http://habrahabr.ru/post/218887/
В данной статье будет рассмотрено построение защиты приложения с использованием различных программных «трюков» таких как: сброс точки входа в ноль, шифрование тела файла и декриптор накрытый мусорным полиморфом, сокрытие логики исполнения алгоритма приложения в теле виртуальной машины.
К сожалению, статья будет достаточно тяжелая для обычного прикладного программиста, не интересующегося тематикой защиты ПО, но тут уж ничего не поделать.
Для более или менее адекватного восприятия статьи потребуется минимальные знания ассемблера (его будет много) а так-же навыков работы с отладчиком.
Но и тем, кто надеется что здесь будут даны какие-то простые шаги по реализации такого типа защиты, придется разочароваться. В статье будет рассмотрен уже реализованный функционал, но… с точки зрения его взлома и полного реверса алгоритма.
Основные цели, которые я ставил перед собой, это дать общее понятие как вообще работает такая защита ПО, но самое главное — как к этому будет подходить человек, который будет снимать вашу защиту, ибо есть старое правило — нельзя реализовать грамотный алгоритм ядра защиты, не представляя себе методы его анализа и взлома.
В качестве реципиента, по совету одного достаточно компетентного товарища, я выбрал немножко старый (но не потерявший актуальности, в силу качества исполнения) keygenme от небезызвестного Ms-Rem.
Вот первоначальная ссылка, где он появился:
http://exelab.ru/f/index.php?action=vthread&forum=1&topic=4732
А потом он попал вот сюда:
http://www.crackmes.de/users/ms_rem/keygenme_by_ms_rem/
Где данному keygenme был выставлена сложность 8 из 10 (*VERY VERY* hard).
Хотя, если честно, это слегка завышенная оценка — я бы поставил в районе 5-6 баллов.
Пожалуй, начнем.
0. Требования
По хорошему, для полноценной отладки данного keygenme, самым удобной площадкой будет Windows XP 32 бита, она вообще является самой оптимальной средой, поэтому постоянно развернута у меня на рабочей станции в виде виртуалки.
Под Windows 7 — 32 бита (на которой собственно и производилась отладка в процессе написания данной статьи) будут небольшие затруднения, но они решаемые (об этом будет упоминание в четвертой главе статьи).
На 64 битных OC начнутся серьезные трудности ввиду того, что используемый в качестве основного инструмент (OllyDebug) при отладке данного Keygenme будет выдавать ошибки еще на этапе работы загрузчика. Этими ошибками не будет сыпать OllyDebug версии 2, но здесь есть еще одно затруднение, для нее пока что нет необходимых плагинов (а может я плохо искал).
Сам keygenme необходимо скачать по этой ссылке:
http://exelab.ru/f/files/3635_03.05.2006_CRACKLAB.rU.tgz (потребуется регистрация).
Для полноценной работы с текстом статьи, если вы решите самостоятельно пройти все шаги, описанные в ней, вам потребуется небольшой набор инструментов.
Я не буду здесь подробно расписывать про них, все что нужно сделать описано в файле «used_tools.txt», размещенном в корне архива с примерами к статье:
http://rouse.drkb.ru/blog/vm_analize.zip
Еще необходимо запомнить правильную пару логина и серийного номера, предоставленную по самой первой ссылке, а именно «Ms-Rem» и «C38FB7A0CF38F73B1159». Эти данные очень сильно помогут в процессе разбора keygenme.
Как только все будет установлено — можно начинать.
1. Первичный анализ
Для начала стоит определиться, с чем именно мы имеем дело.
Запускаем PEiD и открываем в нем keygenme.exe.
Нажимаем самую правую нижнюю кнопку и в меню выберем тип сканирования «Hardcore Scan».
Сразу начинаются неприятности, во первых точка входа «Entrypoint» выставлена в ноль, что в нормальном исполняемом файле быть не может, во вторых сканирование показало что присутствует «UPolyX v0.5 *».
Второе как раз не страшно — вот было бы там что-то наподобие «EXECryptor» или «Themida» — какой-то из коммерческих протекторов, тогда да, а тут просто видимо нашлась какая-то подходящая сигнатура.
Нажимаем вторую справа нижнюю кнопку и в появившемся диалоге три кнопки справа.
Говорит что файл упакован и энтропия аж 7.56.
Ну допустим, хотя это еще ни о чем не говорит. Большая энтропия бывает не только у запакованных, но и у зашифрованных файлов.
Закрываем диалог и щелкаем на кнопку справа от «Subsystem:»
Помимо точки входа убиты базы кода и данных, база загрузки стандартная 4000000.
Ну что же, ладно — на руках у нас файл который немного поправили ручками.
Попробуем пощупать все это в отладчике.
2. Анализируем поведение приложения при Entrypoint = 0
Открываем OllyDebug, заходим в меню «Options», там выбираем «Debugging options» и на вкладке «Events» выставляем галку «Make first pause at: -> System breakpoint».
Таким образом мы заставим отладчик прерваться при получении первого отладочного сообщения до передачи управления в тело отлаживаемого приложения.
Это делается из-за скинутой в ноль точки входа.
Открываем сам keygenme.exe и сразу прерываемся где-то внутри ntdll.dll
Что есть точка входа (для приложения) — это смещение от его базы загрузки (hInstance), на которое загрузчик передает управления сразу после инициализации процесса.
База загрузки всегда содержит в себе PE заголовок, где самой первой идет структура _IMAGE_DOS_HEADER.
Т.к. точка входа у keygenme равна нулю, значит управление будет передано непосредственно на его hInstance.
Зная это, давайте посмотрим что там у нас находится.
Нажимаем «Ctrl+G» и вбиваем адрес базы «400000», должно получится как-то так:
Вполне себе приличный код вместо стандартного заголовка, но заголовок должен быть на месте, иначе приложение не запустилось бы, значит были внесены правки непосредственно в _IMAGE_DOS_HEADER.
Смотрим что именно поменялось:
_IMAGE_DOS_HEADER = record { DOS .EXE header }
e_magic: Word; { Magic number }
e_cblp: Word; { Bytes on last page of file }
e_cp: Word; { Pages in file }
e_crlc: Word; { Relocations }
e_cparhdr: Word; { Size of header in paragraphs }
e_minalloc: Word; { Minimum extra paragraphs needed }
Поле e_magic — его трогать нельзя и оно всегда должно содержать инициалы Марка Збиковски 'MZ' (0x4D, 0x5A).
Собственно оно и не тронуто, а оба этих символа трактуются как инструкции:
DEC EBP // уменьшаем указатель стекового фрейма
POP EDX // читаем значение со стека в регистр EDX
Значение второго поля e_cblp изменено на 0x45, 0x52, что в результате отменяет изменения сделанные первыми двумя инструкциями, восстанавливая правильное состояние стека.
Остальные 4 поля используются для реализации команд MOV + JMP.
Вот на этой картинке это показано более наглядно.
Весь смысл таких манипуляций с _IMAGE_DOS_HEADER и сброшенной точкой входа, это передача управления куда-то внутрь тела приложения по адресу 4053B6.
Т.е. в принципе мы можем уже прямо сейчас открыть keygenme.exe и в соответствующем поле в качестве точки входа указать 53B6 (игнорируя правки в заголовке файла), но правильная ли это точка входа?
3. Разбираем код декриптора тела приложения и распаковываем приложение
Идем по адресу перехода «Ctrl+G» 4056B6 и там видим вот такое:
Вообще сплошной мусор. Что ни строчка, то мусорная инструкция.
К примеру все операторы условных переходов (JG/JPE/JCXZ/JE) являются полным мусором, т.к. не важно выполнится ли условие или нет, переход всегда будет осуществлен на следующую строчку (обратите внимание на адреса прыжков).
Инструкции LEA, MOV, XCNG работают с одним и тем-же регистром не внося никаких изменений в его состояние — мусор.
Инструкции работы с матсопроцессором (FCLEX/FFREE) сбрасывают исключения (которых нет, т.к. работа с матсопроцессором еще не проводилась) освобождают регистры (которые собственно и не заняты) — мусор.
Пролистаем код до конца, чтобы посмотреть, где эта каша из мусора заканчивается.
Просто скролим вниз, пока не доберемся до кода, состоящего из одних нулей:
Ага, а вот похоже и нужный нам адрес 401000, на который идет прыжок, который теоретически может являться оригинальной точкой входа.
Давайте посмотрим что там:
А там у нас код, которого явно не должно быть в Win32 приложении, о чем явно говорят инструкции IN и OUT, которые сгенерируют исключение при их выполнении.
Значит получается, что код на оригинальной точке входа (OEP — Original Entry Point) зашифрован и код в процедуре 53B6 должен его расшифровать перед тем как выполнить финальный прыжок.
Но!!!
Но в процедуре 53B6, как было показано ранее, мусор.
На самом деле там должен быть не только мусор. По всей видимости мы имеем дело с так называемым мусорным полиморфиком, причем в самой простейшей его реализации.
Задача полиморфного движка преобразовать изначальный код заменой оригинальных инструкций на их аналоги (или группы аналогов). С целью затруднения анализа результирующего кода как правило добавляются мусорные блоки инструкций.
Здесь же блоков не наблюдается, генерируются просто мусорные инструкции, плюс в итоге даже если и была замена инструкций на аналоги, то я заметил это только в одном случае. Вполне возможно что тут был применен просто генератор мусора, обильно напихавший его между полезными инструкциями, как знать…
Впрочем, появилась задача — надо среди всего этого мусора от адреса 4053B6 по 406839 (5251 байт — однако) найти полезные инструкции, которые осуществляют декрипт тела приложения.
Сделать это можно двумя способами.
Первый — просмотреть весь код глазками и попытаться найти такие инструкции. Я даже ради интереса попробовал и потратил около 7 минут, в результате даже нашел две таких инструкции, не являющихся мусором. Правда, как оказалось в последствии, одну между ними пропустил, да и после второй найденной дальше искать как-то расхотелось — слишком уж утомительное занятие.
Поэтому пойдем вторым путем, и напишем небольшой скрипт, который поможет убрать весь мусор и оставит только полезную нагрузку.
Сам скрипт расположен в
архиве, идущем со статьей по следующему пути: ".\scripts\fill_trash_by_nop.txt".
Для его запуска должен быть установлен плагин OllyScript.
Запускается скрипт так: необходимо перезапустить keygenme в отладчике и дождаться срабатывания первого ВР внутри NTDLL, после чего в меню «Plugins» выбрать пункт «ODbgScript->Run Script...», в диалоге выбрать файл со скриптом (путь указан выше) и запустить его.
Как только скрипт начнет свою работу можно сходить приготовить себе чай, минут пять свободного времени у вас будет.
Логика работы скрипта проста:
Т.к. мусорные инструкции не изменяют значений регистров (за исключением EIP), то детектирование мусорной инструкции происходит сверкой состояния регистров до и после ее выполнения, если регистры изменились — инструкция выполняет что-то полезное, в противном случае инструкция считается мусорной и вместо нее размещается NOP.
Когда скрипт завершит свою работу и выведет сообщение, можно просмотреть результаты его работы (сам отладчик не останавливайте — он еще нужен).
Весь мусор будет заменен на NOP и на руках у нас останутся только следующие инструкции (нужно пробежаться от 4053B6 по 406839 и выписать в блокнотик все что не NOP):
Первыми двумя строчками будет немного мусора (вызывается sleep с нулевой задержкой).
0040548B PUSH 0
0040548D CALL DWORD PTR DS:[<&kernel32.Sleep>] ; kernel32.Sleep
Ну точнее как — это не совсем мусор, эта строчка заставляет загрузчик при старте процесса подгружать kernel32.dll в адресное пространство процесса, в пару к уже загруженной ntdll.dll, т.к. эта библиотека заявлена в таблице импорта keygenme (как раз в виде одной единственной функции sleep).
Далее пойдет сам код декриптора:
004054B4 MOV ESI,keygenme.00401000 // в ESI помещаем указатель на зашифрованный буфер
0040559D MOV EDI,ESI // в EDI на результирующий
// они равны т.е. расшифрованные данные помещаются туда же
00405677 MOV ECX,1058 // устанавливаем количество итераций цикла.
// Всего расшифруется 16736 байт,
// т.к. зачитываем блоками по 4 байта ($1058 * 4)
004057FE LODS DWORD PTR DS:[ESI] // читаем 4 байта
00405904 NEG EAX // умножаем на -1
00405B69 NOT EAX // выполняем операцию NOT,
// в результате просто уменьшаем EAX на 1
// (NEG + NOT = DEC)
00405D3A BSWAP EAX // инвертируем байты
00405E90 SUB EAX,4FE62125 // отнимаем 0x4FE62125
00406121 XOR EAX,12345 // ксорим на 0x12345
00406256 STOS DWORD PTR ES:[EDI] // результат помещаем обратно
00406442 DEC ECX // уменьшаем значение счетчика итераций
004065C8 JNZ keygenme.004057D9 // переходим в начало цикла (на инструкцию 004057FE LODS)
и непосредственно переход на OEP на котором сейчас остановился отладчик.
00406839 JMP keygenme.00401000
Грубо говоря, если посмотреть инструкции декриптора, тело keygenme расшифровывается вот таким простым алгоритмом:
uses
Classes,
Winsock;
var
I, A: Integer;
M: TMemoryStream;
begin
M := TMemoryStream.Create;
try
M.LoadFromFile('keygenme.exe');
M.Position := 512; // после выравнивания позиция данных байтов будет $1000
for I := 0 to $1058 - 1 do
begin
M.ReadBuffer(A, 4); // LODS
Dec(A); // NEG + NOT
A := htonl(A); // BSWAP
Dec(A, $4FE62125); // SUB
A := A xor $12345; // XOR
M.Position := M.Position - 4;
M.WriteBuffer(A, 4); // STOS
end;
M.SaveToFile('keygenme.exe');
finally
M.Free;
end;
end.
Теперь, чтобы каждый раз не ждать расшифровки файла, необходимо сдампить полученный результат (должен быть установлен плагин OllyDump).
Для этого необходимо перейти на OEP («Ctrl+G» 401000) и поставить там брякпойнт, после чего продолжить выполнение программы.
Как только отладчик остановится на установленном ВР, идем в меню «Plugins», там выбираем «OllyDump->Dump debugged process», откроется вот такой диалог:
Ориентируясь на колонку «Virtual Offset» выставляем базу кода равную 1000, а базу данных равную 7000, снимаем галку «Rebuil import» и нажимаем кнопку «Dump».
В появившемся диалоге указываем новое имя «keygen_unpacked.exe».
Собственно все — вот мы и сняли первый конверт.
Небольшая хитрость:
Вообще сдампить можно было гораздо проще, без рассмотрения исходного кода декриптора и прочего, но раз уж я решил рассматривать все досконально, поэтому на нем тоже нужно было остановиться.
Второй вариант распаковки выглядит следующим образом.
1. Запускаем отладчик и ждем срабатывания первого ВР внутри NTDLL.
2. Переходим на вкладку карты памяти «Alt+M» и на адресе 401000 ставим MBP на запись:
3. Запускаем программу на выполнение, как только прервались на операции записи (это будет инструкция STOS DWORD), опять идем на карту памяти и снимаем MBP, после чего идем на OEP (401000) и там ставим обычный брякпойнт.
4. Ну а как только прервемся на нем — нужно выполнить уже описанные шаги по дампу процесса.
Кстати, если хотите, можете проверить получившийся файл под PEiD, энтропия волшебным образом стала 6.95 — а всего-то просто расшифровали блок данных.
4. Первичный анализ распакованного файла и обход проблемы запуска под Vista и выше.
Теперь будем работать с уже распакованным файлом.
Так как точка входа в нем выставлена правильная, то, чтобы не совершать лишних телодвижений, нужно настроить Olly сделать первую остановку уже не в NTDLL, а непосредственно на точке входа.
Открываем OllyDebug, заходим в меню «Options», там выбираем «Debugging options» и на вкладке «Events» выставляем галку «Make first pause at: -> Entry point of main module».
Открываем keygenme_unpacked.exe и смотрим во что превратился ранее зашифрованный код:
Сразу видим первую «неприятность», первый же вызов CALL идет внутрь самого себя (вызывается адрес 401004, в то время как следующая инструкция начинается только с 4010005).
О таких прыжках я уже рассказывал ранее в этой статье:
«Изучаем отладчик, часть вторая»
Суть такого трюка — запутать дизассемблер и заставить его отобразить не тот код, который будет выполнятся на самом деле. Ничего страшного в таком «трюке нет», просто нажимаем F7 выполняя этот CALL и сразу видим правильный код:
Можно прямо сейчас еще раз сдампить процесс + убрать инструкцию POP EBX для отключения такого «фокуса», но т.к. мешать он не будет — оставим как есть и начинаем анализировать.
Сперва идет блок из пяти инструкций, зачитывающий некие данные из PEB (Process Environment Block), адрес которого всегда расположен в FS:[$30].
Если открыть структуру PEB и посмотреть что означают показанные в коде оффсеты, то получим на руки примерно следующее:
0040100A MOV EAX,DWORD PTR FS:[30] // получаем указатель на PEB
00401010 MOV EAX,DWORD PTR DS:[EAX+C] // читаем значение на PEB->LoaderData
00401013 MOV EAX,DWORD PTR DS:[EAX+1C] // читаем LoaderData->InInitOrder
00401016 MOV EAX,DWORD PTR DS:[EAX] // переходим на структуру _LDR_DATA_TABLE_ENTRY
00401018 MOV EAX,DWORD PTR DS:[EAX+8] // читаем поле DllBase
Таким образом эти пять инструкций ищут hInstance «kernel32.dll», которая будет располагаться по данному адресу, правда под Vista и выше по данному адресу будет расположен hInstance «kernelbase.dll» и с этим будет связана одна неприятная ошибочка.
Инструкция LEA ESI, помещает в ESI указатель на небольшой массив из Ansi строк, размещенных по адресу 004012DE. Это три строки, разделенные нулями: «LoadLibraryA», «ExitProcess» и «VirtualAlloc».
Кстати, совершенно забыл об этом упомянуть ранее, если вы посмотрите на таблицу импорта keygenme.exe то увидите что он импортирует одну единственную функцию kernel32.sleep, остальные отсутствуют. Значит адреса остальных, необходимых для работы, приложение должно найти самостоятельно.
Следующая инструкция LEA EDI, помещает в EDI указатель на буфер, в который будет помещаться адреса найденных функций (это будет виртуальная таблица импорта для kernel32), после чего происходит вызов процедуры по адресу 401198.
На самом деле оба вызова LEA EDI/ESI являются мусором, т.к. эти регистры перезатрутся при вызове процедуры по адресу 401198, но использоваться в ней они будут как раз таким образом, как я описал выше (EDI, точнее EBP+305, в итоге будет содержать адреса функций).
Вкратце, задача процедуры 401198 подготовить регистр ESI, в котором помещается указатель на имя искомой функции, а также регистр EDI в котором размещается указатель на таблицу экспорта библиотеки, hInstance которой мы получили, считав данные из PEB,
после чего вызвать функцию по адресу 4011E2, которая и будет производить поиск по имени.
И вот тут-то нас ждет вторая неприятность, гораздо более серьезная чем трюк с CALL в самом начале.
Самой первой будет искаться «LoadLibraryA», которую «kernelbase.dll» не экспортирует.
Это означает то, что под Windows Vista и выше данный keygenme работать не будет и будет падать при старте.
Можете проверить, исключение поднимется вот тут:
004011EB CMPS BYTE PTR DS:[ESI],BYTE PTR ES:[EDI]
Обойти это достаточно просто, достаточно после старта keygenme, поставить ВР на инструкцию:
0040101B LEA ESI,DWORD PTR SS:[EBP+2DE]
т.е. сразу после получения адреса загрузки библиотеки, и подменить значение в регистре EAX на hInstance библиотеки «kernel32.dll» (правильный адрес можно подсмотреть в карте памяти процесса Alt+M).
После таких манипуляций keygenme запустится штатным образом.
Чтобы такого не делать каждый раз при старте приложения, достаточно будет запустить скрипт из папки ".\scripts\run_at_vista.txt", который будет в автоматическом режиме каждый раз при старте подменять значение EAX на правильное и запускать программу без ошибок.
5. Чтение логина и серийного номера
Теперь пришло время посмотреть, каким образом производится чтение логина и серийного номера в память приложения и какие модификации над ними производятся.
Обычно чтение данных из EDIT происходит посредством функции «GetWindowsText» или «GetDlgItemText», но т.к. вторая функция в итоге все равно вызывает первую, то ставить брякпойнт мы будем именно на «GetWindowsText».
Для этого, после того как keygenme запустился (а также подгрузилась библиотека user32.dll) и появилось его диалоговое окно, переходим в отладчик и ищем все доступные функции во всех модулях:
В появившемся диалоге ищем имя экспортируемой функции «GetWindowsTextA», и в меню выбираем пункт «Follow in Disassembler»:
После этого ставим ВР, переходим в диалог с keygenme и в соответствующие поля вбиваем известные нам логин «Ms-Rem» и серийный номер «C38FB7A0CF38F73B1159».
Нажимаем кнопку «Check» и… останавливаемся на бряке внутри user32 как раз на начале функции «GetWindowsTextA».
Теперь необходимо вернуться к месту ее вызова.
Нажимаем:
1. Ctrl+Shift+F9 — прыгая в конец функции «GetWindowsTextA»
2. F8 — выходим наверх в функцию «GetDlgItemText»
3. Ctrl+Shift+F9 — прыгая в конец функции «GetDlgItemText»
4. F8 — выходим наверх в место вызова
В синей рамке содержится только что произведенный вызов «GetDlgItemText», со следующими параметрами:
hDlg = ESI
nIDDlgItem = 65
lpString = EAX
nMaxCount = $10
Это мы прочитали значение логина в буфер, на который указывал регистр EAX размером в 16 байт, а в красной рамке выделен вызов чтения серийного номера в буфер, на который будет указывать EDI (EBP+414E) размером в 32 байта.
Самое интересное начинается сразу после чтения серийного номера.
За ним идет интересный цикл из 10 итераций, при этом регистр ESI указывает на буфер с только что считанным серийным номером, а EDI на буфер, куда помещается результат:
00401111 MOV ECX,0A // выставляем счетчик цикла
00401116 LODS WORD PTR DS:[ESI] // читаем два символа серийного номера
00401118 CALL keygenme.0040117B // вызываем функцию
0040111D STOS BYTE PTR ES:[EDI] // сохраняем 1 байт
0040111E LOOPD SHORT keygenme.00401116 // переход на следующую итерацию
Т.е. над серийным номером в функции 40117B производятся какие то преобразования, результат которых помещается в EDI.
Данная функция выглядит следующим образом:
Это что-то типа преобразования двух символов из строкового HEX представление в байт.
Если грубо то это аналог Result := StrToInt('$' + Value);
Возьмем к примеру изначальный известный серийный номер: «C38FB7A0CF38F73B1159»
После 10 итераций он будет преобразован в массив с таким содержимым:
var
sn: array [0..9] of Byte = ($C3, $8F, $B7, $A0, $CF, $38, $F7, $3B, $11, $59);
Но т.к. в функции не производится проверки на границы, за которые не должны выходить HEX значения в строковом формате, то есть очень большой диапазон допустимых значений, которые после такого приведения дадут одно и то же число.
К примеру что «C3» что «s1» в результате такого преобразования будут равны 195 (или $C3). Поэтому вот это тоже будет вполне себе валидным серийным номером: "
s18FB7A0CF38F73B1159".
Таким образом делаем вывод: введенный логин зачитывается как есть, а серийный номер после чтения преобразовывается в байтовое представление, причем, т.к. итераций всего 10, то длина серийного номера не должна превышать 20 HEX символов (остальное не будет учитываться).
В принципе эта вся информация, которая нам потребуется, теперь пришло время посмотреть на исходный код keygenme немного под другим углом.
6. Анализируем keygenme под IDA Pro, разбираем VM и получаем ее P-Code
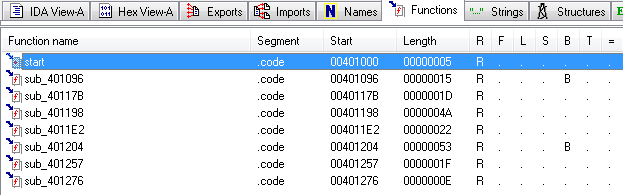
Запускаем IDA Pro и открываем в нем keygenme_unpacked.exe, сразу после открытия идем на вкладку «Functions».
Всего-то 8 штук:
Причем практически все нам известные:
401000 — это OEP, не интересно
401096 — а это похоже изначальная точка входа, которая была до того, как навесили всякое там шифрование и создание виртуальных IAT, но, впрочем, теперь она нам уже не нужна.
40117B — это HexToInt, видели…
401198 — заполнение виртуальной IAT, видели…
4011E2 — поиск адреса функции по имени, видели…
sub_401204 — что-то интересное (судя по графу), с ней пожалуй и начнем, кстати она вызывает две оставшиеся функции sub_401257 и sub_401276.
А вызовы функций чтения из EDIT-ов по адресам 004010F5 и 00401107, а также цикла по адресу 00401111, IDA Pro не распознала как процедуры из-за мусорных инструкций идущих перед ними (да и не столь важно).
Итак, смотрим граф функции sub_401204:
Видели когда нибудь как выглядит граф VM в IDA?
Если нет, то смотрите — это и есть тело виртуальной машины, причем достаточно простой.
Что есть виртуальная машина?
Грубо… обычный процессор выполняет набор известных ему инструкций (машкод, который можно дизассемблировать).
Виртуальная машина — по сути это тоже процессор, только выполняет она свой набор инструкций, которые генерируются и размещаются где-то в доступной ей области памяти в виде так называемого P-Code.
Совсем не обязательно что эти инструкции совпадут с теми, что может исполнить реальный процессор (точнее наоборот — в большинстве случаев они как раз не будут совпадать).
В процессе защиты, коммерческие протекторы дизассемблируют защищаемые блоки кода, генерируют для каждого из них свою виртуальную машину с уникальным набором логики и набором инструкций, переводят дизассемблированный код в пикод, который может выполнить конкретная виртуальная машина и сохраняют результат в виде буфера где-то в теле приложения. Каждая VM, при получении управления в процессе выполнения программы, последовательно зачитывает инструкции пикода, предназначенные только для нее, и исполняет их.
Таким образом от взломщика прячется логика защищаемого алгоритма, которую он мог бы разобрать под отладчиком. После таких модификаций придется сначала проанализировать каждую VM, и только после ее полного анализа вытащить алгоритм из исполняемого ей пикода, преобразовав его обратно в понятный обычному процессору машкод. Работенка та еще…
На картинке выше мы видим как раз одну из реализаций VM, которая может выполнить всего 8 известных ей инструкций.
Давайте рассмотрим поподробнее:
Все начинается с инициализации регистра EBX, который указывает на начало буфера с пикодом для виртуальной машины, а так-же регистра EAX, который является курсором (индексом исполняемой инструкции).
Работа VM начинается с процедуры loc_40120D.
Ее задача, сначала получить опкод выполняемой инструкции, вызовом функции sub_401276, код которой приведен в хинте.
Судя по этому коду можно понять, что сам пикод тоже зашифрован и сразу после считывания каждого байта происходит его декрипт примерно вот таким алгоритмом:
var
A, B: Byte;
...
A := PicodeBuff[I];
B := A;
B := B shr 4;
A := A xor B;
Result := A and 7;
После получения опкода происходит его проверка, если он равен нулю, то передается управление вот сюда:
Где просто прибавляется единица какой-то переменной (назовем ее как есть arg_4)
И в итоге дальше управление перелается на финализирующий блок, который запускает исполнение следующего опкода, инкрементируя регистр EAX.
Причем в нем же мы можем узнать общий размер пикода, он равен $3DA2 (15778 байт).
Итак, разберем все инструкции по порядку:
0. (loc_4012CA): увеличивает значение переменной «arg_4»
1. (loc_4012C5): уменьшает значение переменной «arg_4»
2. (loc_4012BE): увеличивает значение, на которое указывает «arg_4»
3. (loc_4012B7): уменьшает значение, на которое указывает «arg_4»
4. (loc_4012A8): помещает значение, на которое указывает «arg_4» в память на которую указывает «arg_8», после чего увеличивает значение переменной «arg_8»
5 (loc_401299):. помещает значение, на которое указывает «arg_С» в память на которую указывает «arg_4», после чего увеличивает значение переменной «arg_С»
6. (loc_401284): проверяет значение, на которое указывает «arg_4», и если оно равно нулю, запускает процедуру «sub_401257» передавая в EDX значение 1
7. (0040123E): проверяет значение, на которое указывает «arg_4», и если оно не равно нулю, запускает процедуру «sub_401257» передавая в EDX значение -1
А в процедуре «sub_401257» происходит следующее, EDX является направлением сканирования пикода, в случае положительного значения ищется опкод номер 7, соответствующий опкоду номер 6 с учетом вложенности (т.е. если идут 066770 то при вызове из первого опкода 6 курсор EAX установится на нуле, а при вызове из второго опкода 6, EAX будет указывать на вторую семерку).
А в случае если EDX = -1, то сканирование идет в обратную сторону так-же с учетом вложенности.
Вот собственно и вся VM.
Ничего не напоминает?
Угу — это собственно Brainfuck как он есть.
http://ru.wikipedia.org/wiki/Brainfuck
Т.е. получается что внутри keygenme расположен зашифрованный P-Code, который должен быть исполнен на интерпретаторе Brainfuck, который собственно и выступает в качестве виртуальной машины (ну а почему бы и нет?)
Кстати, если вы обратите внимание на описание BF в википедии и реализацию обработчиков в данном варианте интерпретатора, то увидите что четвертый и пятый опкоды (чтение и запись) перепутаны местами.
Ну а раз так, все что нам осталось, это вытащить из тела keygenme сам пикод и больше нам keygenme не нужен, дальше мы сами.
Для того чтобы определить расположение буфера с пикодом, поставим ВР на начале VM и посмотрим на адрес, которым инициализируется EBX.
Запускаем OllyDebug и в нем ставим ВР на адресе 401208.
После срабатывания BP смотрим на значение EBX, это адрес 401380.
Переходим на него в окне дампа и смотрим на HEX значения, первые 8 байт равны «CE44 4E53101708DD».
Теперь открываем keygenme_unpacked.exe в любом HEX редакторе и ищем эти 8 байт.
Размер VM, как мы выяснили ранее 15778 байт.
Копируем 15778 байт начиная с найденных в файл «vm.mem».
Отлично, теперь у нас на руках есть P-Code виртуальной машины, с которым нам предстоит долгая и упорная работа, а сам keygenme вместе с OllyDebug и IDA Pro нам больше не нужны, они свое отработали.
ЗЫ: уже скопированный файл «vm.mem» доступен
в архиве с примерами к статье и расположен в папке ".\data\vm.mem".
Кстати.
В процессе вычитки статьи мне указали на такой момент: в реальном боевом приложении количество функций будет на несколько порядков больше, а как в этом случае определить тело виртуальной машины?
В данной ситуации достаточно будет установить ВР на зачитку внешних данных (логина и серийного номера), от которого будет достаточно легко отследить переход на один из хэндлеров виртуальной машины, либо те же действия выполнить с выходным буфером (ведь что-то VM должна делать и иметь взаимодействие с внешней средой).
Но все это, конечно, зависит от конкретной реализации VM и не всегда этот подход применим.
7. Пишем собственный интерпретатор Brainfuck
Для начала декодируем полученный «vm.mem» в нормальное представление примерно вот таким кодом:
const
BrainFuckOpcode: array [0..7] of AnsiChar = ('>', '<', '+', '-', ',', '.', '[', ']');
const
PicodeBuffSize = 15778;
var
PicodeBuff: array [0..PicodeBuffSize - 1] of Byte;
M: TMemoryStream;
I: Integer;
A, B: Byte;
begin
M := TMemoryStream.Create;
try
M.LoadFromFile('..\..\data\vm.mem');
M.ReadBuffer(PicodeBuff[0], PicodeBuffSize);
for I := 0 to PicodeBuffSize - 1 do
begin
A := PicodeBuff[I];
B := A;
B := B shr 4;
A := A xor B;
PicodeBuff[I] := Byte(BrainFuckOpcode[A and 7]);
end;
M.Clear;
M.WriteBuffer(PicodeBuff[0], PicodeBuffSize);
M.SaveToFile('..\..\data\vm.brainfuck');
finally
M.Free;
end;
Получится файл «vm.brainfuck» содержащий код BF в том виде, в котором он обычно и записывается, причем тут уже учтено что инструкции "." и "," перепутаны местами.
Этот файл в принципе уже можно скармливать любому интерпретатору BF и если подсунуть правильный буфер с логином и серийным номером — он даже выполнится.
Кстати про буфер с логином и серийным номером — совсем забыл про это упомянуть. Он идет на вход виртуальной машине в виде блока из 20 байт, где первые 10 байт заполнены символами логина (если логин меньше 10 байт, остальные байты равны нулю), а сразу за ними идут 10 байт серийного номера преобразованные из строкового HEX представления в байт.
Т.е. для известных нам «Ms-Rem» и «C38FB7A0CF38F73B1159» буфер будет вот таким:
('M', 's', '-', 'R', 'e', 'm', 0, 0, 0, 0, $C3, $8F, $B7, $A0, $CF, $38, $F7, $3B, $11, $59)
Это можно было увидеть при старте виртуальной машины под отладчиком, подсмотрев данные, расположенные по адресу, на который указывала переменная «arg_С».
Для работы интерпретатора BF требуется буфер в 300000 байт (по условиям, описанным в вики), но на самом деле данный вариант кода использует всего 221 байт из 300000.
Собственно пишем код.
Нам нужны 4 буфера, для пикода, для рабочего пространства VM, входной и выходной буфера.const
PicodeBuffSize = 15778;
var
// Буфер с пикодом
PicodeBuff: array [0..PicodeBuffSize - 1] of Byte;
PicodeIndex: Integer;
// Буфер для работы VM
WorkBuff: array [0..220] of Byte;
WorkBuffIndex: Integer;
// Выходной буфер
OutputBuff: array [0..39] of AnsiChar;
OutputBuffIndex: Integer;
// Буфер с логином и серийным номером
LoginAndPwd: array [0..29] of AnsiChar;
LoginAndPwdIndex: Integer;
При старте необходимо загрузить пикод и правильно инициализировать буфер с логином и серийным номером:procedure InitVM;
var
M: TMemoryStream;
begin
M := TMemoryStream.Create;
try
M.LoadFromFile('..\..\data\vm.brainfuck');
M.Read(PicodeBuff[0], PicodeBuffSize);
finally
M.Free;
end;
end;
procedure InitLoginAndPwd(const Login, Password: AnsiString);
var
I: Integer;
A, B: Byte;
begin
// Колируем логин
Move(Login[1], LoginAndPwd[0], Length(Login));
Move(Password[1], LoginAndPwd[10], Min(Length(Password), 20));
// подготавливаем буфер с серийным номером
for I := 0 to 9 do
begin
A := Byte(LoginAndPwd[10 + I * 2]);
B := Byte(LoginAndPwd[11 + I * 2]);
if A > $39 then
Dec(A, $37)
else
Dec(A, $30);
if B > $39 then
Dec(B, $37)
else
Dec(B, $30);
A := a shl 4;
A := A or B;
LoginAndPwd[10 + I] := AnsiChar(A);
end;
end;
После чего необходимо написать сам код интепретатора:procedure RunVM;
var
I: Integer;
Count: Integer;
begin
repeat
case PicodeBuff[PicodeIndex] of
Byte('>'): Inc(WorkBuffIndex);
Byte('<'): Dec(WorkBuffIndex);
Byte('+'): Inc(WorkBuff[WorkBuffIndex]);
Byte('-'): Dec(WorkBuff[WorkBuffIndex]);
Byte('.'):
begin
OutputBuff[OutputBuffIndex] := AnsiChar(WorkBuff[WorkBuffIndex]);
Inc(OutputBuffIndex);
end;
Byte(','):
begin
WorkBuff[WorkBuffIndex] := Byte(LoginAndPwd[LoginAndPwdIndex]);
Inc(LoginAndPwdIndex);
end;
Byte('['):
begin
if WorkBuff[WorkBuffIndex] <> 0 then
begin
Inc(PicodeIndex);
Continue;
end;
Count := 1;
for I := PicodeIndex + 1 to PicodeBuffSize - 1 do
begin
if PicodeBuff[I] = Byte('[') then
begin
Inc(Count);
Continue;
end;
if PicodeBuff[I] = Byte(']') then
begin
Dec(Count);
if Count = 0 then
begin
PicodeIndex := I;
Break;
end;
end;
end;
end;
Byte(']'):
begin
if WorkBuff[WorkBuffIndex] = 0 then
begin
Inc(PicodeIndex);
Continue;
end;
Count := 1;
for I := PicodeIndex - 1 downto 0 do
begin
if PicodeBuff[I] = Byte(']') then
begin
Inc(Count);
Continue;
end;
if PicodeBuff[I] = Byte('[') then
begin
Dec(Count);
if Count = 0 then
begin
PicodeIndex := I;
Break;
end;
end;
end;
end;
end;
Inc(PicodeIndex);
until PicodeIndex = PicodeBuffSize;
end;
Осталось только все это запустить:
InitVM;
InitLoginAndPwd('Ms-Rem', 'C38FB7A0CF38F73B1159');
RunVM;
Writeln(PAnsiChar(@OutputBuff[0]));
Readln;
Запускаем и смотрим на результат:
Ну что ж, похоже все сделано правильно и работает так как надо.
(Исходный код интерпретатора
в архиве c примерами '.\tools\bf_execute\')
Таким образом — второй конверт снят.
Но что теперь нам со всем этим делать?
Анализировать в лоб пикод не получится — нет инструментов, единственно что можно подсмотреть, это номера ячеек в которые заносится логин и пароль и из каких выводится результат.
Ставим ВР на процедурах чтения и записи и смотрим что у нас выйдет…
Да ничего хорошего, в тот момент когда читается данные логина и серийного номера, каждый байт читается всегда в ячейку номер шесть рабочего буфера.
То же происходит и с выводом данных из VM, очередной символ забирается так же из ячейки номер шесть.
Единственное, что может нам хоть как-то прояснить картинку, это дамп рабочего буфера в момент вывода данных, посмотрите на него:
Тут хотя бы видно, что в рабочем буфере VM находится логин и пароль, а так-же чуть ниже него две уже подготовленных строки с «хорошим сообщением» и «плохим».
А в шестой ячейке рабочего буфера (вторая справа сверху) уже сидит подготовленный символ «С» из выводимого сообщения «Congratulations!!! It is valid serial!»
Вот такая засада.
8. Пишем декомпилятор Brainfuck
Что есть декомпилятор?
По сути, это утилита, преобразующая набор машкодов для процессора, в понятный программисту набор ассемблерных инструкций. Для каждого процессора это будет свой ассемблер (32/64/ARM и т.д.). Ну а виртуальная машина (как говорилось ранее) тот же процессор со своим набором инструкций, выраженных в виде пикода.
Сейчас стоит задача, написать декомпилятор пикода в 32-битный ассемблер, чтобы с результатом можно было хоть как-то работать, благо в этом случае инструмент для анализа у нас уже есть — это отладчик.
Причем задача то по сути простая, не нужно учитывать префиксы, парсить ModRM/SIB — всего-то восемь инструкций, но для начала нужно разобраться как это будет выглядеть.
Дизассемблировать в лоб будет не удачной затеей, нужно сворачивать блоки повторяющихся инструкций пикода BF.
К примеру у нас есть brainfuck скрипт такого вида: ">>>+++<<----"
Здесь происходит переход к четвертой ячейке, увеличение ее значения на три, переход ко второй и уменьшение ее значения на четыре.
Если дизассемблировать в лоб, то получится что-то невнятное:
inc eax
inc eax
inc eax
inc byte ptr [eax]
inc byte ptr [eax]
inc byte ptr [eax]
dec eax
dec eax
dec byte ptr [eax]
dec byte ptr [eax]
dec byte ptr [eax]
dec byte ptr [eax]
Гораздо проще свернуть повторяющиеся наборы инструкций:
add eax, 3
add byte ptr [eax], 3
sub eax, 2
sub byte ptr [eax], 4
Ввод и вывод ассемблируются достаточно просто.
Нам нужно только знать откуда читать и куда выводить. Причем нужно учитывать что каждый раз при чтении или выводе данных нужно сдвигать позицию, чтобы не прочитать то, что уже было прочитано или не записать поверх уже записанного.
Остался только вариант со скобками.
Скобки в BF выполняют аналог цикла while, т.е. пока ячейка не равна нулю происходит выполнение тела цикла.
За вход в тело цикла отвечает открывающая скобка "[", за переход на следующую итерацию, закрывающая "]".
Т.е. грубо в ассемблере нам нужно предусмотреть два условных перехода, один на вход в цикл, один на переход на следующую итерацию.
До кучи нужен еще как минимум одна вещь, это адрес, куда нужно перейти если условие вхождения в цикл не выполнилось, или если не выполнилось условие перехода на следующую итерацию цикла.
Следующим шагом нужно разобраться как осуществлять дизассемблирование циклов, с учетом описанных выше трех прыжков.
К примеру есть вот такой пикод:
Более удобным для дизассемблирования (по крайней мере для меня) будет вынос тела цикла за пределы основного кода, примерно вот так:
Если подходить таким образом, то от дизассемблера нужно только знать начало и конец каждой процедуры и в цикле декомпилировать тело каждой, вставляя в нужные места прыжки во внутренние циклы.
ЗЫ: Правда, вот сейчас смотрю на эту картинку и понимаю что может наверное и не стоило выносить, ибо лишний прыжок появился, но… лень переписывать.
Ну да ладно, теперь по поводу рабочего буфера и входного/выходного буферов: в качестве указателя на рабочий буфер будет использоваться регистр ESI, он же будет являться и курсором, т.е. на операциях ">" или "<" будет увеличиваться или уменьшаться именно этот регистр.
Указатель на буфер с логином и серийным номером будет хранить регистр EBX, а за выходной буфер будет отвечать регистр EDI.
Пишем код.
Декомпилятору потребуется буфер с пикодом и небольшой список в котором будет хранится начало и конец каждого While цикла.
var
PicodeBuffSize: Integer;
PicodeBuff: array of Byte;
type
TWhileSubProc = record
StartAddr, EndAddr: Integer;
SubProcEndLabel, SubProcStartLabel: string;
end;
TWhileSubProcList = TList<TWhileSubProc>;
Далее нужны несколько утилитарных процедур.
Первая строит сам список, а вторая и третья, возвращает элемент списка ориентируясь на поля StartAddr и EndAddr.function GetWhileSubProcList: TWhileSubProcList;
var
I, A, Z: Integer;
Item: TWhileSubProc;
begin
Result := TWhileSubProcList.Create;
for I := 0 to PicodeBuffSize - 1 do
if PicodeBuff[I] = Byte('[') then
begin
Item.StartAddr := I;
Z := 1;
for A := I + 1 to PicodeBuffSize - 1 do
begin
if PicodeBuff[A] = Byte('[') then
begin
Inc(Z);
Continue;
end;
if PicodeBuff[A] = Byte(']') then
begin
Dec(Z);
if Z = 0 then
begin
Item.EndAddr := A;
Break;
end;
end;
end;
Result.Add(Item);
end;
end;
function IndexAtStart(List: TWhileSubProcList; Value: Integer): Integer;
var
I: Integer;
begin
Result := -1;
for I := 0 to List.Count - 1 do
if List[I].StartAddr = Value then
Exit(I);
end;
function IndexAtEnd(List: TWhileSubProcList; Value: Integer): Integer;
var
I: Integer;
begin
Result := -1;
for I := 0 to List.Count - 1 do
if List[I].EndAddr = Value then
Exit(I);
end;
Теперь основная процедура - декомпилятор указанного извне While блока:procedure DecodeSubRoutine(List: TWhileSubProcList; Index: Integer);
function GetCharSimbol(Value: Integer): string;
begin
if Value < 32 then
Result := ' // #' + IntToHex(Abs(Value), 2)
else
Result := string(' // char "' + AnsiChar(Value) + '"');
end;
const
LabelPfx = '@vm_code_';
var
Count, I: Integer;
SubRoutineName: string;
Item: TWhileSubProc;
begin
if Index >= 0 then
begin
// если декомпилируем while цикл, генерируем ему имя по его адресу
PicodeIndex := List[Index].StartAddr;
SubRoutineName := LabelPfx + IntToHex(PicodeIndex, 4);
MakeAsmCode(SubRoutineName + ':');
Inc(PicodeIndex);
end
else
// в противном случае идет декомпиляция самой главной ветви пикода
SubRoutineName := '@root';
repeat
case PicodeBuff[PicodeIndex] of
// сворачиваем идущие подряд подвижки курсора
Byte('>'), Byte('<'):
begin
Count := 0;
while PicodeBuff[PicodeIndex] in [Byte('>'), Byte('<')] do
begin
if PicodeBuff[PicodeIndex] = Byte('>') then
Inc(Count)
else
Dec(Count);
Inc(PicodeIndex);
end;
if Count = 0 then Continue;
if Count < 0 then
begin
if Count = -1 then
MakeAsmCode(' dec esi')
else
MakeAsmCode(' sub esi, ' + IntToStr(Abs(Count)));
end;
if Count > 0 then
begin
if Count = 1 then
MakeAsmCode(' inc esi')
else
MakeAsmCode(' add esi, ' + IntToStr(Count));
end;
Continue;
end;
// сворачиваем идущие подряд изменения ячейки
Byte('+'), Byte('-'):
begin
Count := 0;
while PicodeBuff[PicodeIndex] in [Byte('+'), Byte('-')] do
begin
if PicodeBuff[PicodeIndex] = Byte('+') then
Inc(Count)
else
Dec(Count);
Inc(PicodeIndex);
end;
if Count = 0 then Continue;
if Count < 0 then
begin
if Count = -1 then
MakeAsmCode(' dec byte ptr [esi]')
else
MakeAsmCode(' sub byte ptr [esi], ' +
IntToStr(Abs(Count)) + GetCharSimbol(Count));
end;
if Count > 0 then
begin
if Count = 1 then
MakeAsmCode(' inc byte ptr [esi]')
else
MakeAsmCode(' add byte ptr [esi], ' +
IntToStr(Count) + GetCharSimbol(Count));
end;
Continue;
end;
// выводим значение ячейки
Byte('.'):
begin
MakeAsmCode(' mov al, byte ptr [esi]');
MakeAsmCode(' mov byte ptr [edi], al');
MakeAsmCode(' inc edi');
end;
// зачитываем значение из входного буфера
Byte(','):
begin
MakeAsmCode(' mov al, byte ptr [ebx]');
MakeAsmCode(' inc ebx');
MakeAsmCode(' mov byte ptr [esi], al');
end;
// вход в цикл While
Byte('['):
begin
I := IndexAtStart(List, PicodeIndex);
Item := List[I];
MakeAsmCode(' cmp byte ptr [esi], 0 // [');
Item.SubProcEndLabel :=
SubRoutineName + '_' + IntToHex(PicodeIndex + 1, 4);
Item.SubProcStartLabel := LabelPfx + IntToHex(PicodeIndex, 4);
// если не ноль, перейти на выполнение кода подпроцедуры
// сразу же за этой инструкцией будет код идущий за соответствующей закрывающей скобкой
MakeAsmCode(' jne ' + Item.SubProcStartLabel);
MakeAsmCode(Item.SubProcEndLabel + ':');
PicodeIndex := Item.EndAddr + 1;
List[I] := Item;
Continue;
end;
// переход на следующую итерацию
Byte(']'):
begin
I := IndexAtEnd(List, PicodeIndex);
MakeAsmCode(' cmp byte ptr [esi], 0 // ]');
// если не ноль, перейти на выполнение кода подпроцедуры
MakeAsmCode(' jne ' + List[I].SubProcStartLabel);
// в противном случае перейти на код следующий за завершением подпроцедуры
MakeAsmCode(' jmp ' + List[I].SubProcEndLabel);
// подпроцедура завершилась - идем на выход
Exit;
end;
end;
Inc(PicodeIndex);
until PicodeIndex = PicodeBuffSize;
// достигнут конец пикода, пишем финализацию
MakeAsmCode(' popa');
MakeAsmCode(' ret');
end;
Осталось в цикле вызвать декомпиляцию каждого While блока:
procedure DecodeVM;
var
I: Integer;
List: TWhileSubProcList;
begin
MakeAsmCode('procedure RunBrainfuck(pWorkBuff, pInBuf, pOutBuf: Pointer);');
MakeAsmCode('asm');
MakeAsmCode(' pusha');
MakeAsmCode(' mov esi, pWorkBuff');
MakeAsmCode(' mov ebx, pInBuf');
MakeAsmCode(' mov edi, pOutBuf');
List := GetWhileSubProcList;
try
DecodeSubRoutine(List, -1);
for I := 0 to List.Count - 1 do
DecodeSubRoutine(List, I);
finally
List.Free;
end;
MakeAsmCode('end;');
end;
И написать код запуска всего этого:
function InitPicode: Boolean;
var
M: TMemoryStream;
begin
Result := False;
if (ParamCount = 0) or not FileExists(ParamStr(1)) then
begin
Writeln('Brainfuck file not found.');
Exit;
end;
M := TMemoryStream.Create;
try
M.LoadFromFile(ParamStr(1));
PicodeBuffSize := M.Size;
SetLength(PicodeBuff, PicodeBuffSize);
M.ReadBuffer(PicodeBuff[0], PicodeBuffSize);
Result := True;
finally
M.Free;
end;
end;
begin
if InitPicode then
begin
AsmCode := TFileStream.Create(ChangeFileExt(ParamStr(1), '.inc'), fmCreate);
try
DecodeVM;
finally
AsmCode.Free;
end;
Writeln('Done.');
end;
Readln;
end.
(Исходный код декомпилятора
в архиве c примерами '.\tools\bf_decompiler\')
Теперь нужно проверить его работу на чем нибудь.
Возьмем к примеру Hello World из вики с таким содержанием:
++++++++++[>+++++++>++++++++++>+++>+<<<<-]>++
.>+.+++++++..+++.>++.<<+++++++++++++++.>.+++.
------.--------.>+.>.
И посмотрим, во что это декомпилируется:
procedure RunBrainfuck(pWorkBuff, pInBuf, pOutBuf: Pointer);
asm
pusha
mov esi, pWorkBuff
mov ebx, pInBuf
mov edi, pOutBuf
add byte ptr [esi], 10 // #0A
cmp byte ptr [esi], 0 // [
jne @vm_code_000B
@root_000C:
inc esi
add byte ptr [esi], 2 // #02
mov al, byte ptr [esi]
mov byte ptr [edi], al
inc edi
inc esi
inc byte ptr [esi]
mov al, byte ptr [esi]
mov byte ptr [edi], al
inc edi
add byte ptr [esi], 7 // #07
mov al, byte ptr [esi]
mov byte ptr [edi], al
inc edi
mov al, byte ptr [esi]
mov byte ptr [edi], al
inc edi
add byte ptr [esi], 3 // #03
mov al, byte ptr [esi]
mov byte ptr [edi], al
inc edi
inc esi
add byte ptr [esi], 2 // #02
mov al, byte ptr [esi]
mov byte ptr [edi], al
inc edi
sub esi, 2
add byte ptr [esi], 15 // #0F
mov al, byte ptr [esi]
mov byte ptr [edi], al
inc edi
inc esi
mov al, byte ptr [esi]
mov byte ptr [edi], al
inc edi
add byte ptr [esi], 3 // #03
mov al, byte ptr [esi]
mov byte ptr [edi], al
inc edi
sub byte ptr [esi], 6 // #06
mov al, byte ptr [esi]
mov byte ptr [edi], al
inc edi
sub byte ptr [esi], 8 // #08
mov al, byte ptr [esi]
mov byte ptr [edi], al
inc edi
inc esi
inc byte ptr [esi]
mov al, byte ptr [esi]
mov byte ptr [edi], al
inc edi
inc esi
mov al, byte ptr [esi]
mov byte ptr [edi], al
inc edi
popa
ret
@vm_code_000B:
inc esi
add byte ptr [esi], 7 // #07
inc esi
add byte ptr [esi], 10 // #0A
inc esi
add byte ptr [esi], 3 // #03
inc esi
inc byte ptr [esi]
sub esi, 4
dec byte ptr [esi]
cmp byte ptr [esi], 0 // ]
jne @vm_code_000B
jmp @root_000C
end;
Выглядит похоже. Согласен, можно и подоптимизировать, но не та задача.
Проверяем как будет работать и пишем тест:
program hello_world_test;
{$APPTYPE CONSOLE}
{$R *.res}
{$I ..\..\data\helloworld.inc}
var
WorkBuff: array [0..300000] of Byte;
OutBuf: array [0..100] of Byte;
begin
RunBrainfuck(@WorkBuff[0], nil, @OutBuf[0]);
Writeln(PAnsiChar(@OutBuf[0]));
Readln;
end.
Смотрим результат:
Ну что ж, не плохо.
Получилось то что и задумывалось, теперь декомпилируем тело самой VM.
На выходе получилось 8153 строчек чистейшего ассемблера :)
(результат декомпиляции VM
в архиве c примерами '.\data\vm.inc')
Бегло пробежав его глазками можно сразу заметить процедуру инициализации 'хорошей' и 'плохой' строчек внутри vm_code_001B_001D:@vm_code_001B_001D:
add esi, 105
add byte ptr [esi], 67 // char "C"
add esi, 2
add byte ptr [esi], 111 // char "o"
add esi, 2
add byte ptr [esi], 110 // char "n"
add esi, 2
add byte ptr [esi], 103 // char "g"
add esi, 2
add byte ptr [esi], 114 // char "r"
add esi, 2
add byte ptr [esi], 97 // char "a"
add esi, 2
add byte ptr [esi], 116 // char "t"
add esi, 2
add byte ptr [esi], 117 // char "u"
add esi, 2
add byte ptr [esi], 108 // char "l"
add esi, 2
add byte ptr [esi], 97 // char "a"
add esi, 2
add byte ptr [esi], 116 // char "t"
add esi, 2
add byte ptr [esi], 105 // char "i"
add esi, 2
add byte ptr [esi], 111 // char "o"
add esi, 2
add byte ptr [esi], 110 // char "n"
add esi, 2
add byte ptr [esi], 115 // char "s"
add esi, 2
add byte ptr [esi], 33 // char "!"
add esi, 2
add byte ptr [esi], 33 // char "!"
add esi, 2
add byte ptr [esi], 33 // char "!"
add esi, 2
add byte ptr [esi], 32 // char " "
add esi, 2
add byte ptr [esi], 73 // char "I"
add esi, 2
add byte ptr [esi], 116 // char "t"
add esi, 2
add byte ptr [esi], 32 // char " "
add esi, 2
add byte ptr [esi], 105 // char "i"
add esi, 2
add byte ptr [esi], 115 // char "s"
add esi, 2
add byte ptr [esi], 32 // char " "
add esi, 2
add byte ptr [esi], 118 // char "v"
add esi, 2
add byte ptr [esi], 97 // char "a"
add esi, 2
add byte ptr [esi], 108 // char "l"
add esi, 2
add byte ptr [esi], 105 // char "i"
add esi, 2
add byte ptr [esi], 100 // char "d"
add esi, 2
add byte ptr [esi], 32 // char " "
add esi, 2
add byte ptr [esi], 115 // char "s"
add esi, 2
add byte ptr [esi], 101 // char "e"
add esi, 2
add byte ptr [esi], 114 // char "r"
add esi, 2
add byte ptr [esi], 105 // char "i"
add esi, 2
add byte ptr [esi], 97 // char "a"
add esi, 2
add byte ptr [esi], 108 // char "l"
add esi, 2
add byte ptr [esi], 33 // char "!"
add esi, 4
add byte ptr [esi], 83 // char "S"
add esi, 2
add byte ptr [esi], 101 // char "e"
add esi, 2
add byte ptr [esi], 114 // char "r"
add esi, 2
add byte ptr [esi], 105 // char "i"
add esi, 2
add byte ptr [esi], 97 // char "a"
add esi, 2
add byte ptr [esi], 108 // char "l"
add esi, 2
add byte ptr [esi], 32 // char " "
add esi, 2
add byte ptr [esi], 105 // char "i"
add esi, 2
add byte ptr [esi], 110 // char "n"
add esi, 2
add byte ptr [esi], 118 // char "v"
add esi, 2
add byte ptr [esi], 97 // char "a"
add esi, 2
add byte ptr [esi], 108 // char "l"
add esi, 2
add byte ptr [esi], 105 // char "i"
add esi, 2
add byte ptr [esi], 100 // char "d"
add esi, 2
add byte ptr [esi], 32 // char " "
add esi, 2
add byte ptr [esi], 58 // char ":"
add esi, 2
add byte ptr [esi], 40 // char "("
Но… все таки больше 8 тысяч строк, с наскока их проанализировать не получится.
Нужно писать дополнительный инструментарий.
Но для этого нужно написать небольшое демоприложение, выполняющее декомпилированный код VM, с которым будем работать на протяжении всей оставшейся статьи.program decompiled_vm_test;
{$APPTYPE CONSOLE}
{$R *.res}
uses
Classes,
Math;
var
// Буфер для работы VM
WorkBuff: array [0..220] of Byte;
WorkBuffIndex: Integer;
// Выходной буфер
OutputBuff: array [0..39] of AnsiChar;
OutputBuffIndex: Integer;
// Буфер с логином и серийным номером
LoginAndPwd: array [0..29] of AnsiChar;
LoginAndPwdIndex: Integer;
procedure InitLoginAndPwd(const Login, Password: AnsiString);
var
I: Integer;
A, B: Byte;
begin
// Колируем логин
Move(Login[1], LoginAndPwd[0], Length(Login));
Move(Password[1], LoginAndPwd[10], Min(Length(Password), 20));
// подготавливаем буфер с серийным номером
for I := 0 to 9 do
begin
A := Byte(LoginAndPwd[10 + I * 2]);
B := Byte(LoginAndPwd[11 + I * 2]);
if A > $39 then
Dec(A, $37)
else
Dec(A, $30);
if B > $39 then
Dec(B, $37)
else
Dec(B, $30);
A := a shl 4;
A := A or B;
LoginAndPwd[10 + I] := AnsiChar(A);
end;
end;
{$I ..\..\data\vm.inc}
begin
InitLoginAndPwd('Ms-Rem', 'C38FB7A0CF38F73B1159');
RunBrainfuck(@WorkBuff[0], @LoginAndPwd[0], @OutputBuff[0]);
Writeln(PAnsiChar(@OutputBuff[0]));
Readln;
end.
В настройках демоприложения нужно включить генерацию МАР файла (в режиме Detailed), он нам пригодится в следующей главе.
9. Пишем трейсер
Для того чтобы понять, что именно происходит в декомпилированном коде необходимо построить трассу исполнения. Причем будет достаточно информации о том, какие блоки выполняются и куда из них происходит переход.
Суть трассы заключается в построении направленного графа, анализируя который можно купировать логические ветвления в векторные блоки (грубо, в подобие блок-схемы).
Для этого потребуется отладчик:
http://habrahabr.ru/post/178159/
В процессе построения трассы отладчик будет пошагово идти по коду реципиента, прерываясь на адресах, которые мы можем привести к номеру строчки в сгенерированном нами ранее исходнике.
Для приведения адреса к номеру строчки в asm листинге потребуется небольшой модуль, который будет парсить МАР файл и возвращать эту информацию.
Также потребуется еще один модуль, который по номеру строчки в asm листинге будет возвращать имя подпроцедуры, на которой произошла остановка.
Исходный код последних двух модулей приводить не буду — они очень простые, в любом случае код можно увидеть
в архиве с примерами к статье по следующему пути: '.\tools\tracer\'.
Так же потребуется класс, который будет хранить в себе данные о снятой трассе.
Грубо вся его задача хранить массив записей вот такого вида:
type
TTraceItem = record
SubName: string;
InList, OutList: TStringList;
CustomData: Pointer;
end;
и предоставлять методы работы с ним.
Также очень простой, посмотреть код можно
в архиве по пути: '.\tools\common\trace_data.pas'
Трасса выполнения будет сниматься в 4 прохода в 4 различных режимах.
1. Полная трасса исполнения программы.
2. Частичная трасса, из одной итерации чтения буфера с логином и серийным номером.
3. Частичная трасса из одной итерации вывода результата.
4. Детектирование процедур, в которых происходит запись ячеек с логином и паролем.
Чуть попозже придется дописать трейсер, добавив в него пятый режим для полного снятия трассы, но снимаемой с демопримера, в котором серийный номер скинут в последовательность нулей (в исходном коде этот режим будет зваться ttWrongSN).
Но об этом попозже, а сейчас…
Реализация трейсера достаточно банальна:
1. перекрываем OnCreateProcess отладчика и инициализируем его установкой соответствующих ВР:procedure TTracer.OnCreateProcess(Sender: TObject; ThreadIndex: Integer;
Data: TCreateProcessDebugInfo);
begin
Writeln('process start');
case FTraceType of
// трассируем от начала до конца
ttFull:
begin
FDebuger.SetHardwareBreakpoint(ThreadIndex,
Pointer(FMap.AddrAtLine(FSrc.StartLine)), hsByte, hmExecute, 0, 'vm_start');
FDebuger.SetHardwareBreakpoint(ThreadIndex,
Pointer(FMap.AddrAtLine(FSrc.EndLine)), hsByte, hmExecute, 1, 'vm_end');
end;
ttIn:
// включаем трассу от чтения логина
FDebuger.SetHardwareBreakpoint(ThreadIndex,
Pointer(FMap.AddrAtLine(FSrc.ReadPwdLine)), hsByte, hmExecute, 0, 'read_pwd_start');
ttOut:
// включаем трассу от вывода
FDebuger.SetHardwareBreakpoint(ThreadIndex,
Pointer(FMap.AddrAtLine(FSrc.OutputBufLine)), hsByte, hmExecute, 0, 'out_data_start');
ttCheckLoginBuff:
begin
// включаем трассу по первому обращению к буферу с логином и паролем
FDebuger.SetHardwareBreakpoint(ThreadIndex,
Pointer(FMap.AddrAtLine(FSrc.StartLine)), hsByte, hmExecute, 0, 'LoginAndSN_MBP_Present');
FDebuger.SetHardwareBreakpoint(ThreadIndex,
Pointer(FMap.AddrAtLine(FSrc.EndLine)), hsByte, hmExecute, 1, 'vm_end');
end;
end;
end;
2. После этого в обработчике хардварного бряка выставляем режимы работы:procedure TTracer.OnHardwareBreakpoint(Sender: TObject; ThreadIndex: Integer;
ExceptionRecord: Windows.TExceptionRecord; BreakPointIndex: THWBPIndex;
var ReleaseBreakpoint: Boolean);
var
CurrentName: string;
ThreadData: TThreadData;
I: Integer;
begin
Inc(FTotalStepCount);
ThreadData := FDebuger.GetThreadData(ThreadIndex);
Writeln(ThreadData.Breakpoint.Description[BreakPointIndex]);
case FTraceType of
ttFull:
begin
if BreakPointIndex = 0 then
begin
FDebuger.ResumeAction := raTraceInto;
ReleaseBreakpoint := True;
end
else
begin
ReleaseBreakpoint := True;
CurrentName :=
FSrc.GetProcedureNameAtLine(FMap.LineAtAddr(DWORD(ExceptionRecord.ExceptionAddress)));
FTrace.AddTace(FPreviousName, CurrentName);
FTrace.SaveToFile('..\..\data\full.trace');
Writeln('Trace done.');
Writeln('Total instructions traced: ', FTotalStepCount);
Writeln('Traced subroutine added: ', FTrace.Count);
Writeln('Time elapsed: ', GetTickCount - FStart, 'ms');
end;
end;
ttIn, ttOut:
begin
if FProcList.Count > 0 then
begin
ReleaseBreakpoint := True;
CurrentName :=
FSrc.GetProcedureNameAtLine(FMap.LineAtAddr(DWORD(ExceptionRecord.ExceptionAddress)));
FTrace.AddTace(FPreviousName, CurrentName);
if FTraceType = ttIn then
FProcList.SaveToFile('..\..\data\in.proclist')
else
FProcList.SaveToFile('..\..\data\out.proclist');
Writeln('Trace done.');
Writeln('Total instructions traced: ', FTotalStepCount);
Writeln('Traced subroutine added: ', FProcList.Count);
Writeln('Time elapsed: ', GetTickCount - FStart, 'ms');
FDebuger.ResumeAction := raRun;
end
else
FDebuger.ResumeAction := raTraceInto;
end;
ttCheckLoginBuff:
begin
ReleaseBreakpoint := True;
if BreakPointIndex = 0 then
begin
FWorkBuffAddr := PByte(FDebuger.GetContext(0).Eax);
for I := 0 to 9 do
FDebuger.SetMemoryBreakpoint(FWorkBuffAddr + 28 + (I * 2), 1, True, 'Login' + IntToStr(I));
for I := 0 to 9 do
FDebuger.SetMemoryBreakpoint(FWorkBuffAddr + 48 + (I * 2), 1, True, 'SN' + IntToStr(I));
end
else
begin
FProcList.SaveToFile('..\..\data\change_buff.proclist');
Writeln('Trace done.');
Writeln('Total instructions traced: ', FTotalStepCount);
Writeln('Traced subroutine added: ', FProcList.Count);
Writeln('Time elapsed: ', GetTickCount - FStart, 'ms');
end;
end;
end;
end;
Если вкратце, то в режиме полного дампа (ttFull) второй HBP будет означать завершение процесса трассировки, режимы «ttIn, ttOut» будут останавливаться при втором срабатывании HBP (один проход ввода/вывода), ну а ttCheckLoginBuff будет выполнять трассировку с использованием MBP пока не будет выполнен весь цикл VM.
3. Результаты трассировки будут собираться в этих двух обработчиках:procedure TTracer.OnSingleStep(Sender: TObject; ThreadIndex: Integer;
ExceptionRecord: Windows.TExceptionRecord);
var
CurrentName: string;
begin
Inc(FTotalStepCount);
CurrentName :=
FSrc.GetProcedureNameAtLine(FMap.LineAtAddr(DWORD(ExceptionRecord.ExceptionAddress)));
if FTraceType = ttFull then
begin
if FPreviousName = '' then FPreviousName := CurrentName;
if FPreviousName <> CurrentName then
begin
FTrace.AddTace(FPreviousName, CurrentName);
FPreviousName := CurrentName;
end;
end
else
FProcList.Add(CurrentName);
FDebuger.ResumeAction := raTraceInto;
end;
procedure TTracer.OnMemoryBreakpoint(Sender: TObject; ThreadIndex: Integer;
ExceptionRecord: Windows.TExceptionRecord; BreakPointIndex: Integer;
var ReleaseBreakpoint: Boolean);
begin
Inc(FTotalStepCount);
FProcList.Add(
FSrc.GetProcedureNameAtLine(FMap.LineAtAddr(DWORD(ExceptionRecord.ExceptionAddress))));
end;
Первый следит за ветвлением переходов, а второй просто собирает имена процедур, из которых происходило обращение к буферу, в которым расположен логин и серийный номер.
В результате работы трейсера на руках у нас будет 4 файла, на основе которых мы сможем достаточно легко проанализировать всю работу VM, но…
Но для этого необходимо каким либо образом отобразить полученные данные в том виде, в котором с ними можно работать…
10. Отображаем трассу исполнения в виде графа
IDA Pro отличный инструмент, графы, выдаваемые им, очень сильно помогают в процессе анализа исходного кода, но… но он не универсален.
В частности с графом декомпилированного кода VM, построенного IDA, работать в данном случае не совсем удобно.
Именно поэтому я и пошел на собственноручное снятие трассы (описанное в прошлой главе) и написание инструмента, позволяющего её визуализировать
Суть инструмента в следующем:
1. свернуть трассу исполнения ПО в визуализируемый граф
2. отобразить в графе логические блоки исполнения
3. как результат, показать адреса блоков, интересные для анализа кода.
Самый первый этап, это преобразование данных от трейсера в направленный граф.
Он строится достаточно просто — берем текущий блок и от него рекурсивно строим исходящие переходы. Главное на забывать про while циклы, где переход в конце процедуры на её начало, будет направлен на уже добавленный элемент.
Поэтому при построении графа необходимо каждому элементу добавить кастомное свойство, в котором будет хранится узел графа, на который должен быть выставлен линк при первом-же обращении.
Анализируя код BF можно сделать следующие выводы:
1. В каждый из while циклов может быть только 2 входа (из внешнего блока кода и переход из конца цикла).
2. Конец каждого while цикла имеет только 2 выхода (если цикл завершен переходим на уровень выше по коду, в обратном случае возвращаемся в начало цикла).
3. Из тела while блока может быть множественное кол-во выходов, при условии наличия ifthen блоков в его теле (но это не наш случай).
Под сверткой кода подразумевается следующее:
1. Если процедура имеет один вход и один выход (по результатам трассы), то она добавляется к текущему блоку свертки.
2. Началом каждого блока свертки будет являться любая процедура, имеющая два входа (цикл while).
3. Концом блока свертки будет являться переход на уже добавленный код (конец while) либо любой другой блок кода, который по результатам трассы имеет два выхода (что подразумевает под собой тот же конец цикла, исходя из предыдущего пункта №3).
За все эти этапы отвечает достаточно простая рекурсивная процедура ('.\tools\trace_viewer\trace_graph.pas'):procedure TTraceGraph.LoadItem(Index: Integer; AParent: TExecutionBlock);
var
Block: TExecutionBlock;
Item: TTraceItem;
begin
// начало блока исполнения - любая подпроцедура
// тело блока исполнения - подпроцедуры из одного входящего и одного исходящего вектора
// конец блока - ссылка на уже добавленную подпроцедуру или если два выходных вектора
// Если элемент был добавлен, делаем ссылку на него и на выход
Item := FTrace[Index];
if Item.CustomData <> nil then
begin
AddVector(AParent, Item.CustomData);
Exit;
end;
Block := TExecutionBlock(AddNode(NodesCount));
if AParent = nil then
Block.Level := 0
else
begin
AddVector(AParent, Block);
Block.Level := AParent.Level + 1;
FMaxLevel := Max(FMaxLevel, Block.Level);
end;
Block.ProcList.Add(Item.SubName);
FTrace.SetCustomData(Index, Block);
// если исходящих ссылок нет - дошли до конца трассы
if Item.OutList.Count = 0 then Exit;
// если у итема две исходящих ссылки - добавляем их через рекурсию
if (Item.OutList.Count = 2) then
begin
LoadItem(FTrace.GetItemIndexByName(Item.OutList[0]), Block);
LoadItem(FTrace.GetItemIndexByName(Item.OutList[1]), Block);
Exit;
end;
// в противном случае крутим цикл
Item := FTrace.ItemByName(Item.OutList[0]);
while Item.InList.Count = 1 do
begin
Block.ProcList.Add(Item.SubName);
FTrace.SetCustomData(FTrace.GetItemIndexByName(Item.SubName), Block);
case Item.OutList.Count of
0: Exit;
1: Item := FTrace.ItemByName(Item.OutList[0]);
2:
begin
LoadItem(FTrace.GetItemIndexByName(Item.OutList[0]), Block);
LoadItem(FTrace.GetItemIndexByName(Item.OutList[1]), Block);
Exit;
end;
end;
end;
if Item.InList.Count = 2 then
LoadItem(FTrace.GetItemIndexByName(Item.SubName), Block);
end;
Результатом обработки трассы декомпилированного кода (в котором нет сложных случаев в виде множественных выходов из while), будет вот такая картинка:
На ней отображена трасса исполнения программы, со свернутыми блоками исполнения.
Не обращайте внимания на то, что все так красиво расставлено вертикальными столбцами — я не писал алгоритм такой расстановки и все банально раскидал ручками (ибо это гораздо быстрее, чем писать такой же движок визуализации, как у IDA.
Исходный код данной утилиты я приводить не буду, его вы сможете посмотреть
в архиве ".\tools\trace_viewer\".
Основная ее задача, дать точку старта, от которой можно оттолкнуться при анализе кода VM.
И вот две картинки, которые покажут часть логики работы.
Вот это происходит при чтении логина и серийного номера:
А вот эти процедуры выполняются при выводе результата:
Обратите внимание на исполнение процедур по центру схемы, они являются матаппаратом и не участвуют в работе логики алгоритма, спрятанного в VM.
Сразу оговорюсь — данный вывод был сделан уже в процессе исследования кода.
Изначально, получив на руки такие две картинки я был немного озадачен и предположил что внутри может скрываться еще одна мини-VM (зеленый вертикальный блок снизу слева), которая раскидывает логику, опираясь на собственные инструкции, но… предположение оказалось неверным.
А так, судя по картинкам мы имеем на руках:
1. Верхний левый блок схемы — чтение данных.
2. Нижний правый — вывод результата.
3. Центральная ветка — какой-то матаппарат (его в итоге анализировать даже не придется).
Все что не выделено зеленым и есть третий конверт (скрытая под VM логика).
Те, кто будет изучать исходники данного вьювера, заранее приношу извинения — код инструмента очень сырой и писался буквально на коленке за два вечера, поэтому большим функционалом утилита не располагает. Умеет только отображать сам граф, предоставляет механизм его модификации (читай — можно передвигать блоки так как будет более удобно).
Режим ZOOM-а не добавлен, для этого есть отдельная кнопка, генерирующая общее превью (с которого и снимались данные скриншоты).
Но с ролью инструмента анализа графа справляется не плохо.
В архиве со статьей есть уже расставленный граф ('.\data\current.graph') который был получен из трассы, снятой в предыдущей главе ('.\data\full.trace').
Впрочем… к нашим баранам.
Инструмент для анализа декомпилированного кода VM готов, приступим непосредственно к его анализу…
11. Анализ и детектирование алгоритма чтения переменных.
Приступив к анализу VM я уже примерно представлял с чем мне придется работать.
Опираясь на карту памяти с которой работает VM (показанную в 7 главе), я знал оффсеты, по которым расположены «правильная» и «не правильная» строки с результатами, а так-же оффсет, по которому располагается буфер с логином и серийным номером.
Зная как работает интерпретатор BF я даже прикинул примерный алгоритм работы с данными, с учетом того, что должны проводится некие матоперации над логином и SN.
Например если требуется сложить два поля Z и X, то в Brainfuck нет операции сложения, для этого будет необходимо написать while цикл, в котором будет итерационно декрементироваться значение ячейки X и инкрементироваться значение ячейки Y.
Таким образом ячейка Y будет содержать сумму обоих ячеек, а ячейка X будет обнулена.
Но при выводе данных, как было показано выше, можно наблюдать что буфер с логином и серийным номером находится там, где он и должен быть и ни одно из его полей не изменено. Значит в VM применяется какой-то другой подход для чтения данных.
Странный нюанс, на который я сразу обратил внимание — что логин, что серийный номер, что «правильная» и «не правильная» строки в карте памяти идут не в том виде, как есть, а каждый байт отделен от следующего нулем. Такое ощущение что мы работаем с юникодом, хотя в действительности работа идет с ANSI строками.
Эти два момента мне были не понятны.
Впрочем, начинать с чего-то все равно нужно, и я решил приступить к анализу алгоритма с его конца, предположив, что решение о выводе результата принимается вот с таком блоке процедур (там где выводится результат):
Тем более что граф показывает данный блок в виде одной функции с одной точкой входа и одним выходом.
(Кстати предположение о том, что в этом блоке принимается решение, в итоге оказалось не верным).
Для отладки я использовал режим CPU-View непосредственно самой Delphi (этого оказалось достаточным за глаза).
Отлаживаемым приложением было «decompiled_vm_text.exe» с которого и снималась трасса исполнения.
В качестве вспомогательных подсказок в «Watch List» были добавлены три переменных:
1. Текущее значение курсора рабочего буфера (регистра ESI), которое вычислялось разницей от адреса начала рабочего буфера (pWorkBuff) и текущим значением регистра. (esi-$4E5008)
2. Значение текущей ячейки pWorkBuff (pbyte(esi)^)
3. Оно-же только в HEX режиме.
4. Окно дампа было настроено на начало рабочего буфера VM ($4E5008).
ЗЫ: у вас адрес рабочего буфера может быть другой, поэтому число 4E5008 вы должны вычислить заранее при начале отладки, подсмотрев это значение в переменной pWorkBuff.
Таким образом, настроенный отладчик, остановленный на начале процедуры "@vm_code_39D7", выглядел так:
Собственно с этой процедуры и приступим.
Если вы обратите внимание на картинку графа, это самая первая процедура в свернутом блоке выполнения, который вызывает сам себя (while цикл).
На момент вызова данной процедуры, курсор рабочего буфера установлен на ячейку №27 (на картинке с картой памяти выделена красным), в которой содержится некое число (40 или $28). Эта ячейка находится как раз перед буфером с логином и серийным номером (расположенным по офсету 28, в котором хранится первый символ логина — «M»).
Запомните номер этой ячейки — она является одним из центральных элементов логики VM.
Давайте посмотрим исходный код свернутого блока:
@vm_code_39D7:
cmp byte ptr [esi], 0 // равно ли значение ячейки №27 нулю?
jne @vm_code_39D8 // если нет, ищем правый ноль
@vm_code_39D8:
add esi, 2 // от текущего номера ячейки прыгаем на 2 ячейки вправо
cmp byte ptr [esi], 0 // ячейка равна нулю?
jne @vm_code_39D8 // если нет, переходим к следующей
@vm_code_39D7_39D9: // нашлась ячейка равная нулю?
inc byte ptr [esi] // увеличиваем ее значение на 1
cmp byte ptr [esi], 0
jne @vm_code_39DD // и переходим на поиск ячейки #27
@vm_code_39DD:
sub esi, 2 // ищем первый ноль слева (через 2 ячейки),
// т.к. справа все уже заполнено единицами, то первый ноль будет перед ячейкой #27
cmp byte ptr [esi], 0
jne @vm_code_39DD
@vm_code_39D7_39DE:
add esi, 2 // нашли ячейку #27
dec byte ptr [esi] // декрементируем ее значение
cmp byte ptr [esi], 0 // и если оно не равно нулю, пеереходим к началу цикла
jne @vm_code_39D7
jmp @vm_code_397A_39D8 // цикл завершен
Здесь я выстроил блоки исполнения в порядке их исполнения (не в том виде, как они идут в исходном коде), чтобы было проще проанализировать логику из работы.
Итак, что здесь происходит?
Данный алгоритм инициализирует нули (которые разделяют каждый элемент логина/серийного номера, а так-же «плохую» и «хорошую» строки) единицами.
Если прерваться на финализации цикла и посмотреть на результат, то можно увидеть вот такую картинку:
Ячейка №27 будет обнулена, но как результат можно увидеть что буфер будет проинициализирован единицами, заканчивающимися как раз перед первым выводимым VM символом «хорошей строки», а именно символом «С».
Обратите внимание как интересно выполнены переходы в начало и конец изменяемых данных (процедуры @vm_code_39D8 и @vm_code_39DD). В качестве детектирования концевых блоков используется сверка значения текущей ячейки с нулем, самый левый ноль будет означать позицию ячейки №27 (со сдвигом), а самый правый ноль будет означать еще не инициализированную единицей ячейку.
Таким образом суть данного блока сводится к постройке индекса (в виде единиц) к ячейке, с которой будет работать следующий while цикл, начинающийся с процедуры @vm_code_39EB.
Он начнет свою работу с ячейки, на которую указывает последняя единица выстроенного ранее индекса, а именно с ячейки №108, где как раз и расположен символ «С» (выделен синим), который VM сейчас должна вывести во внешний буфер.
Перед вызовом данной процедуры VM успела произвести некоторые подготовительные действия, одним из которых было инициализация ячейки №27 единицей, т.о. самая левая ячейка, на которую выйдет алгоритм поиска левого конца индекса с этого момента, будет ячейка №26.
Итак:
@vm_code_39EB:
dec esi // сейчас находимся на ячейке №108, сдвигаемся и
cmp byte ptr [esi], 0 // проверяем, выставлен ли на нее индекс
jne @vm_code_39ED
@vm_code_39ED:
sub esi, 2 // если да, то
cmp byte ptr [esi], 0 // ищем левый ноль (перед ячейкой №26)
jne @vm_code_39ED
jmp @vm_code_39EB_39EE
@vm_code_39EB_39EE:
inc esi // сдвигаемся с индекса на ячейку №26
inc byte ptr [esi] // инкрементируем значение ячейки №26
sub esi, 20 // сдвигаемся на ячейку №6
inc byte ptr [esi] // инкрементируем и ее
add esi, 21 // прыгаем на начало индексного массива единиц
cmp byte ptr [esi], 0
jne @vm_code_3A1D
@vm_code_3A1D:
add esi, 2 // и ищем правый конец индекса (ячейку указывающую на 108)
cmp byte ptr [esi], 0
jne @vm_code_3A1D
jmp @vm_code_39EB_3A1E // сюда приходим тогда, когда закончился индекс
@vm_code_39EB_3A1E:
dec esi // сдвигаемся на ячейку №108
dec byte ptr [esi] // декремнтируем ее и
cmp byte ptr [esi], 0 // пока она не равна нулю, крутим цикл с самого начала...
jne @vm_code_39EB
jmp @vm_code_397A_39EC // выход
Логика второго цикла следующая: он переносит значение ячейки №108 в ячейки за номером №26 и №6 (обратите внимание — вот оно, шестая ячейка из которой и забирается символ, на которую я указал еще в седьмой главе).
И собственно уже начинается вырисовываться сама логика работы с данными (при чтении значения происходит дубляж значения по двум адресам).
Карта памяти начинает выглядеть следующим образом:
Зелеными прямоугольниками выделены места, с которыми произошли изменения, красным выделена ячейка №108 из которой забиралось значение.
Следующий while цикл в графе начинается с процедуры "@vm_code_3A2A".
Он начнет сою работу с ячейки №26, в которой хранится копия числа, ранее размещенного в ячейке №108.
Код выглядит следующим образом:
@vm_code_3A2A:
inc esi // прыгаем на начало индексного массива единиц
cmp byte ptr [esi], 0
jne @vm_code_3A2C
@vm_code_3A2C:
add esi, 2
cmp byte ptr [esi], 0 // ищем конец индекса, указывающий на ячейку №108
jne @vm_code_3A2C
jmp @vm_code_3A2A_3A2D
@vm_code_3A2A_3A2D:
dec esi // переходим с индекса на ячейку №108
inc byte ptr [esi] // и инкрементируем ее значние
dec esi // сдвинаемся обратно на индекс
cmp byte ptr [esi], 0
jne @vm_code_3A33
@vm_code_3A33:
sub esi, 2 // ищем начало индекса
cmp byte ptr [esi], 0
jne @vm_code_3A33
jmp @vm_code_3A2A_3A34 // сюда приходим тогда, когда закончился индекс
@vm_code_3A2A_3A34:
inc esi // сдвигаемся на ячейку №26
dec byte ptr [esi] // декрементируем ее
cmp byte ptr [esi], 0 // если она не равна нулю
jne @vm_code_3A2A // крутим цикл
jmp @vm_code_397A_3A2B // выход
Задача данного кода переместить значение яз ячейки №26 обратно в ячейку №108, восстановив таким образом исходное значение ячейки, с которой алгоритм начал свою работу.
Посмотрим на карту памяти после работы алгоритма:
И самым последним шагом в этой немного запутанной логике работы с ячейками будет финал, расположенный в процедуре "@vm_code_3A41"
Она достаточно простая:
@vm_code_3A41:
dec byte ptr [esi]
sub esi, 2
cmp byte ptr [esi], 0
jne @vm_code_3A41
Вся ее задача, начать работу с самой последней ячейки равной единице (посредством которой и выстроен индекс) и убрать все единицы индекса.
Результатом ее работы будет вот такая карта:
Зеленым отмечены поля индекса, который убрала последняя процедура, а красным отмечен результат работы всех четырех свернутых блоков.
Запутались?
Ничего странного, но если внимательно взглянуть на самую последнюю картинку, то можно понять, что вся эта навороченная логика из четырех этапов по сути выполняет одну простую операцию.
И операция эта — присвоение значения ячейки «А» ячейке «B».
Причем алгоритм достаточно гибок и позволяет таким образом прочитать значение любого символа логина/серийного номера или «хорошей/плохой» строк, для этого достаточно проинициализировать ячейку №27 номером символа и выполнить все четыре вышеописанных этапа.
Красивый подход — ничего не скажешь, достаточно солидно размазанная логика работы с ячейками, правда есть небольшой нюанс.
Поняв как происходит получение значения ячейки и имея на руках граф исполнения, проанализовать всю логику работу с этого момента займет от силы полтора часа.
Остальные процедуры с верхней картинки с графом рассматривать смысла не имеет, там сокрыт какой-то внутренний матаппарат, необходимый для работы VM, есть откровенно мусорные куски кода (например в цикле меняющие значение двух/трех ячеек местами и возвращающими в итоге все в исходное состояние).
12. Разбор элементов логики на составляющие.
Таким образом выяснилось что получение значения ячейки происходит посредством выполнения трех циклов, которые можно наглядно увидеть на графе и заключительного блока финализации, убирающего массив индексов сразу после окончания работы третьего цикла.
Вот на этой картинке я их сразу выделил красными прямоугольниками и отталкивался от данного изображения на протяжении всего разбора логики VM:
Двумя синими прямоугольниками выделены так-же циклы чтения значения ячеек, но т.к. в них зачитывается значения символов Login[0] и Login[1] (это я узнал проанализировав все циклы алгоритма), то индексный массив из единиц в этих двух случаях не строится, в первом цикле зачитывается значение в ячейки №26 и №6, а во втором значение из ячейки №26 возвращается обратно.
На картинке не совсем хорошо видно (сказывается zoom), чтобы было более понятно, вот второй вариант, который показывает принцип, по которому я обводил блоки прямоугольниками:
Чтобы проверить мое предположение я проконтролировал самого себя и отобразил на графе блоки, в которых происходит изменение полей логина и серийного номера (кнопка «Показать доступ к буферу с логином и SN»). По данной кнопке вьювер подгрузит список таких процедур, созданный ранее трассировщиком в режиме ttCheckLoginBuff и покажет вот такую картинку:
Все как и предполагалось на предыдущем изображении, единственно из логики выбивается блок слева сверху (обведенный синим прямоугольником), это участок кода, который зачитывает значения логина и серийного номера из внешнего буфера, поэтому нет ничего удивительного, что в нем происходит изменения данных полей.
Здесь я сделал вывод о том, что по всей видимости каждый из вертикальных блоков — это один из этапов проверки серийного номера (предположение так же оказалось верным).
Следующим шагом мне стало интересно, а где вообще принимается решение о правильности серийного номера, для этого я пересобрал пример «decompiled_vm_text.exe» в котором изменил значение серийного номера на нули, и снова снял трассу в режиме ttWrongSN.
После всех этих шагов я посмотрел различия трассы (кнопка «Показать различия трассы с неверным SN») в результате увидел следующее:
Можно сказать — бинго.
На первой же операции (правый вертикальный блок) произошел выход, причем выполнились не все процедуры (блок отмеченный красным). Значит именно в нем и происходит принятие решение по результатам первой же операции над буфером с логином и серийным номером.
Точнее таких блоков в итоге будет несколько, для каждой операции свой, впрочем разбирать их логику работы не придется, т.к. смысл всех операций будет достаточно прозрачен.
Следующим этапом я поставил бряки в отладчике в начале каждого вертикального блока (которые раньше разметил прямоугольниками), для того чтобы понять в каком порядке выполняются операции.
Получился такой список:
- vm_code_17AB
- vm_code_1A63
- vm_code_1E74
- vm_code_2333
- vm_code_28DA — выполняется много раз в цикле
- vm_code_2AF3
- vm_code_2D27
- vm_code_2F41
Осталось, ориентируясь на граф, просто пройтись по всем выделенным местам (пропуская уже известные элементы логики в которых забирается символ логина/SN) и проанализировать какие операции проводятся над этими символами.
Я не буду давать диапазоны процедур, в которых происходит создание индекса, чтение значения, происходит возврат значения и убирание индекса. Для простоты я буду показывать только наименование процедуры первого цикла (в которой происходит построение индексного массива из единиц).
Приступим к разбору логики:
1. vm_code_17AB
1.1 vm_code_1815 — читаем значение SN[0] в ячейку №6
1.2 vm_code_17AB_1880 прибавляем к ячейке №6 число 12
1.3 vm_code_1903 — читаем значение SN[4] в ячейку №7
В результате в обеих ячейках (6, 7) получится одно и то-же число, таким образом делаем вывод, что первая математическая операция производит следующую проверку: SN[4] = SN[0] + 12
2. vm_code_1A63
2.1 vm_code_1AD4 — читаем значение SN[0] в ячейку №6
2.2 vm_code_1B58 это значение переносится в ячейку №7
2.3 vm_code_1BC8 — читаем значение SN[3] в ячейку №6
2.4 vm_code_1C4C значение ячейки №6 суммируется с ячейкой №7 (результат в 7)
2.5 vm_code_1A63_1C5A — ячейка №7 увеличивается на число 84
2.6 vm_code_1D12 — читаем значение SN[2] в ячейку №6
В результате в обеих ячейках (6, 7) получится одно и то-же число, таким образом делаем вывод, что вторая математическая операция производит следующую проверку: SN[2] = SN[0] + SN[3] + 84
3. vm_code_1E74
3.1 vm_code_1EE8 — читаем значение Login[0] в ячейку №6
3.2 vm_code_1F5B — переносим значение из 6 в 7 ячейку
3.3 vm_code_1FDD — читаем значение Login[1] в ячейку №6
3.4 vm_code_204D — значение ячейки №6 суммируется с ячейкой №7 (результат в 7)
3.5 vm_code_20CB — читаем значение SN[4] в ячейку №6
3.6 vm_code_214F — значение ячейки №6 суммируется с ячейкой №7 (результат в 7)
3.7 vm_code_21C3 — читаем значение SN[1] в ячейку №8
В результате в обеих ячейках (7, 8) получится одно и то-же число, таким образом делаем вывод, что третья математическая операция производит следующую проверку: SN[1] = Login[0] + Login[1] + SN[4]
4. vm_code_2333
4.1 vm_code_239B — читаем значение Login[8] в ячейку №7
4.2 vm_code_2493 — читаем значение Login[4] в ячейку №6
4.3 vm_code_2517 — значение ячейки №6 суммируется с ячейкой №7 (результат в 7)
4.4 vm_code_2586 — читаем значение Login[2] в ячейку №6
4.5 vm_code_260A — значение ячейки №6 отнимается от ячейки №7 (результат в 7)
4.6 vm_code_2689 — читаем значение SN[5] в ячейку №6
В результате в обеих ячейках (6, 7) получится одно и то-же число, таким образом делаем вывод, что четвертая математическая операция производит следующую проверку: SN[5] = Login[8] + Login[4] — Login[2]
5. vm_code_28DA — в цикле проходим по всем 10 символам логина и суммируем их с ячейкой №7
Грубо в результате пятой математической операции выполняется вот такой код:
Tmp := 0;
for I := 0 to 9 do
Inc(Tmp, Login[I]); // значение логина "Ms-Rem" в результате будет равно $11
Сумма всех символов логина останется в ячейке №7
6. vm_code_2AF3
6.1 vm_code_2bc5 — читаем значение SN[8] в ячейку №6
В результате в обеих ячейках (6, 7) получится одно и то-же число, таким образом делаем вывод, что шестая математическая операция производит следующую проверку: SN[8] = Tmp (сумма всех чисел логина)
7. vm_code_2D27
7.1 vm_code_2D27_2D29 — к ячейке №7 прибавляется число 72
7.2 vm_code_2DD5 — читаем значение SN[9] в ячейку №8
В результате в обеих ячейках (7, 8) получится одно и то-же число, таким образом делаем вывод, что седьмая математическая операция производит следующую проверку: SN[9] = Tmp (сумма всех чисел логина) + 72
8. vm_code_2F41 (на момент вызова этой процедуры сумма чисел логина будет лежать в ячейке №18)
8.1 vm_code_2FA1 — читаем значение SN[6] в ячейку №6
8.2 vm_code_2F41_300C — ячейка №6 увеличивается на число 51
8.3 vm_code_3071_307D + vm_code_308B перекидываем Tmp в ячейку №7
8.4 vm_code_30AA — значение ячейки №7 суммируется с ячейкой №6 (результат в 6)
8.5 vm_code_311D — читаем значение SN[7] в ячейку №7
В результате в обеих ячейках (6, 7) получится одно и то-же число, таким образом делаем вывод, что восьмая математическая операция производит следующую проверку: SN[7] = SN[6] + 51 + Tmp
Вот собственно и весь алгоритм, сокрытый в виртуальной машине, как на ладони.
Вот так будет выглядеть его исходный код:program keygenme_source;
{$APPTYPE CONSOLE}
{$R *.res}
uses
Windows,
Math;
function CheckSerial(const ALogin, ASerial: AnsiString): string;
const
ValidSN = 'Congratulations!!! It is valid serial!';
InvalidSN = 'Serial invalid :(';
var
Login: array [0..9] of Byte;
Serial: array [0..9] of Byte;
I, A, B, Tmp: Byte;
Checked: Boolean;
begin
ZeroMemory(@Login[0], 10);
Move(ALogin[1], Login[0], Min(10, Length(ALogin)));
// инициализируем серийник
for I := 0 to 9 do
begin
A := Byte(ASerial[1 + I * 2]);
B := Byte(ASerial[2 + I * 2]);
if A > $39 then
Dec(A, $37)
else
Dec(A, $30);
if B > $39 then
Dec(B, $37)
else
Dec(B, $30);
A := A shl 4;
Serial[I] := A or B;
end;
// проверка серийника
Checked := True;
// первый этап
if Serial[4] <> Byte(Serial[0] + 12) then
Checked := False;
// второй этап
if Serial[2] <> Byte(Serial[0] + Serial[3] + 84) then
Checked := False;
// третий этап
if Serial[1] <> Byte(Login[0] + Login[1] + Serial[4]) then
Checked := False;
// четвертый этап
if Serial[5] <> Byte(Login[8] + Login[4] - Login[2]) then
Checked := False;
// пятый этап
Tmp := 0;
for I := 0 to 9 do
Inc(Tmp, Login[I]);
// шестой этап
if Serial[8] <> Tmp then
Checked := False;
// седьмой этап
if Serial[9] <> Byte(Tmp + 72) then
Checked := False;
// восьмой этап
if Serial[7] <> Byte(Serial[6] + 51 + Tmp) then
Checked := False;
// вывод результата
if Checked then
Result := ValidSN
else
Result := InvalidSN;
end;
begin
Writeln(CheckSerial('Ms-Rem', 'C38FB7A0CF38F73B1159'));
Readln;
end.
Ну что… вот практически и все, последний третий конверт снят.
Осталось совсем чуть-чуть.
13. Пишем генератор серийных номеров.
В задаче keygenme шло условие — необходимо его закейгенить, т.е. написать алгоритм, который будет генерировать серийный номер на основе введенного логина.
Имея на руках алгоритм проверки серийного номера сделать это достаточно тривиально.
Если посмотреть на поля серийного номера, то можно увидеть, что SN[0], SN[3] и SN[6] не проверяются, они только участвуют при проверке значений других полей. Стало быть эти три поля могут содержать абсолютно любые значения, а остальные поля будут рассчитываться уже на их основе.
Таким образом код генератора будет выглядеть следующим образом:program serial_generator;
{$APPTYPE CONSOLE}
{$R *.res}
uses
Windows,
Math,
SysUtils;
function GetSN(const ALogin: AnsiString): string;
var
Login: array [0..9] of Byte;
Serial: array [0..9] of Byte;
I, Tmp: Byte;
begin
ZeroMemory(@Login[0], 10);
Move(ALogin[1], Login[0], Min(10, Length(ALogin)));
Randomize;
// эти три поля не проверяются и могут содержать любые значения
Serial[0] := Random(255);
Serial[3] := Random(255);
Serial[6] := Random(255);
// генерируем число для проверки первого этапа
Serial[4] := Serial[0] + 12;
// генерируем число для проверки второго этапа
Serial[2] := Serial[0] + Serial[3] + 84;
// генерируем число для проверки третьего этапа
Serial[1] := Login[0] + Login[1] + Serial[4];
// генерируем число для проверки четвертого этапа
Serial[5] := Login[8] + Login[4] - Login[2];
// запоминаем сумму символов логина получаемом на пятом этапе
Tmp := 0;
for I := 0 to 9 do
Inc(Tmp, Login[I]);
// генерируем число для проверки шестого этапа
Serial[8] := Tmp;
// генерируем число для проверки седьмого этапа
Serial[9] := Tmp + 72;
// генерируем число для проверки восьмого этапа
Serial[7] := Serial[6] + 51 + Tmp;
// выводим результат в виде набора символов в HEX представлении
Result := '';
for I := 0 to 9 do
Result := Result + IntToHex(Serial[I], 2);
end;
begin
Writeln(GetSN('Rouse_'));
Readln;
end.
В итоге вот небольшой список серийных номеров для логина «Rouse_»:
- 5E2BB2006AF04EEE6DB5
- C5929D84D1F0F9996DB5
- BC894434C8F0BA5A6DB5
- 14E19B3320F0B2526DB5
Keygenme решен.
14. Выводы
Давайте заново пройдемся по этапам и вспомним, какие методы применялись для сокрытия алгоритма проверки серийного номера:
1. Сброс точки входа в ноль — метод спорный, более того на исполняемые файлы, в которых применяется такой трюк, антивирусы будут смотреть с большим подозрением, ибо обычный компилятор никогда не сгенерирует такой исполняемый файл, стало быть кто-то его модифицировал что является сигналом для антивируса.
2. Шифрование тела исполняемого файла — в принципе не наказуемо, но как было показано выше, снимается такое шифрование достаточно просто и не представляет из себя серьезного препятствия.
3. Код декриптора обильно разбавленный мусором — спорное решение, достаточно просто снимается из-за того что в качестве мусора не использовались мусорные блоки. Ну например вместо инструкции ADD EAX, 2 можно написать вот такой мусорный блок (первое, что пришло в голову):
asm
inc eax // первая реальная инструкция
// начало мусорного блока
push eax
lea eax, @label
inc eax
xchg eax, [esp]
call @label
@label:
ret
// конец мусорного блока
inc eax // вторая реальная инструкция
end;
Такой мусорный блок уже не снять на автомате скриптом, детектирующим отсутствие изменений в регистрах, т.к. каждая инструкция в реальности будет изменять их значения.
Если над таким блоком хорошо подшаманить и раздуть до большого размера, то определить начало и конец мусора будет достаточно проблематично. Тем более всегда есть в наличии стек, сохранив значение регистров на нем можно, в качестве мусора, хоть теорему Ферма доказывать до пока не надоест, после чего просто восстановить значения регистров и продолжить выполнение программы :)
4. Виртуальная машина — из-за незащищенных хэндлеров (обработчиков инструкций VM) написать ее аналог не составило больших времязатрат. По хорошему в боевом приложении хендлеры VM должны быть качественно обфусцированны, для затруднения понимания логики работы VM. Понятно, что для keygenme этот этап излишен, но не стоит забывать о такой тонкости.
5. Логика работы P-Code — не смотря на наличие явно мусорных инструкций, основной алгоритм получения данных из буфера с логином/SN оказался единым на всех этапах, что дало возможность достаточно быстро разобрать всю логику на основе шаблона. Если бы было введено несколько вариантов получения данных (а лучше свой уникальный вариант для получения каждого символа) это бы сильно затруднило анализ.
6. Анализ VM усложнился бы в разы, если бы внутри P-Code сидела еще одна виртуальная машина (допустим на базе того-же Brainfuck) которая бы и выполняла интерпретацию своего собственного P-Code.
Что в итоге:
Очень качественно выполненный keygenme, великолепно показывающий работу с виртуальной машиной. Единственный нюанс, на который он не дает ответа — каким образом был получен P-Code для виртуальной машины, который она исполняет :)
Этот этап индивидуален для каждого разработчика, каждый применяет свои методы, впрочем в планах у меня есть статья по реализации алгоритма генерации пикода, правда для немного другого типа VM.
Со своей стороны я показал один из вариантов взлома таких VM, без этапа деобфускации асм листинга, используя в качестве инструментария граф исполнения VM.
Я думаю это сможет помочь вам при анализе собственных реализаций VM, на предмет их стойкости к подобному варианту взлома.
Ну а если вы еще не подошли к собственно реализации VM, по крайней мере теперь вы имеете минимальное представление о том, как она может работать.
Исходный код демопримеров к статье можно забрать по этой ссылке:
http://rouse.drkb.ru/blog/vm_analize.zip
Делайте выводы и удачи.