLOW__CORE__FERNET_KEY: MJNz36Q8222VOQhBOmBROFrmeSxNOgTCMaVp2_HOtE0=
AIRFLOW__CORE__HOSTNAME_CALLABLE: airflow.utils.net:get_host_ip_address
AIRFLOW__CORE__SQL_ALCHEMY_CONN: postgres+psycopg2://airflow:airflow@airflow-db:5432/airflow
AIRFLOW__CORE__PARALLELISM: 128
AIRFLOW__CORE__DAG_CONCURRENCY: 16
AIRFLOW__CORE__MAX_ACTIVE_RUNS_PER_DAG: 4
AIRFLOW__CORE__LOAD_EXAMPLES: 'False'
AIRFLOW__CORE__LOAD_DEFAULT_CONNECTIONS: 'False'
AIRFLOW__EMAIL__DEFAULT_EMAIL_ON_RETRY: 'False'
AIRFLOW__EMAIL__DEFAULT_EMAIL_ON_FAILURE: 'False'
AIRFLOW__CELERY__BROKER_URL: redis://broker:6379/0
AIRFLOW__CELERY__RESULT_BACKEND: db+postgresql://airflow:airflow@airflow-db/airflow
x-airflow-base: &airflow-base
image: apache/airflow:1.10.10-python3.7
entrypoint: /bin/bash
restart: always
volumes:
- ./dags:/dags
- ./requirements.txt:/requirements.txt
services:
# Redis as a Celery broker
broker:
image: redis:6.0.5-alpine
# DB for the Airflow metadata
airflow-db:
image: postgres:10.13-alpine
environment:
- POSTGRES_USER=airflow
- POSTGRES_PASSWORD=airflow
- POSTGRES_DB=airflow
volumes:
- ./db:/var/lib/postgresql/data
# Main container with Airflow Webserver, Scheduler, Celery Flower
airflow:
<<: *airflow-base
environment:
<<: *airflow-config
AIRFLOW__SCHEDULER__DAG_DIR_LIST_INTERVAL: 30
AIRFLOW__SCHEDULER__CATCHUP_BY_DEFAULT: 'False'
AIRFLOW__SCHEDULER__MAX_THREADS: 8
AIRFLOW__WEBSERVER__LOG_FETCH_TIMEOUT_SEC: 10
depends_on:
- airflow-db
- broker
command: >
-c " sleep 10 &&
pip install --user -r /requirements.txt &&
/entrypoint initdb &&
(/entrypoint webserver &) &&
(/entrypoint flower &) &&
/entrypoint scheduler"
ports:
# Celery Flower
- 5555:5555
# Airflow Webserver
- 8080:8080
# Celery worker, will be scaled using `--scale=n`
worker:
<<: *airflow-base
environment:
<<: *airflow-config
command: >
-c " sleep 10 &&
pip install --user -r /requirements.txt &&
/entrypoint worker"
depends_on:
- airflow
- airflow-db
- brokerПримечания:
airflow.cfg, но и через переменные среды (слава разработчикам), чем я злостно воспользовался.Ну а теперь просто:
$ docker-compose up --scale worker=3После того, как всё поднимется, можно смотреть на веб-интерфейсы:
Если вы ничего не поняли во всех этих «дагах», то вот краткий словарик:
Scheduler — самый главный дядька в Airflow, контролирующий, чтобы вкалывали роботы, а не человек: следит за расписанием, обновляет даги, запускает таски.
Вообще, в старых версиях, у него были проблемы с памятью (нет, не амнезия, а утечки) и в конфигах даже остался легаси-параметр run_duration — интервал его перезапуска. Но сейчас всё хорошо.
DAG (он же «даг») — «направленный ацикличный граф», но такое определение мало кому что скажет, а по сути это контейнер для взаимодействующих друг с другом тасков (см. ниже) или аналог Package в SSIS и Workflow в Informatica.
Помимо дагов еще могут быть сабдаги, но мы до них скорее всего не доберёмся.
DAG Run — инициализированный даг, которому присвоен свой execution_date. Даграны одного дага могут вполне работать параллельно (если вы, конечно, сделали свои таски идемпотентными).
Operator — это кусочки кода, ответственные за выполнение какого-либо конкретного действия. Есть три типа операторов:
PythonOperator, который в силах выполнить любой (валидный) Python-код;MsSqlToHiveTransfer;HttpSensor может дергать указанный эндпойнт, и когда дождется нужный ответ, запустить трансфер GoogleCloudStorageToS3Operator. Пытливый ум спросит: «зачем? Ведь можно делать повторы прямо в операторе!» А затем, чтобы не забивать пул тасков подвисшими операторами. Сенсор запускается, проверяет и умирает до следующей попытки.Task — объявленные операторы вне зависимости от типа и прикрепленные к дагу повышаются до чина таска.
Task instance — когда генерал-планировщик решил, что таски пора отправлять в бой на исполнители-воркеры (прямо на месте, если мы используем LocalExecutor или на удалённую ноду в случае с CeleryExecutor), он назначает им контекст (т. е. комплект переменных — параметров выполнения), разворачивает шаблоны команд или запросов и складывает их в пул.
Сперва обозначим общую схему нашего дага, а затем будем всё больше и больше погружаться в детали, потому что мы применяем некоторые нетривиальные решения.
Итак, в простейшем виде подобный даг будет выглядеть так:
from datetime import timedelta, datetime
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from commons.datasources import sql_server_ds
dag = DAG('orders',
schedule_interval=timedelta(hours=6),
start_date=datetime(2020, 7, 8, 0))
def workflow(**context):
print(context)
for conn_id, schema in sql_server_ds:
PythonOperator(
task_id=schema,
python_callable=workflow,
provide_context=True,
dag=dag)Давайте разбираться:
sql_server_ds — это List[namedtuple[str, str]] с именами коннектов из Airflow Connections и базами данных из которых мы будем забирать нашу табличку;dag — объявление нашего дага, которое обязательно должно лежать в globals(), иначе Airflow его не найдет. Дагу также нужно сказать: orders — это имя потом будет маячить в веб-интерфейсе,timedelta() допустима cron-строка 0 0 0/6 ? * * *, для менее крутых — выражение вроде @daily);workflow() будет делать основную работу, но не сейчас. Сейчас мы просто высыпем наш контекст в лог.PythonOperator, который будет выполнять нашу пустышку workflow(). Не забывайте указывать уникальное (в рамках дага) имя таска и подвязывать сам даг. Флаг provide_context в свою очередь насыпет в функцию дополнительных аргументов, которые мы бережно соберём с помощью **context.Пока на этом всё. Что мы получили:
Ну, почти получили.
Зависимости кто будет ставить?
Чтобы всё это дело упростить я вкорячил в docker-compose.yml обработку requirements.txt на всех нодах.
Вот теперь понеслась:

Серые квадратики — task instances, обработанные планировщиком.
Немного ждем, задачи расхватывают воркеры:

Зеленые, понятное дело, — успешно отработавшие. Красные — не очень успешно.
Кстати, на нашем проде никакой папки./dags, синхронизирующейся между машинами нет — всё даги лежат вgitна нашем Gitlab, а Gitlab CI раскладывает обновления на машины при мёрдже вmaster.
Пока воркеры молотят наши тасочки-пустышки, вспомним про еще один инструмент, который может нам кое-что показать — Flower.
Самая первая страничка с суммарной информацией по нодам-воркерам:

Самая насыщенная страничка с задачами, отправившимися в работу:

Самая скучная страничка с состоянием нашего брокера:
Самая яркая страничка — с графиками состояния тасков и их временем выполнения:
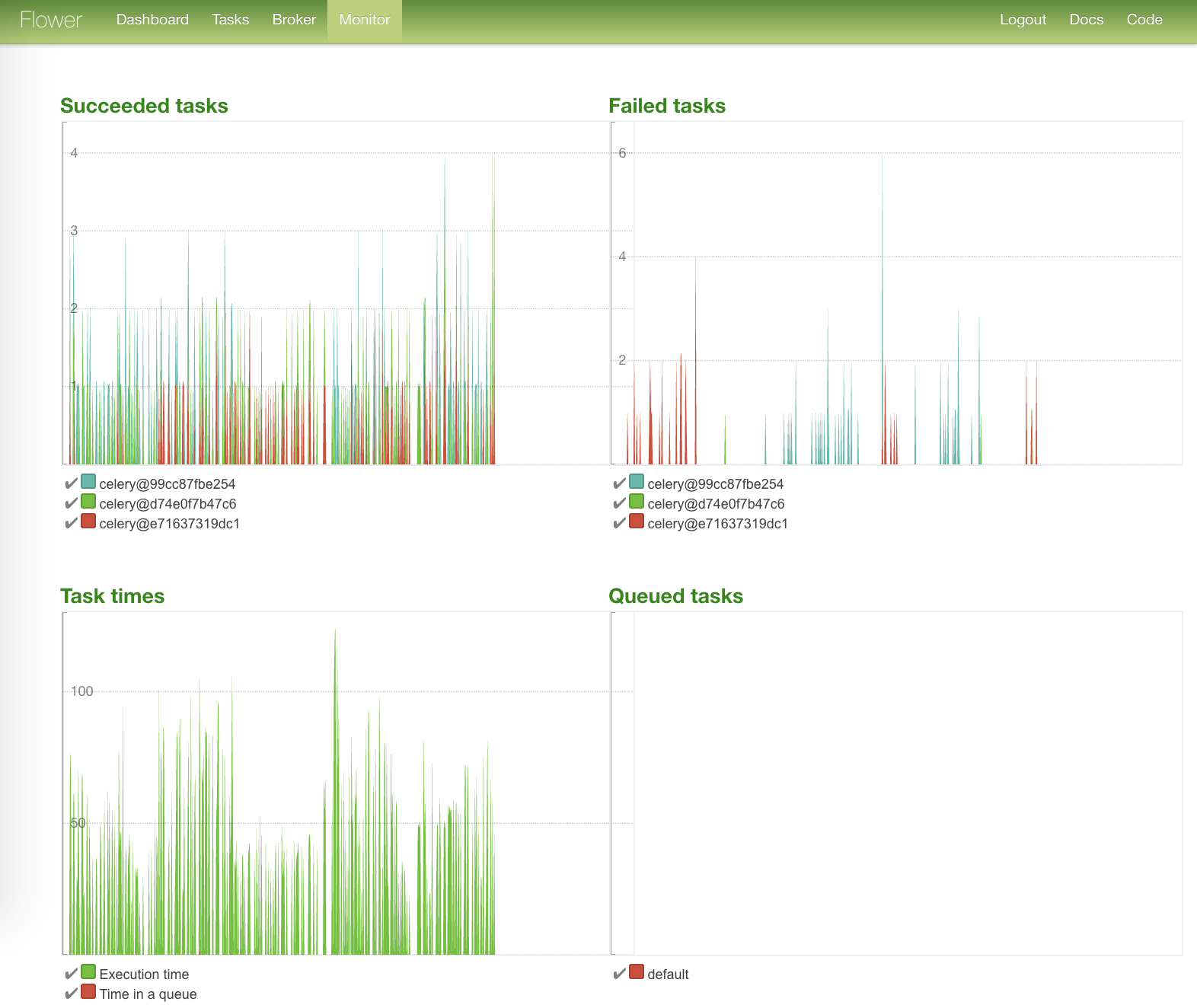
Итак, все таски отработали, можно уносить раненых.
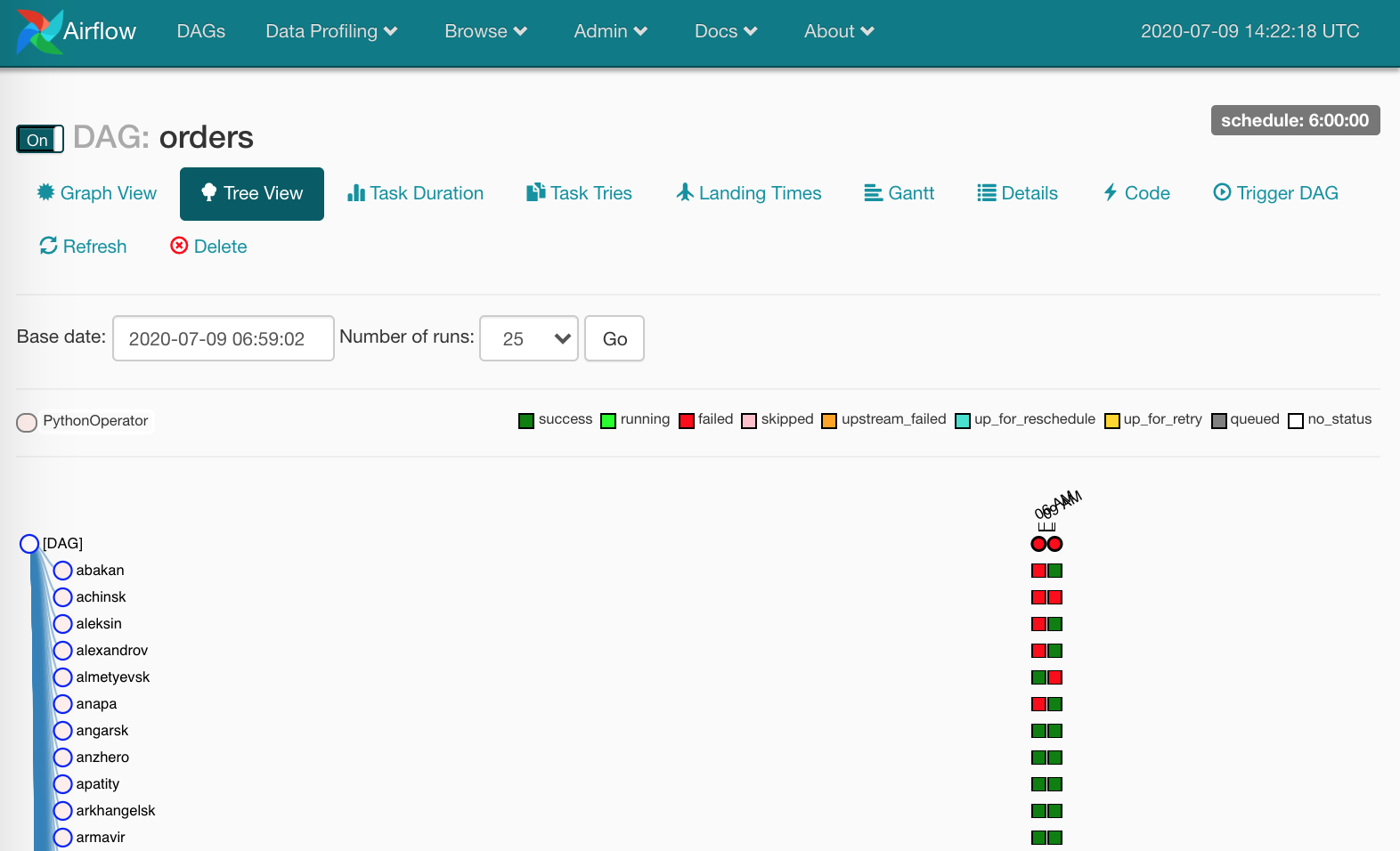
А раненых оказалось немало — по тем или иным причинами. В случае правильного использования Airflow вот эти самые квадраты говорят о том, что данные определенно не доехали.
Нужно смотреть лог и перезапускать упавшие task instances.
Жмякнув на любой квадрат, увидим доступные нам действия:

Можно взять, и сделать Clear упавшему. То есть, мы забываем о том, что там что-то завалилось, и тот же самый инстанс таска уйдет планировщику.

Понятно, что делать так мышкой со всеми красными квадратами не очень гуманно — не этого мы ждем от Airflow. Естественно, у нас есть оружие массового поражения: Browse/Task Instances
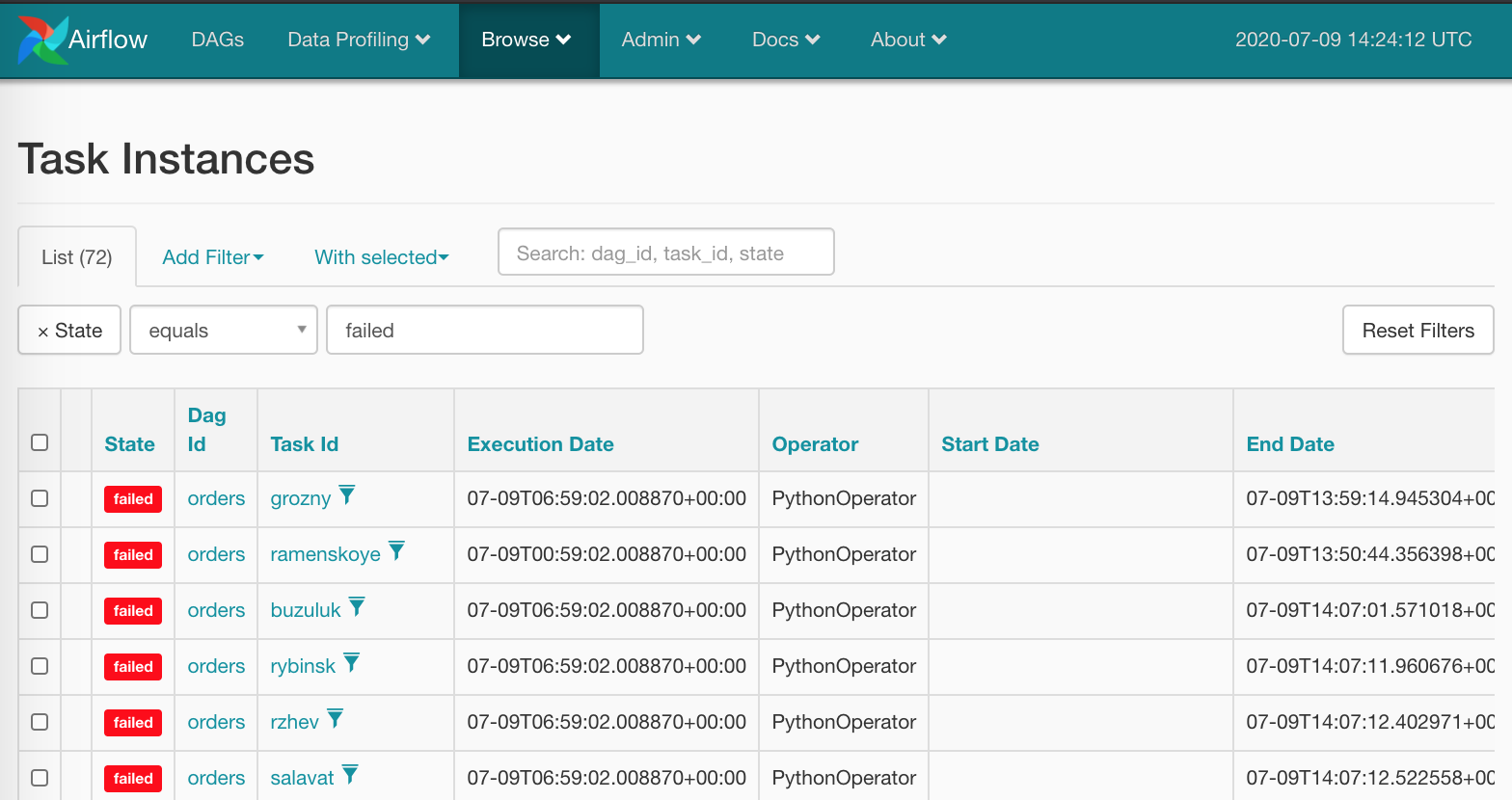
Выберем всё разом и обнулим нажмем правильный пункт:

После очистки наши такси выглядят так (они уже ждут не дождутся, когда шедулер их запланирует):

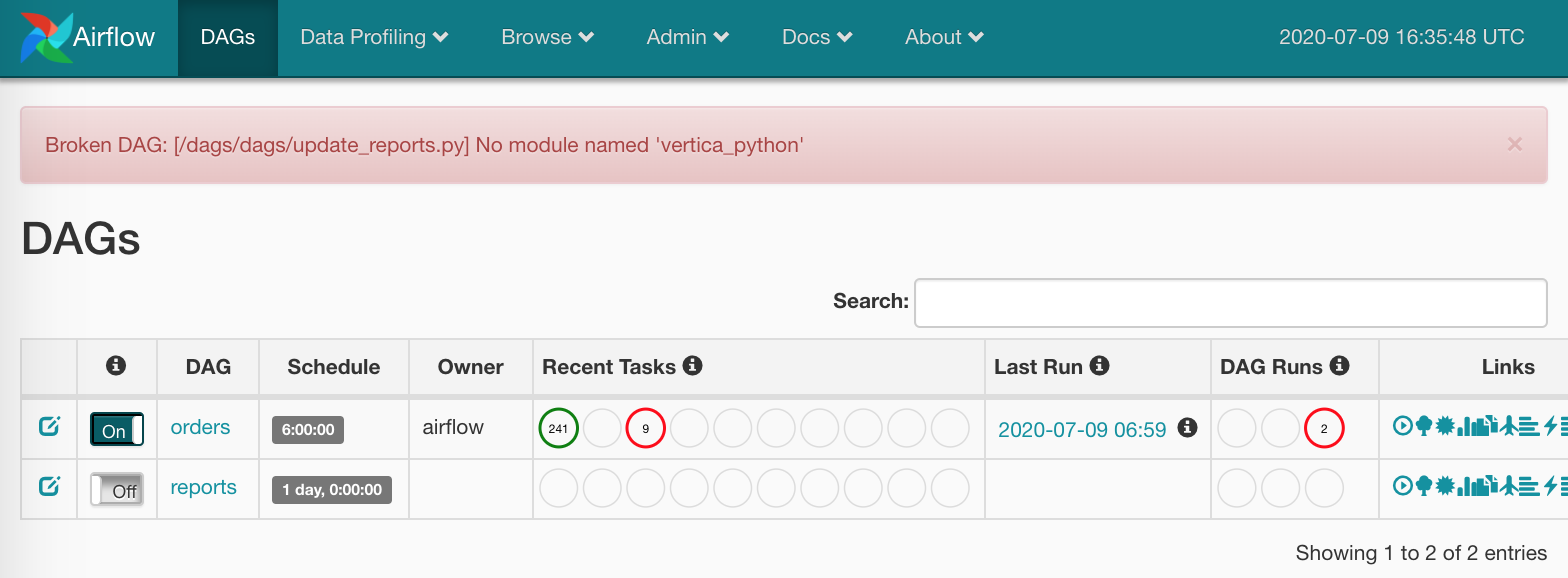
Самое время посмотреть на следующий DAG, update_reports.py:
from collections import namedtuple
from datetime import datetime, timedelta
from textwrap import dedent
from airflow import DAG
from airflow.contrib.operators.vertica_operator import VerticaOperator
from airflow.operators.email_operator import EmailOperator
from airflow.utils.trigger_rule import TriggerRule
from commons.operators import TelegramBotSendMessage
dag = DAG('update_reports',
start_date=datetime(2020, 6, 7, 6),
schedule_interval=timedelta(days=1),
default_args={'retries': 3, 'retry_delay': timedelta(seconds=10)})
Report = namedtuple('Report', 'source target')
reports = [Report(f'{table}_view', table) for table in [
'reports.city_orders',
'reports.client_calls',
'reports.client_rates',
'reports.daily_orders',
'reports.order_duration']]
email = EmailOperator(
task_id='email_success', dag=dag,
to='{{ var.value.all_the_kings_men }}',
subject='DWH Reports updated',
html_content=dedent("""Господа хорошие, отчеты обновлены"""),
trigger_rule=TriggerRule.ALL_SUCCESS)
tg = TelegramBotSendMessage(
task_id='telegram_fail', dag=dag,
tg_bot_conn_id='tg_main',
chat_id='{{ var.value.failures_chat }}',
message=dedent("""\
Наташ, просыпайся, мы {{ dag.dag_id }} уронили
"""),
trigger_rule=TriggerRule.ONE_FAILED)
for source, target in reports:
queries = [f"TRUNCATE TABLE {target}",
f"INSERT INTO {target} SELECT * FROM {source}"]
report_update = VerticaOperator(
task_id=target.replace('reports.', ''),
sql=queries, vertica_conn_id='dwh',
task_concurrency=1, dag=dag)
report_update >> [email, tg]Все ведь когда-нибудь делали обновлялку отчетов? Это снова она: есть список источников, откуда забрать данные; есть список, куда положить; не забываем посигналить, когда всё случилось или сломалось (ну это не про нас, нет).
Давайте снова пройдемся по файлу и посмотрим на новые непонятные штуки:
from commons.operators import TelegramBotSendMessage — нам ничто не мешает делать свои операторы, чем мы и воспользовались, сделав небольшую обёрточку для отправки сообщений в Разблокированный. (Об этом операторе мы еще поговорим ниже);default_args={} — даг может раздавать одни и те же аргументы всем своим операторам;to='{{ var.value.all_the_kings_men }}' — поле to у нас будет не захардкоженным, а формируемым динамически с помощью Jinja и переменной со списком email-ов, которую я заботливо положил в Admin/Variables;trigger_rule=TriggerRule.ALL_SUCCESS — условие запуска оператора. В нашем случае, письмо полетит боссам только если все зависимости отработали успешно;tg_bot_conn_id='tg_main' — аргументы conn_id принимают в себя идентификаторы соединений, которые мы создаем в Admin/Connections;trigger_rule=TriggerRule.ONE_FAILED — сообщения в Telegram улетят только при наличии упавших тасков;task_concurrency=1 — запрещаем одновременный запуск нескольких task instances одного таска. В противном случае, мы получим одновременный запуск нескольких VerticaOperator (смотрящих на одну таблицу);report_update >> [email, tg] — все VerticaOperator сойдутся в отправке письма и сообщения, вот так:
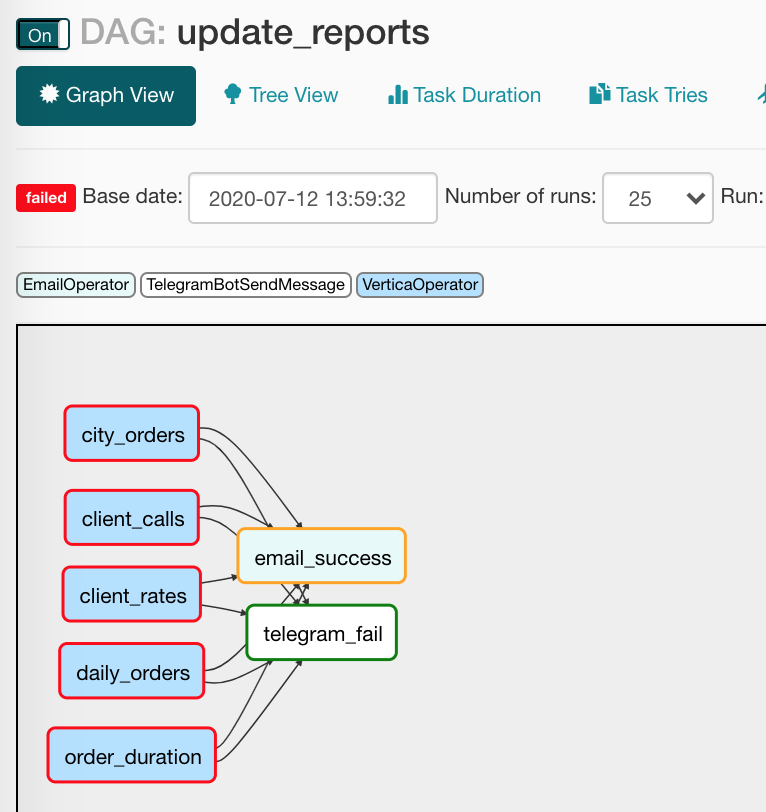
Но так как у операторов-нотификаторов стоят разные условия запуска, работать будет только один. В Tree View всё выглядит несколько менее наглядно:

Скажу пару слов о макросах и их друзьях — переменных.
Макросы — это Jinja-плейсхолдеры, которые могут подставлять разную полезную информацию в аргументы операторов. Например, так:
SELECT
id,
payment_dtm,
payment_type,
client_id
FROM orders.payments
WHERE
payment_dtm::DATE = '{{ ds }}'::DATE{{ ds }} развернется в содержимое переменной контекста execution_date в формате YYYY-MM-DD: 2020-07-14. Самое приятное, что переменные контекста прибиваются гвоздями к определенному инстансу таска (квадратику в Tree View), и при перезапуске плейсхолдеры раскроются в те же самые значения.
Присвоенные значения можно смотреть с помощью кнопки Rendered на каждом таск-инстансе. Вот так у таска с отправкой письма:

А так у таски с отправкой сообщения:

Полный список встроенных макросов для последней доступной версии доступен здесь: Macros Reference
Более того, с помощью плагинов, мы можем объявлять собственные макросы, но это уже совсем другая история.
Помимо предопределенных штук, мы можем подставлять значения своих переменных (выше в коде я уже этим воспользовался). Создадим в Admin/Variables пару штук:
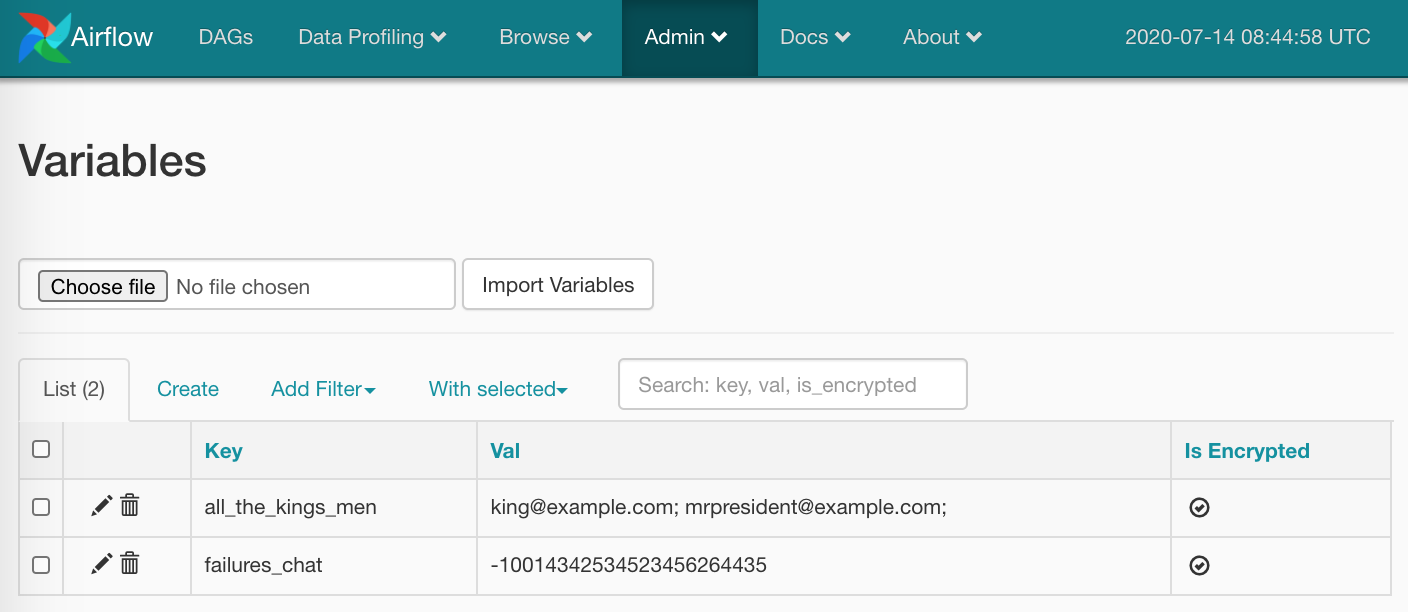
Всё, можно пользоваться:
TelegramBotSendMessage(chat_id='{{ var.value.failures_chat }}')В значении может быть скаляр, а может лежать и JSON. В случае JSON-а:
bot_config
{
"bot": {
"token": 881hskdfASDA16641,
"name": "Verter"
},
"service": "TG"
}просто используем путь к нужному ключу: {{ var.json.bot_config.bot.token }}.
Скажу буквально одно слово и покажу один скриншот про соединения. Тут всё элементарно: на странице Admin/Connections создаем соединение, складываем туда наши логины/пароли и более специфичные параметры. Вот так:
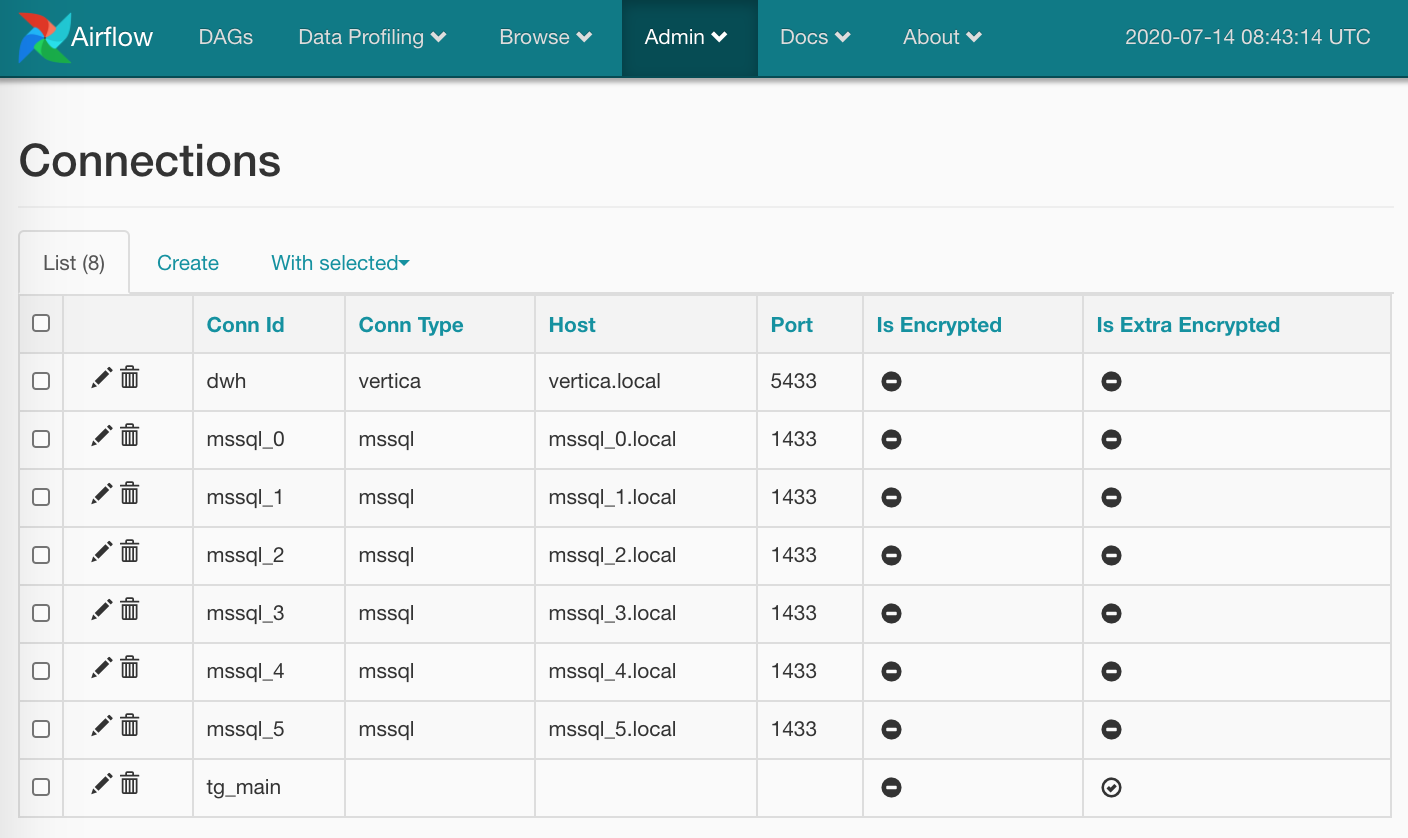
Пароли можно шифровать (более тщательно, чем в варианте по умолчанию), а можно не указывать тип соединения (как я сделал для tg_main) — дело в том, что список типов зашит в моделях Airflow и расширению без влезания в исходники не поддается (если вдруг я чего-то не догуглил — прошу меня поправить), но получить креды просто по имени нам ничто не помешает.
А еще можно сделать несколько соединений с одним именем: в таком случае метод BaseHook.get_connection(), который достает нам соединения по имени, будет отдавать случайного из нескольких тёзок (было бы логичнее сделать Round Robin, но оставим это на совести разработчиков Airflow).
Variables и Connections, безусловно, классные средства, но важно не потерять баланс: какие части ваших потоков вы храните собственно в коде, а какие — отдаете на хранение Airflow. C одной стороны быстро поменять значение, например, ящик рассылки, может быть удобно через UI. А с другой — это всё-таки возврат к мышеклику, от которого мы (я) хотели избавиться.
Работа с соединениями — это одна из задач хуков. Вообще хуки Airflow — это точки подключения его к сторонним сервисам и библиотекам. К примеру, JiraHook откроет для нас клиент для взаимодействия с Jira (можно задачки подвигать туда-сюда), а с помощью SambaHook можно запушить локальный файл на smb-точку.
И мы вплотную подобрались к тому, чтобы посмотреть на то, как сделан TelegramBotSendMessage
Код commons/operators.py с собственно оператором:
from typing import Union
from airflow.operators import BaseOperator
from commons.hooks import TelegramBotHook, TelegramBot
class TelegramBotSendMessage(BaseOperator):
"""Send message to chat_id using TelegramBotHook
Example:
>>> TelegramBotSendMessage(
... task_id='telegram_fail', dag=dag,
... tg_bot_conn_id='tg_bot_default',
... chat_id='{{ var.value.all_the_young_dudes_chat }}',
... message='{{ dag.dag_id }} failed :(',
... trigger_rule=TriggerRule.ONE_FAILED)
"""
template_fields = ['chat_id', 'message']
def __init__(self,
chat_id: Union[int, str],
message: str,
tg_bot_conn_id: str = 'tg_bot_default',
*args, **kwargs):
super().__init__(*args, **kwargs)
self._hook = TelegramBotHook(tg_bot_conn_id)
self.client: TelegramBot = self._hook.client
self.chat_id = chat_id
self.message = message
def execute(self, context):
print(f'Send "{self.message}" to the chat {self.chat_id}')
self.client.send_message(chat_id=self.chat_id,
message=self.message)Здесь, как и остальное в Airflow, всё очень просто:
BaseOperator, который реализует довольно много Airflow-специфичных штук (посмотрите на досуге)template_fields, в которых Jinja будет искать макросы для обработки.__init__(), расставили умолчания, где надо.TelegramBotHook, получили от него объект-клиент.BaseOperator.execute(), который Airfow будет подергивать, когда наступит время запускать оператор — в нем мы и реализуем основное действие, на забыв залогироваться. (Логируемся, кстати, прямо в stdout и stderr — Airflow всё перехватит, красиво обернет, разложит, куда надо.)Давайте смотреть, что у нас в commons/hooks.py. Первая часть файлика, с самим хуком:
from typing import Union
from airflow.hooks.base_hook import BaseHook
from requests_toolbelt.sessions import BaseUrlSession
class TelegramBotHook(BaseHook):
"""Telegram Bot API hook
Note: add a connection with empty Conn Type and don't forget
to fill Extra:
{"bot_token": "YOuRAwEsomeBOtToKen"}
"""
def __init__(self,
tg_bot_conn_id='tg_bot_default'):
super().__init__(tg_bot_conn_id)
self.tg_bot_conn_id = tg_bot_conn_id
self.tg_bot_token = None
self.client = None
self.get_conn()
def get_conn(self):
extra = self.get_connection(self.tg_bot_conn_id).extra_dejson
self.tg_bot_token = extra['bot_token']
self.client = TelegramBot(self.tg_bot_token)
return self.clientЯ даже не знаю, что тут можно объяснять, просто отмечу важные моменты:
conn_id;get_conn(), в котором я получаю параметры соединения по имени и всего-навсего достаю секцию extra (это поле для JSON), в которую я (по своей же инструкции!) положил токен Telegram-бота: {"bot_token": "YOuRAwEsomeBOtToKen"}.TelegramBot, отдавая ему уже конкретный токен.Вот и всё. Получить клиент из хука можно c помощью TelegramBotHook().clent или TelegramBotHook().get_conn().
И вторая часть файлика, в котором я сделать микрообёрточку для Telegram REST API, чтобы не тащить тот же python-telegram-bot ради одного метода sendMessage.
class TelegramBot:
"""Telegram Bot API wrapper
Examples:
>>> TelegramBot('YOuRAwEsomeBOtToKen', '@myprettydebugchat').send_message('Hi, darling')
>>> TelegramBot('YOuRAwEsomeBOtToKen').send_message('Hi, darling', chat_id=-1762374628374)
"""
API_ENDPOINT = 'https://api.telegram.org/bot{}/'
def __init__(self, tg_bot_token: str, chat_id: Union[int, str] = None):
self._base_url = TelegramBot.API_ENDPOINT.format(tg_bot_token)
self.session = BaseUrlSession(self._base_url)
self.chat_id = chat_id
def send_message(self, message: str, chat_id: Union[int, str] = None):
method = 'sendMessage'
payload = {'chat_id': chat_id or self.chat_id,
'text': message,
'parse_mode': 'MarkdownV2'}
response = self.session.post(method, data=payload).json()
if not response.get('ok'):
raise TelegramBotException(response)
class TelegramBotException(Exception):
def __init__(self, *args, **kwargs):
super().__init__((args, kwargs))Правильный путь — сложить всё это:TelegramBotSendMessage,TelegramBotHook,TelegramBot— в плагин, положить в общедоступный репозиторий, и отдать в Open Source.
Пока мы всё это изучали, наши обновления отчетов успели успешно завалиться и отправить мне в канал сообщение об ошибке. Пойду проверять, что опять не так...
В нашем даге что-то сломалось! А ни этого ли мы ждали? Именно!
Чувствуете, что-то я пропустил? Вроде бы обещал данные из SQL Server в Vertica переливать, и тут взял и съехал с темы, негодяй!
Злодеяние это было намеренным, я просто обязан был расшифровать вам кое-какую терминологию. Теперь можно ехать дальше.
План у нас был такой:
Итак, чтобы всё это запустить, я сделал маленькое дополнение к нашему docker-compose.yml:
version: '3.4'
x-mssql-base: &mssql-base
image: mcr.microsoft.com/mssql/server:2017-CU21-ubuntu-16.04
restart: always
environment:
ACCEPT_EULA: Y
MSSQL_PID: Express
SA_PASSWORD: SayThanksToSatiaAt2020
MSSQL_MEMORY_LIMIT_MB: 1024
services:
dwh:
image: jbfavre/vertica:9.2.0-7_ubuntu-16.04
mssql_0:
<<: *mssql-base
mssql_1:
<<: *mssql-base
mssql_2:
<<: *mssql-base
mssql_init:
image: mio101/py3-sql-db-client-base
command: python3 ./mssql_init.py
depends_on:
- mssql_0
- mssql_1
- mssql_2
environment:
SA_PASSWORD: SayThanksToSatiaAt2020
volumes:
- ./mssql_init.py:/mssql_init.py
- ./dags/commons/datasources.py:/commons/datasources.pyТам мы поднимаем:
dwh с самыми дефолтными настройками,mssql_init.py!)Запускаем всё добро с помощью чуть более сложной, чем в прошлый раз, команды:
$ docker-compose -f docker-compose.yml -f docker-compose.db.yml up --scale worker=3Что нагенерировал наш чудорандомайзер, можно, воспользовавшись пунктом Data Profiling/Ad Hoc Query:
Главное, не показывать это аналитикам
Подробно останавливаться на ETL-сессиях я не буду, там всё тривиально: делаем базу, в ней табличку, оборачиваем всё менеджером контекста, и теперь делаем так:
with Session(task_name) as session:
print('Load', session.id, 'started')
# Load worflow
...
session.successful = True
session.loaded_rows = 15from sys import stderr
class Session:
"""ETL workflow session
Example:
with Session(task_name) as session:
print(session.id)
session.successful = True
session.loaded_rows = 15
session.comment = 'Well done'
"""
def __init__(self, connection, task_name):
self.connection = connection
self.connection.autocommit = True
self._task_name = task_name
self._id = None
self.loaded_rows = None
self.successful = None
self.comment = None
def __enter__(self):
return self.open()
def __exit__(self, exc_type, exc_val, exc_tb):
if any(exc_type, exc_val, exc_tb):
self.successful = False
self.comment = f'{exc_type}: {exc_val}\n{exc_tb}'
print(exc_type, exc_val, exc_tb, file=stderr)
self.close()
def __repr__(self):
return (f'<{self.__class__.__name__} '
f'id={self.id} '
f'task_name="{self.task_name}">')
@property
def task_name(self):
return self._task_name
@property
def id(self):
return self._id
def _execute(self, query, *args):
with self.connection.cursor() as cursor:
cursor.execute(query, args)
return cursor.fetchone()[0]
def _create(self):
query = """
CREATE TABLE IF NOT EXISTS sessions (
id SERIAL NOT NULL PRIMARY KEY,
task_name VARCHAR(200) NOT NULL,
started TIMESTAMPTZ NOT NULL DEFAULT current_timestamp,
finished TIMESTAMPTZ DEFAULT current_timestamp,
successful BOOL,
loaded_rows INT,
comment VARCHAR(500)
);
"""
self._execute(query)
def open(self):
query = """
INSERT INTO sessions (task_name, finished)
VALUES (%s, NULL)
RETURNING id;
"""
self._id = self._execute(query, self.task_name)
print(self, 'opened')
return self
def close(self):
if not self._id:
raise SessionClosedError('Session is not open')
query = """
UPDATE sessions
SET
finished = DEFAULT,
successful = %s,
loaded_rows = %s,
comment = %s
WHERE
id = %s
RETURNING id;
"""
self._execute(query, self.successful, self.loaded_rows,
self.comment, self.id)
print(self, 'closed',
', successful: ', self.successful,
', Loaded: ', self.loaded_rows,
', comment:', self.comment)
class SessionError(Exception):
pass
class SessionClosedError(SessionError):
passНастала пора забрать наши данные из наших полутора сотен таблиц. Сделаем это с помощью очень незатейливых строчек:
source_conn = MsSqlHook(mssql_conn_id=src_conn_id, schema=src_schema).get_conn()
query = f"""
SELECT
id, start_time, end_time, type, data
FROM dbo.Orders
WHERE
CONVERT(DATE, start_time) = '{dt}'
"""
df = pd.read_sql_query(query, source_conn)pymssql-коннект pandas, который достанет для нас DataFrame — он нам пригодится в дальнейшем.Я использую подстановку{dt}вместо параметра запроса%sне потому, что я злобный Буратино, а потому чтоpandasне может совладать сpymssqlи подсовывает последнемуparams: List, хотя тот очень хочетtuple.
Также обратите внимание, что разработчикpymssqlрешил больше его не поддерживать, и самое время съехать наpyodbc.
Посмотрим, чем Airflow нашпиговал аргументы наших функций:
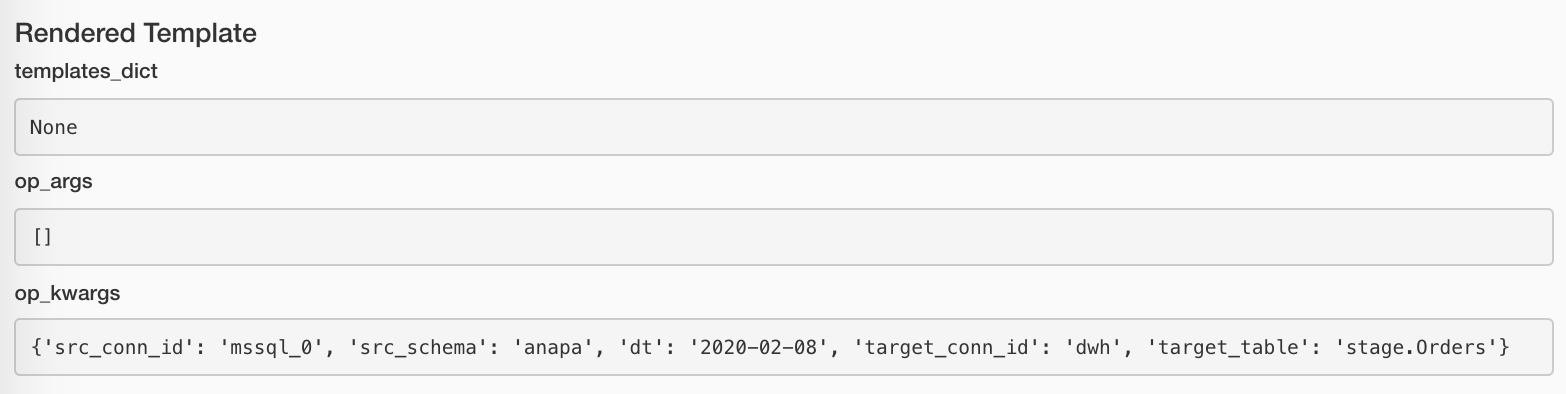
Если данных не оказалось, то продолжать смысла нет. Но считать заливку успешной тоже странно. Но это и не ошибка. А-а-а, что делать?! А вот что:
if df.empty:
raise AirflowSkipException('No rows to load')AirflowSkipException скажет Airflow, что ошибки, собственно нет, а таск мы пропускаем. В интерфейсе будет не зеленый и не красный квадратик, а цвета pink.
Подбросим нашим данным несколько колонок:
df['etl_source'] = src_schema
df['etl_id'] = session.id
df['hash_id'] = hash_pandas_object(df[['etl_source', 'id']])А именно:
Остался предпоследний шаг: залить всё в Vertica. А, как ни странно, один из самых эффектных эффективных способов сделать это — через CSV!
# Export data to CSV buffer
buffer = StringIO()
df.to_csv(buffer,
index=False, sep='|', na_rep='NUL', quoting=csv.QUOTE_MINIMAL,
header=False, float_format='%.8f', doublequote=False, escapechar='\\')
buffer.seek(0)
# Push CSV
target_conn = VerticaHook(vertica_conn_id=target_conn_id).get_conn()
copy_stmt = f"""
COPY {target_table}({df.columns.to_list()})
FROM STDIN
DELIMITER '|'
ENCLOSED '"'
ABORT ON ERROR
NULL 'NUL'
"""
cursor = target_conn.cursor()
cursor.copy(copy_stmt, buffer)StringIO.pandas любезно сложит в него наш DataFrame в виде CSV-строк.copy() отправим наши данные прямо в Вертику!Из драйвера заберем, сколько строчек засыпалось, и скажем менеджеру сессии, что всё ОК:
session.loaded_rows = cursor.rowcount
session.successful = TrueВот и всё.
На проде мы создаем целевую табличку вручную. Здесь же я позволил себе небольшой автомат:
create_schema_query = f'CREATE SCHEMA IF NOT EXISTS {target_schema};'
create_table_query = f"""
CREATE TABLE IF NOT EXISTS {target_schema}.{target_table} (
id INT,
start_time TIMESTAMP,
end_time TIMESTAMP,
type INT,
data VARCHAR(32),
etl_source VARCHAR(200),
etl_id INT,
hash_id INT PRIMARY KEY
);"""
create_table = VerticaOperator(
task_id='create_target',
sql=[create_schema_query,
create_table_query],
vertica_conn_id=target_conn_id,
task_concurrency=1,
dag=dag)Я с помощью VerticaOperator() создаю схему БД и таблицу (если их еще нет, естественно). Главное, правильно расставить зависимости:for conn_id, schema in sql_server_ds:
load = PythonOperator(
task_id=schema,
python_callable=workflow,
op_kwargs={
'src_conn_id': conn_id,
'src_schema': schema,
'dt': '{{ ds }}',
'target_conn_id': target_conn_id,
'target_table': f'{target_schema}.{target_table}'},
dag=dag)
create_table >> load— Ну вот, — сказал мышонок, — не правда ли, теперь
Ты убедился, что в лесу я самый страшный зверь?
Джулия Дональдсон, «Груффало»
Думаю, если бы мы с моими коллегами устроили соревнование: кто быстрее составит и запустит с нуля ETL-процесс: они со своими SSIS и мышкой и я с Airflow… А потом бы мы еще сравнили удобство сопровождения… Ух, думаю, вы согласитесь, что я обойду их по всем фронтам!
Если же чуть-чуть посерьезнее, то Apache Airflow — за счет описания процессов в виде программного кода — сделал мою работу гораздо удобнее и приятнее.
Его же неограниченная расширяемость: как в плане плагинов, так и предрасположенность к масштабируемости — даёт вам возможность применять Airflow практически в любой области: хоть в полном цикле сбора, подготовки и обработки данных, хоть в запуске ракет (на Марс, конечно же).
start_date. Да, это уже локальный мемасик. Через главный аргумент дага start_date проходят все. Кратко, если указать в start_date текущую дату, а в schedule_interval — один день, то DAG запустится завтра не раньше.
start_date = datetime(2020, 7, 7, 0, 1, 2)И больше никаких проблем.
С ним же связана и еще одна ошибка выполнения: Task is missing the start_date parameter, которая чаще всего говорит о том, что вы забыли привязать к оператору даг.
Всё на одной машине. Да, и базы (самого Airflow и нашей обмазки), и веб-сервер, и планировщик, и воркеры. И оно даже работало. Но со временем количество задач у сервисов росло, и когда PostgreSQL стал отдавать ответ по индексу за 20 с вместо 5 мс, мы его взяли и унесли.
LocalExecutor. Да, мы сидим на нём до сих пор, и мы уже подошли к краю пропасти. LocalExecutor’а нам до сих пор хватало, но сейчас пришла пора расшириться минимум одним воркером, и придется поднапрячься, чтобы переехать на CeleryExecutor. А ввиду того, что с ним можно работать и на одной машиной, то ничего не останавливает от использования Celery даже не сервере, который «естественно, никогда не пойдет в прод, чесслово!»
Неиспользование встроенных средств:
Злоупотребление почтой. Ну что тут сказать? Были настроены оповещения на все повторы упавших тасков. Теперь в моём рабочем Gmail >90k писем от Airflow, и веб-морда почты отказывается брать и удалять больше чем по 100 штук за раз.
Больше подводных камней: Apache Airflow Pitfails
Для того чтобы нам еще больше работать головой, а не руками, Airflow заготовила для нас вот что:
REST API — он до сих пор имеет статус Experimental, что не мешает ему работать. С его помощью можно не только получать информацию о дагах и тасках, но остановить/запустить даг, создать DAG Run или пул.
CLI — через командную строку доступны многие средства, которые не просто неудобны в обращении через WebUI, а вообще отсутствуют. Например:
backfill нужен для повторного запуска инстансов тасков.airflow backfill -s '2020-01-01' -e '2020-01-13' ordersinitdb, resetdb, upgradedb, checkdb.run, который позволяет запустить один инстанс таска, да еще и забить на всё зависимости. Более того, можно запустить его через LocalExecutor, даже если у вас Celery-кластер.test, только еще и в баз ничего не пишет.connections позволяет массово создавать подключения из шелла.Python API — довольно хардкорный способ взаимодействия, который предназначен для плагинов, а не копошения в нём ручёнками. Но кто ж нам помешает пойти в /home/airflow/dags, запустить ipython и начать беспредельничать? Можно, например, экспортировать все подключения таком кодом:
from airflow import settings
from airflow.models import Connection
fields = 'conn_id conn_type host port schema login password extra'.split()
session = settings.Session()
for conn in session.query(Connection).order_by(Connection.conn_id):
d = {field: getattr(conn, field) for field in fields}
print(conn.conn_id, '=', d)Подключение к базе метаданных Airflow. Писать в неё я не рекомендую, а вот доставать состояния тасков для различных специфических метрик можно значительно быстрее и проще, чем через любой из API.
Скажем, далеко не все наши таски идемпотентны, а могут иногда падать и это нормально. Но несколько завалов — это уже подозрительно, и надо бы проверить.
WITH last_executions AS (
SELECT
task_id,
dag_id,
execution_date,
state,
row_number()
OVER (
PARTITION BY task_id, dag_id
ORDER BY execution_date DESC) AS rn
FROM public.task_instance
WHERE
execution_date > now() - INTERVAL '2' DAY
),
failed AS (
SELECT
task_id,
dag_id,
execution_date,
state,
CASE WHEN rn = row_number() OVER (
PARTITION BY task_id, dag_id
ORDER BY execution_date DESC)
THEN TRUE END AS last_fail_seq
FROM last_executions
WHERE
state IN ('failed', 'up_for_retry')
)
SELECT
task_id,
dag_id,
count(last_fail_seq) AS unsuccessful,
count(CASE WHEN last_fail_seq
AND state = 'failed' THEN 1 END) AS failed,
count(CASE WHEN last_fail_seq
AND state = 'up_for_retry' THEN 1 END) AS up_for_retry
FROM failed
GROUP BY
task_id,
dag_id
HAVING
count(last_fail_seq) > 0Ну и естественно первые десять ссылок из выдачи гугла содержимое папки Airflow из моих закладок.
default arguments и params в шаблонах, а также о Variables и Connections.docker-compose.И ссылки, задействованные в статье:
docker-compose для экспериментов, отладки и не только.