Анализ рынка недвижимости методом случайного леса
- понедельник, 29 мая 2017 г. в 03:13:47
Решалась задача анализа текущих предложений на минском рынке недвижимости с целью поиска недооцененных квартир. В качестве источника информации был выбран сайт риэлтерского агентства "Твоя столица".
План статьи:
Для сбора информации по представленным квартирам с сайта агентства использовался Scrapy.
Вначале — в соответствии с туториалом
scrapy startproject tutorialimport scrapy
def extract_item_content(item, selection_expression, skip_chars=None):
content = item.css(selection_expression).extract_first()
if skip_chars and content:
return content.strip(skip_chars)
return content
class TvojaStolicaSpider(scrapy.Spider):
name = "t-s"
start_urls = ['http://www.t-s.by/buy/flats/']
def parse(self, response):
for item in response.css('ul.apart_body li.apart_item'):
details_page_url = extract_item_content(item, 'div.item_descr h4 a::attr(href)')
yield response.follow(details_page_url, callback=self.parse_details)
next_page = response.css('li.arr a.page-lnk::attr(href)').extract_first()
if next_page is not None:
yield response.follow(next_page, callback=self.parse)
def parse_details(self, response):
params = {}
for item in response.css('ul.about_params li.about_param'):
key = item.css('div.param_name::text').extract_first()
value = extract_item_content(item, 'div.param_descr::text', '\n\t ')
if key == u'Микрорайон':
value = extract_item_content(item, 'div.param_descr a::text', '\t')
params[key] = value
params[u'Цена'] = response.css('div.about_price_ye::text').extract_first()
params[u'Описание'] = response.css('div.about_descr p::text').extract_first()
return paramsВ нем указали "t-s" в качестве имени "паука" и url стартовой страницы. Из-за пейджинга она содержит не все ссылки на страницы с детальным описанием квартир, поэтому используем две callback-функции:
Добавили параметр в settings.py:
FEED_EXPORT_ENCODING = 'utf-8'Командой
scrapy crawl t-s -o result.jsonгде t-s — имя "паука", а result.json — выходной файл.
В соответствии с документацией, "в силу исторических причин" spyder дописывает в конец существующего файла при каждом запуске вместо пересоздания нового. Поэтому если хотим каждый раз пересоздавать файл — можно сделать так:
scrapy crawl t-s -t json --nolog -o - > result.jsonно лишимся логов в консоли.
Теперь можем перейти к следующему этапу:
import json
import pandas as pd
import numpy as np
with open('result.json') as data_file:
data = json.load(data_file)
df = pd.io.json.json_normalize(data)
# Изменяем максимальное кол-во отображаемых строк и столбцов:
pd.set_option('display.max_columns', 200)
pd.set_option('display.max_rows', 25)df.shape(410, 20)— На старте имеем 410 записей и 20 признаков
df.index = df[u'Код объекта'].apply(pd.to_numeric)
del df[u'Код объекта']df.ix[818272]Адрес Ташкентская ул., 24 корпус 3
Балкон лоджия застекленная
Ближайшее метро NaN
Год капитального ремонта 0
Год постройки 1977
Город Минск
Комнаты 3
Материал стен блок-комнаты
Микрорайон Чижовка
Описание Комната в трехкомнатной квартире в микрорайоне...
Площади 71.4 / 13.95 / 9.16
Полы линолеум
Район Заводской район
Санузел раздельный
Телефон есть
Тип дома стандартные
Условия продажи чистая продажа
Цена 15 500 у. е.
Этаж / Этажность 2/9df.ix[818272][{u'Адрес',u'Цена',u'Этаж / Этажность'}]Цена 15 500 у. е.
Этаж / Этажность 2/9
Адрес Ташкентская ул., 24 корпус 3Это полезно, потому что в силу устройства сайта t-s.by код квартиры 818272 участвует в url:
http://www.t-s.by/buy/flats/818272/, поэтому при необходимости можно быстро посмотреть детали заинтересовавшей квартиры в браузере.
df.columnsIndex([u'Адрес', u'Балкон', u'Ближайшее метро', u'Год капитального ремонта',
u'Год постройки', u'Город', u'Комнаты', u'Материал стен', u'Микрорайон',
u'Описание', u'Площади', u'Полы', u'Район', u'Санузел', u'Телефон',
u'Тип дома', u'Условия продажи', u'Цена', u'Этаж / Этажность'],
dtype='object')df[u'Город'].value_counts()[:10]Минск 354
Лесной 8
Прилуки 6
Заславль 6
Дзержинск 6
Фаниполь 4
Боровляны 4
Михановичи 3
Радошковичи 2
Свислочь 1df = df[df[u'Город'] == u'Минск']
del df[u'Город']Некоторые столбцы не будут участвовать в конечной модели, но не удаляем их раньше времени
В итоговой модели этот столбец использоваться не будет, решено полагаться на реальные параметры квартиры, а не ее субъективное описание владельцем/риелтором
Содержит название улицы и номер дома, в итоговой модели не используется, локация влиять на цену будет посредством столбцов 'Район' и 'Микрорайон'
df[u'Балкон'].fillna(u'нету', inplace=True)
df[u'Балкон'].value_counts()лоджия застекленная 167
балкон застекленный 62
2 лоджии застекленные 37
нету 36
балкон 28
лоджия 8
2 балкона застекленные 5
2 лоджии 3
лоджия застекленная + вагонка 3
3лз 3
3л 1
балкон застекленный + вагонка 1Сократим разнообразие значений в столбце:
def common_converter(mapping, param):
if param in mapping:
return mapping[param]
return param
balcony_mapping = {
u'балкон застекленный':u'балкон',
u'лоджия застекленная':u'лоджия',
u'лоджия застекленная + вагонка':u'лоджия',
u'балкон застекленный + вагонка':u'балкон',
u'2 балкона застекленные':u'2 балкона',
u'2 лоджии застекленные':u'2 лоджии',
u'3лз':u'3 лоджии',
u'3л':u'3 лоджии'
}
df[u'Балкон'] = df[u'Балкон'].map(lambda x: common_converter(balcony_mapping, x))
df[u'Балкон'].value_counts()лоджия 178
балкон 91
2 лоджии 40
нету 36
2 балкона 5
3 лоджии 4df[u'Ближайшее метро'].fillna(u'нету', inplace=True)
df[u'Ближайшее метро'].value_counts()нету 156
Уручье 22
Каменная горка 21
Грушевка 18
Кунцевщина 16
Академия наук 13
Спортивная 10
Могилевская 10
Малиновка 10
Победы пл. 10
Якуба Коласа пл. 9
Восток 6
...
Пушкинская 5
Петровщина 5
Молодежная 4
Парк Челюскинцев 4
Пролетарская 3
Купаловская (Октябрьская) 3
Московская 3
Михалово 2
Тракторный завод 2
Первомайская 2
Фрунзенская 2
Немига 1Закономерно: в Уручье и Грушевке много новостроек, а в районе Каменной горки и Кунцевщины не так давно строилось много льготного жилья, которое продают теперь уже нельготники :)
# Вместо данных столбцов введем другие: 'Лет дому' и 'Лет с момента ремонта':
df[u'Год постройки'] = df[u'Год постройки'].apply(pd.to_numeric)
df[u'Год капитального ремонта'] = df[u'Год капитального ремонта'].apply(pd.to_numeric)
import datetime
current_year = datetime.datetime.now().year
def years_from_last_repair(row):
if row[u'Год капитального ремонта'] == 0:
row[u'Год капитального ремонта'] = row[u'Год постройки']
return current_year - row[u'Год капитального ремонта']
df[u'Лет дому'] = df[u'Год постройки'].map(lambda x: current_year - x)
df[u'Лет с момента ремонта'] = df.apply(lambda row: years_from_last_repair(row), axis=1)
# Добавим столбец с флажком - был ли капремонт
df[u'Был капремонт'] = df[u'Год капитального ремонта']!=0
# Исходные два столбца удаляем:
df.drop({u'Год постройки', u'Год капитального ремонта'}, axis=1, inplace=True)df[u'Комнаты'].value_counts()1/1 106
2/2 101
3/3 85
4/4 14
3/2 11
3/1 9
2/1 7
2 6
3 4
4/1 3
4 2
4/3 2
6/6 1
4/2 1
5/5 1
1/2 1Если в этом столбце первое число меньше второго — то это продается комната, а не квартира. Отбрасываем такие записи:
df = df[df[u'Комнаты'] != '1/2']# Выделяем кол-во комнат:
df[u'Комнаты'] = df[u'Комнаты'].map(lambda x: x if x.find('/') == -1 else x.split('/')[0])
df[u'Комнаты'] = df[u'Комнаты'].apply(pd.to_numeric)
df[u'Комнаты'].value_counts()2 114
3 109
1 106
4 22
6 1
5 1— больше всего продается 2,3,1-комнатных
# Среднее кол-во комнат:
np.mean(df[u'Комнаты'])2.1529745042492916df[u'Материал стен'].value_counts()панельный 160
кирпичный 100
каркасно-блочный 37
блок-комнаты 21
силикатно-блочный 19
монолитный 16— здесь все в порядке, пропусков нет
df[u'Район'].value_counts()Фрунзенский район 85
Первомайский район 55
Московский район 52
Ленинский район 36
Заводской район 34
Советский район 28
Центральный район 26
Октябрьский район 21
Партизанский район 16— указан у всех записей
df[u'Микрорайон'].value_counts()Малиновка 18
Уручье 18
Серебрянка 17
Сухарево 17
Р.Люксембург, К.Либкнехта 15
Кунцевщина 13
Ангарская 11
Чижовка 10
Червякова, Шевченко 10
Каменная горка 9
Пушкина, Глебки, Притыцкого, Ольшевского, Кальварийская 9
Масюковщина 9
..
Дружба, Брилевичи 2
Тракторный Завод 2
Кижеватова, Асаналиева 2
Дзержинского, Хмелевского, Щорса 2
Ванеева, Партизанский 1
Сельхоз посёлок 1
Район ДК "МАЗ" 1
Седых, Тикоцкого 1
Багратиона, Менделеева, Уральская 1
Сосны 1
Немига, Короля 1
Веснянка 1# Заменим пропущенные значения строкой 'Не указан':
df[u'Микрорайон'].fillna(u'Не указан', inplace=True)df[u'Общая площадь'] = df[u'Площади'].map(lambda x: float(x.split(' / ')[0]))
df[u'Жилая площадь'] = df[u'Площади'].map(lambda x: float(x.split(' / ')[1]))
df[u'Площадь кухни'] = df[u'Площади'].map(lambda x: float(x.split(' / ')[2]))
# Удаляем столбец 'Площади':
df = df.drop(u'Площади', axis=1)# Среднияя площадь типичной квартиры на рынке
np.mean(df[u'Общая площадь']), np.mean(df[u'Жилая площадь']), np.mean(df[u'Площадь кухни'])(60.66762039660057, 35.14807365439093, 8.711161473087818)df[u'Полы'].value_counts()ламинированые 105
линолеум 104
паркет 55
деревянные 36
ДСП 3
ковровое покрытие 2df[u'Полы'].fillna(u'Не указано', inplace=True)При помощи
df[df[u'Санузел'].isnull()]находим один дом, в котором судя по всему санузла действительно нету, его функции выполняет здание на улице рядом. Дом 1949го года, без капремонта, неинтересен, поэтому отбрасываем его:
df.drop(821155, inplace=True)toilet_mapping = {
u'2 сан.узла':u'раздельный',
u'3 сан.узла':u'раздельный'
}
df[u'Санузел'] = df[u'Санузел'].map(lambda x: common_converter(toilet_mapping, x))
df[u'Санузел'].value_counts()раздельный 268
совмещенный 84df[u'Телефон'].value_counts()есть 273
нет 78
2 телефона 1df[u'Телефон'] = df[u'Телефон'].map(lambda x: common_converter({u'2 телефона':u'есть'}, x))df[u'Тип дома'].value_counts()новостройка 78
стандартные 49
улучшеный проект 45
брежневка 29
хрущевка 21
сталинка 19
чешский проект 13df[u'Тип дома'].fillna(u'не указан', inplace=True)df[u'Условия продажи'].value_counts()чистая продажа 234
подбираются варианты 57
обмен 7
обмен - разъезд 1df[u'Условия продажи'].fillna(u'не указан', inplace=True)
df[u'Условия продажи'] = df[u'Условия продажи'].map(lambda x: common_converter({u'обмен - разъезд':u'обмен'}, x))# Очищаем столбец 'price' и приводим к числовому:
# u'12 000 у. е. somestring' -> u'12 000' -> u'12000' -> 12000.0
df[u'Цена'] = df[u'Цена'].map(lambda x: float(x[:x.find(u' у. е.')].replace(' ','')))%matplotlib inline
import seaborn as sns
# Распределение квартир по цене:
sns.distplot(df[u'Цена']/1000);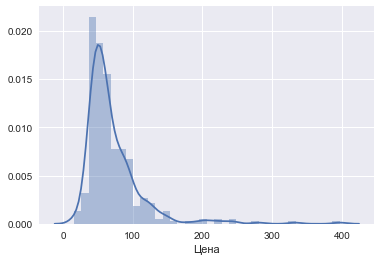
# Квартир в правой части "хвоста" распределения слишком мало.
# Ограничим выборку только квартирами стоимостью ниже некого порога, скажем 150 тыс у.е.:
df = df[df[u'Цена'] < 150000]Позже выяснилось, что среди данных есть также записи, соответствующие комнатам, а не квартирам. Поэтому было решено отбросить записи с ультранизкой ценой. В качестве порога было выбрано значение 35 тыс у.е.:
df[df[u'Цена'] < 35000][u'Описание']Код объекта
818272 Комната в трехкомнатной квартире в микрорайоне...
822608 Две комнаты в трехкомнатной квартире. Стеклопа...
847586 Однокомнатная квартира в кирпичном доме. Комна...
844689 Дом находится в микрорайоне с хорошо развитой ...
834349 Однокомнатная квартира по привлекательной цен...
836501 Комната 17.6 метра в двухкомнатной квартире с ...
787265 Две комнаты 16 и 8.8 м2 (46/100 доли) в четыре...
777826 27/100 доли в четырёхкомнатной квартире. В пра...
829281 Комната с балконом в трехкомнатной квартире. О...
846239 1-на комнатная квартира на 4-ом этаже 5-ти эта...
830075 Кирпичный дом в Центральном районе. В квартире...— видим, что здесь действительно либо комнаты, либо 'кирпичный дом', что не является целью нашего анализа
# Оставляем только квартиры стоимостью выше порога:
df = df[df[u'Цена'] > 35000]# Распределение квартир теперь выглядит так:
sns.distplot(df[u'Цена']/1000);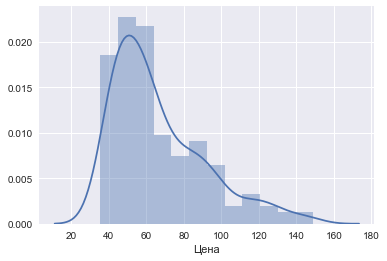
При помощи
df[df[u'Этаж / Этажность'].isnull()]убеждаемся, что для одной из квартир этаж не указан. Судя из того, что тип дома — чешский, этажей в доме 9. Этаж укажем в середине дома, т.к. судя цене в 52 тыс. он не крайний:
df.loc[df[u'Этаж / Этажность'].isnull(), u'Этаж / Этажность'] = u'5/9'df.ix[847125]Адрес Одинцова ул., 69
Балкон 2 лоджии
Ближайшее метро Каменная горка
Комнаты 1
Материал стен кирпичный
Микрорайон Не указан
Описание Однокомнатная квартира в кирпичном доме 1995 г...
Полы паркет
Район Фрунзенский район
Санузел раздельный
Телефон нет
Тип дома чешский проект
Условия продажи чистая продажа
Цена 52000
Этаж / Этажность 5/9
Лет дому 22
Лет с момента ремонта 22
Был капремонт False
Общая площадь 43.9
Жилая площадь 18.3
Площадь кухни 8.8df[u'Этаж'] = df[u'Этаж / Этажность'].map(lambda x: int(x.split('/')[0]))
df[u'Этажность'] = df[u'Этаж / Этажность'].map(lambda x: int(x.split('/')[1]))df[u'Этаж'].value_counts()2 53
5 43
1 36
4 36
3 31
9 24
7 22
6 21
8 19
12 8
10 6
11 6
19 5
18 5
14 3
17 3
16 2
13 1
20 1sns.distplot(df[u'Этаж'], kde=False, bins=20);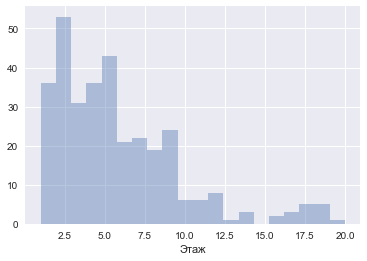
— Преобладают квартиры на нижних этажах по 5й
df[u'Этажность'].value_counts()9 128
5 59
12 25
19 25
10 20
4 16
20 10
2 7
7 6
16 5
13 4
14 3
8 3
3 3
11 2
21 2
24 1
15 1
17 1
18 1
6 1
22 1
25 1sns.distplot(df[u'Этажность'], kde=False);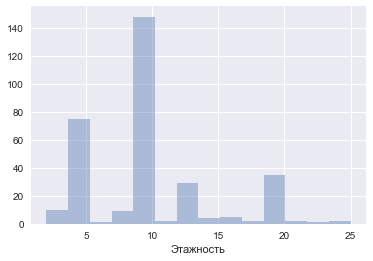
— больше всего квартир в 9 и 5-этажках
np.median(df[u'Этаж']), np.median(df[u'Этажность'])(5.0, 9.0)— т.е. в среднем квартира расположена на 5 этаже 9-этажного дома
df[u'Первый этаж'] = df[u'Этаж'].map(lambda x: 1 if x==1 else 0)df[u'Первый этаж'].value_counts()0 289
1 36df[u'Последний этаж'] = df[u'Этаж / Этажность'].map(lambda x: 1 if x.split('/')[0] == x.split('/')[1] else 0)
df[u'Последний этаж'].value_counts()0 276
1 49# Удаляем столбец 'Этаж / Этажность':
df = df.drop(u'Этаж / Этажность', axis=1)df.info()Data columns (total 24 columns):
Адрес 325 non-null object
Балкон 325 non-null object
Ближайшее метро 325 non-null object
Комнаты 325 non-null int64
Материал стен 325 non-null object
Микрорайон 325 non-null object
Описание 322 non-null object
Полы 325 non-null object
Район 325 non-null object
Санузел 325 non-null object
Телефон 325 non-null object
Тип дома 325 non-null object
Условия продажи 325 non-null object
Цена 325 non-null float64
Лет дому 325 non-null int64
Лет с момента ремонта 325 non-null int64
Был капремонт 325 non-null bool
Общая площадь 325 non-null float64
Жилая площадь 325 non-null float64
Площадь кухни 325 non-null float64
Этаж 325 non-null int64
Этажность 325 non-null int64
Первый этаж 325 non-null int64
Последний этаж 325 non-null int64X = df.drop({u'Цена', u'Описание', u'Адрес'}, axis=1)
Y = df[u'Цена']На этом закончим подготовку данных, а начнем собственно
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import OneHotEncoder
# Добавляет в DataFrame df новый столбец с именем column_name+'_le', содержащий номера категорий,
# соответствующие столбцу column_name. Исходный столбец column_name удаляется
#
def encode_with_LabelEncoder(df, column_name):
label_encoder = LabelEncoder()
label_encoder.fit(df[column_name])
df[column_name+'_le'] = label_encoder.transform(df[column_name])
df.drop([column_name], axis=1, inplace=True)
return label_encoder
# Кодирование с использованием ранее созданного LabelEncoder
#
def encode_with_existing_LabelEncoder(df, column_name, label_encoder):
df[column_name+'_le'] = label_encoder.transform(df[column_name])
df.drop([column_name], axis=1, inplace=True)
# Вначале кодирует столбец column_name при помощи LabelEncoder, потом добавляет в DataFrame df новые столбцы
# с именами column_name=<категория_i>. Столбцы column_name и column_name+'_le' удаляются
# Usage: df, label_encoder = encode_with_OneHotEncoder_and_delete_column(df, column_name)
#
def encode_with_OneHotEncoder_and_delete_column(df, column_name):
le_encoder = encode_with_LabelEncoder(df, column_name)
return perform_dummy_coding_and_delete_column(df, column_name, le_encoder), le_encoder
# То же, что предыдущий метод, но при помощи уже существующего LabelEncoder
#
def encode_with_OneHotEncoder_using_existing_LabelEncoder_and_delete_column(df, column_name, le_encoder):
encode_with_existing_LabelEncoder(df, column_name, le_encoder)
return perform_dummy_coding_and_delete_column(df, column_name, le_encoder)
# Реализует Dummy-кодирование
#
def perform_dummy_coding_and_delete_column(df, column_name, le_encoder):
oh_encoder = OneHotEncoder(sparse=False)
oh_features = oh_encoder.fit_transform(df[column_name+'_le'].values.reshape(-1,1))
ohe_columns=[column_name + '=' + le_encoder.classes_[i] for i in range(oh_features.shape[1])]
df.drop([column_name+'_le'], axis=1, inplace=True)
df_with_features = pd.DataFrame(oh_features, columns=ohe_columns)
df_with_features.index = df.index
return pd.concat([df, df_with_features], axis=1)phone_le_converter = encode_with_LabelEncoder(X,u'Телефон')
X, balcony_le_encoder = encode_with_OneHotEncoder_and_delete_column(X,u'Балкон')
X, metro_le_encoder = encode_with_OneHotEncoder_and_delete_column(X,u'Ближайшее метро')
X, wall_materials_le_encoder = encode_with_OneHotEncoder_and_delete_column(X,u'Материал стен')
X, ground_le_encoder = encode_with_OneHotEncoder_and_delete_column(X,u'Полы')
X, region_le_encoder = encode_with_OneHotEncoder_and_delete_column(X,u'Район')
X, subregion_le_encoder = encode_with_OneHotEncoder_and_delete_column(X,u'Микрорайон')
X, toilet_le_encoder = encode_with_OneHotEncoder_and_delete_column(X,u'Санузел')
X, house_type_le_encoder = encode_with_OneHotEncoder_and_delete_column(X,u'Тип дома')
X, sell_conditions_le_encoder = encode_with_OneHotEncoder_and_delete_column(X,u'Условия продажи')X.shape(325, 131)— столбцов с признаками хоть и стало более сотни, но это еще терпимо
В качестве алгоритма для решения был выбран случайный лес.
from sklearn.ensemble import RandomForestRegressor
from sklearn.cross_validation import KFold
from sklearn.cross_validation import cross_val_score
records_count = Y.count()
# Кросс-валидация по 5 блокам с перемешиванием
kf = KFold(n = records_count, n_folds=5, shuffle=True, random_state=1)
from sklearn.model_selection import GridSearchCV
# Мерой качества выбрано среднеквадратичное отклонение
def determine_forest_quality(trees_count):
clf = RandomForestRegressor(n_estimators = trees_count, random_state=1)
return cross_val_score(clf, X, Y, scoring='r2', cv=kf).mean()
for k in range(1,75,5):
quality = determine_forest_quality(k)
print (k, quality)(1, 0.52030399213798784)
(6, 0.78408930021238521)
(11, 0.77670005453090307)
(16, 0.7768642836394235)
(21, 0.78408041490733349)
(26, 0.78620421428818033)
(31, 0.78902652992194366)
(36, 0.78733229366765278)
(41, 0.78844165910326591)
(46, 0.78772597694981916)
(51, 0.79053299052554316)
(56, 0.78934052514939657)
(61, 0.78879625272969778)
(66, 0.78759528635105114)
(71, 0.7900711517951875)Решено было выбрать кол-во деревьев равное 51, при котором обеспечивалась точность 79%.
Подбор параметров деревьев не дал ощутимого прироста качества, его дала в основном предварительная работа с признаками.
clf = RandomForestRegressor(n_estimators = 51, random_state=1)
clf.fit(X, Y)RandomForestRegressor(bootstrap=True, criterion='mse', max_depth=None,
max_features='auto', max_leaf_nodes=None,
min_impurity_split=1e-07, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
n_estimators=51, n_jobs=1, oob_score=False, random_state=1,
verbose=0, warm_start=False)features = X.columns.values
importances = clf.feature_importances_
indices = np.argsort(importances)[::-1]
num_to_plot = 10
feature_indices = [ind+1 for ind in indices[:num_to_plot]]
for i in range(num_to_plot):
print i, features[feature_indices[i]], round(importances[indices[i]],2)0 Жилая площадь 0.66
1 Площадь кухни 0.05
2 Район=Заводской район 0.03
3 Материал стен=силикатно-блочный 0.02
4 Этаж 0.02
5 Был капремонт 0.02
6 Микрорайон=Дзержинского, Хмелевского, Щорса 0.02
7 Полы=паркет 0.02
8 Лет с момента ремонта 0.01
9 Первый этаж 0.01Такие параметры, как 'Жилая площадь', 'Площадь кухни', 'Этаж' и 'Был капремонт' выглядят ожидаемо, а вот некоторые из остальных в топ-10 выглядят интересно — это 'Заводской район', 'микрорайон=Дзержинского' и 'Материал стен=силикатно-блочный'.
predictions = pd.Series(clf.predict(X), index=Y.index)res_info = pd.DataFrame(columns=[u'Ошибка,%',u'Ошибка,$',u'Цена м.кв.'])
for i in Y.index:
error = Y[i] - predictions[i]
rel_error = error/predictions[i]*100
res_info.loc[i] = pd.Series({
u'Ошибка,%':round(rel_error,1),
u'Ошибка,$':int(error),
u'Цена м.кв.':int(Y[i]/X[u'Общая площадь'][i])
})res_info.sort_values(by=u'Ошибка,%')[:5]| Ошибка,% | Ошибка,$ | Цена м.кв. | |
|---|---|---|---|
| 845979 | -15.6 | -9252.0 | 906.0 |
| 838613 | -15.4 | -7649.0 | 961.0 |
| 806952 | -15.1 | -9988.0 | 896.0 |
| 830893 | -13.7 | -10979.0 | 891.0 |
| 798393 | -13.1 | -13560.0 | 1232.0 |
res_info.sort_values(by=u'Ошибка,%', ascending=False)[:5]| Ошибка,% | Ошибка,$ | Цена м.кв. | |
|---|---|---|---|
| 777692 | 20.7 | 23452.0 | 2242.0 |
| 795105 | 18.1 | 10582.0 | 1703.0 |
| 843263 | 16.0 | 18209.0 | 1668.0 |
| 812051 | 15.4 | 15362.0 | 2065.0 |
| 810427 | 14.9 | 16735.0 | 2057.0 |
Как было сказано ранее, детали можно посмотреть в браузере по адресу http://www.t-s.by/buy/flats/code/, где code — код квартиры
Стоит признать, что по сумме факторов данные квартиры выделяются из основной массы.
На этом все!
P.S. Как оказалось, за время с момента выгрузки данных с t-s.by до окончания написания статьи, данное агенство немного изменило шаблон страницы с детальной информацией о квартире: часть полей убрали, остальные переехали. Поэтому не думаю, что сильно им помешаю, предоставив код crawler-а, парсящего прошлую версию их сайта.
Исходный выгруженный json со всеми исходными полями сохранился и находится в репозитории.