Airflow Workshop: сложные DAG’и без костылей
- среда, 13 декабря 2017 г. в 03:13:13

Привет, Хабр! Меня зовут Дина, и я занимаюсь разработкой игрового хранилища данных для решения задач аналитики в Mail.Ru Group. Наша команда для разработки batch-процессов обработки данных использует Apache Airflow (далее Airflow), об этом yuryemeliyanov писал в недавней статье. Airflow — это opensource-библиотека для разработки ETL/ELT-процессов. Отдельные задачи объединяются в периодически выполняемые цепочки задач — даги (DAG — Directed Acyclic Graph).
Как правило, 80 % проекта на Airflow — это стандартные DAG’и. В моей статье речь пойдёт об оставшихся 20 %, которые требуют сложных ветвлений, коммуникации между задачами — словом, о DAG’ах, нуждающихся в нетривиальных алгоритмах.
Представьте, что перед нами стоит задача ежедневно забирать данные с нескольких шардов. Мы параллельно записываем их в стейджинговую область, а потом строим на них целевую таблицу в хранилище. Если в процессе работы по какой-то причине произошла ошибка — например, часть шардов оказалась недоступна, — DAG будет выглядеть так:
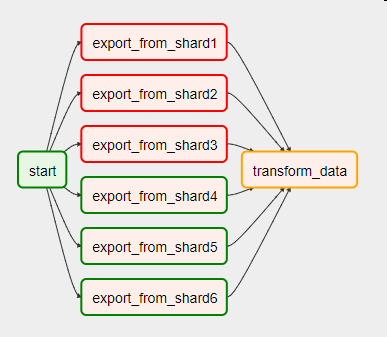
Для того чтобы перейти к выполнению следующей задачи, нужно обработать ошибки в предшествующих. За это отвечает один из параметров оператора — trigger_rule. Его значение по умолчанию — all_success — говорит о том, что задача запустится тогда и только тогда, когда успешно завершены все предыдущие.
Также trigger_rule может принимать следующие значения:
Для реализации логики if-then-else можно использовать оператор ветвления BranchPythonOperator. Вызываемая функция должна реализовывать алгоритм выбора задачи, который запустится следующим. Можно ничего не возвращать, тогда все последующие задачи будут помечены как не нуждающиеся в исполнении.
В нашем примере выяснилось, что недоступность шардов связана с периодическим отключением игровых серверов, соответственно, при их отключении никаких данных за нужный нам период мы не теряем. Правда, и витрины нужно строить с учётом количества включённых серверов.
Вот как выглядит этот же DAG со связкой из двух задач с параметром trigger_rule, принимающим значения one_success (хотя бы одна из предыдущих задач успешна) и all_done (все предыдущие задачи завершились), и оператором ветвления select_next_task вместо единого PythonOperator’а.
# Запускается, когда все предыдущие задачи завершены
all_done = DummyOperator(task_id='all_done', trigger_rule='all_done', dag=dag)
# Запускается, как только любая из предыдущих задач успешно отработал
one_success = DummyOperator(task_id='one_success', trigger_rule='one_success', dag=dag)
# Возвращает название одной из трёх последующих задач
def select_next_task():
success_shard_count = get_success_shard_count()
if success_shard_count == 0:
return 'no_data_action'
elif success_shard_count == 6:
return 'all_shards_action'
else:
return 'several_shards_action'
select_next_task = BranchPythonOperator(task_id='select_next_task',
python_callable=select_next_task,
dag=dag)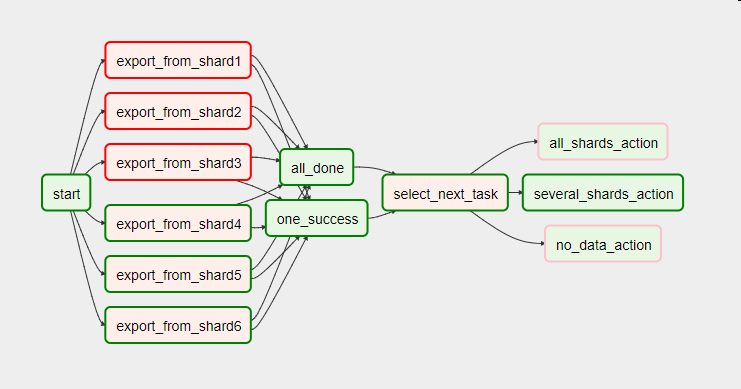
Документация по параметру оператора trigger_rule
Документация по оператору BranchPythonOperator
Операторы Airflow также поддерживают рендеринг передаваемых параметров с помощью Jinja. Это мощный шаблонизатор, подробно о нём можно почитать в документации, я же расскажу только о тех его аспектах, которые мы применяем в работе с Airflow.
Шаблонизатор обрабатывает:
provide_context=True):def index_finder(conn_id, task, **kwargs):
sql = "SELECT MAX(idtransaction) FROM {{ params.billing }}"
max_id_sql = task.render_template("", sql, kwargs)
...Вот как мы применяем Jinja в Airflow:
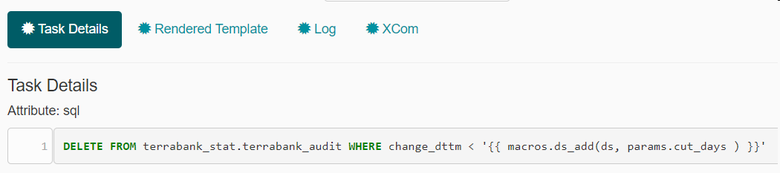
Приведу несколько примеров рендеринга параметров в интерфейсе Airflow. В первом мы удаляем записи старше количества дней, передаваемого параметром cut_days. Так выглядит sql c использованием шаблонов jinja в Airflow:
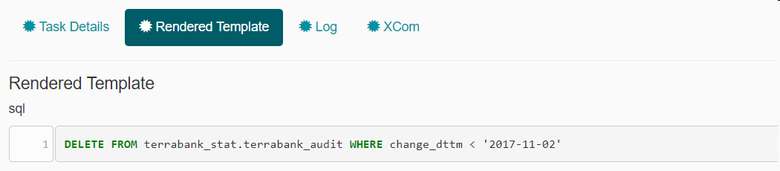
В обработанном sql вместо выражения уже подставляется конкретная дата:
Второй пример посложнее. В нём используется преобразование даты в unixtime для упрощения фильтрации данных на источнике. Конструкция "{:.0f}" используется, чтобы избавиться от вывода знаков после запятой:
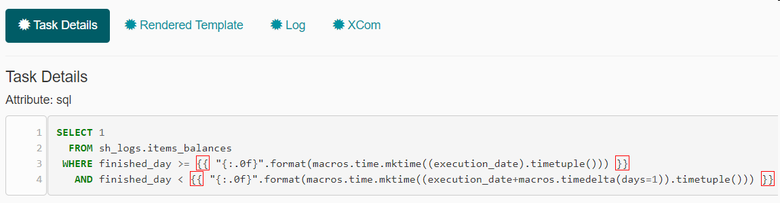
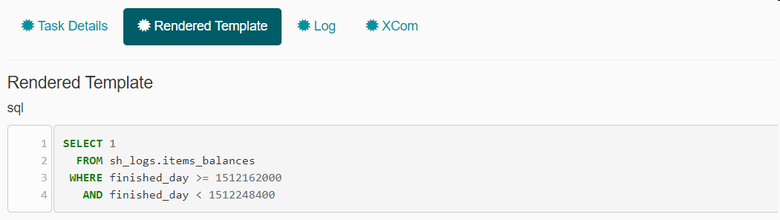
Jinja заменяет выражения между двойными фигурными скобками на unixtime, соответствующий дате исполнения DAG’а и следующей за ней дате:
Ну и в последнем примере мы используем функцию truncshift, переданную в виде параметра:
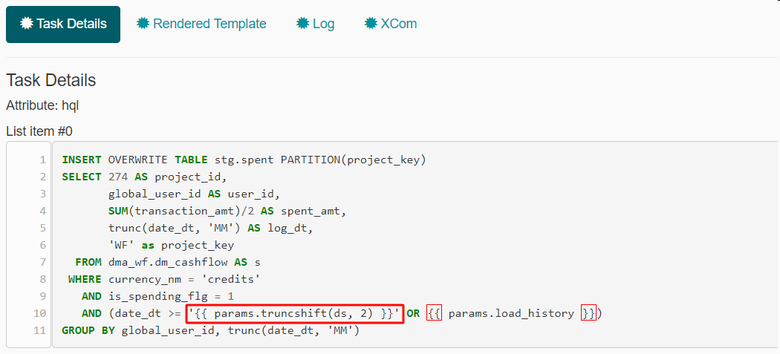
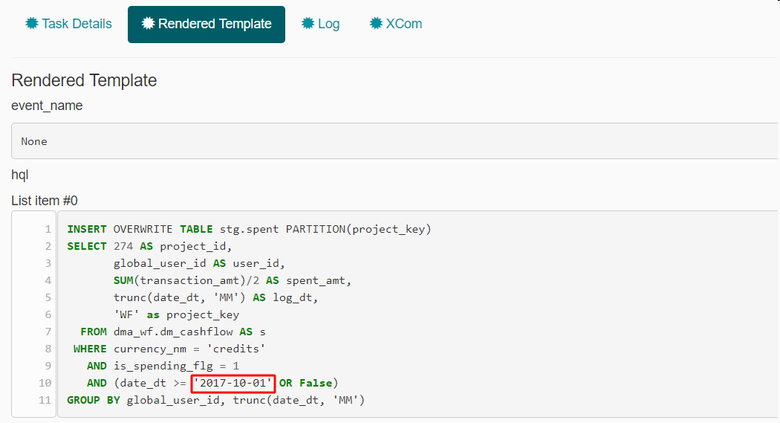
Вместо этого выражения шаблонизатор подставляет результат работы функции:
Документация по шаблонизатору jinja
В одном из наших источников интересная система хранения логов. Каждые пять дней источник создаёт новую таблицу такого вида: squads_02122017. В её названии присутствует дата, поэтому возник вопрос, как именно её высчитывать. Какое-то время мы использовали таблицы с названиями из всех пяти дней. Четыре запроса падали, но trigger_rule=’one_success’ спасал нас (как раз тот случай, когда выполнение всех пяти задач необязательно).
Спустя какое-то время мы стали использовать вместо trigger_rule встроенную в Airflow технологию для обмена сообщениями между задачами в одном DAG’е — XCom (сокращение от cross-communication). XCom’ы определяются парой ключ-значение и названием задачи, из которой его отправили.

XCom создаётся в PythonOperator’е на основании возвращаемого им значения. Можно создать XCom вручную с помощью функции xcom_push. После выполнения задачи значение сохраняется в контексте, и любая последующая задача может принять XCom функцией xcom_pull в другом PythonOperator’е или из шаблона jinja внутри любой предобработанной строки.
Вот как выглядит получение названия таблицы сейчас:
def get_table_from_mysql(**kwargs):
"""
Выбирает существующую из пяти таблиц и пушит значение
"""
hook = MySqlHook(conn_name)
cursor = hook.get_conn().cursor()
cursor.execute(kwargs['templates_dict']['sql'])
table_name = cursor.fetchall()
# Посылаем XCom с названием ‘table_name’
kwargs['ti'].xcom_push(key='table_name', value=table_name[0][1])
# Второй вариант отправления XCom’а:
# return table_name[0][1]
# Можно получить по названию задачи-отправителя без ключа
# Запрос, вынимающий из метаданных PostgreSQL название нужной таблицы
select_table_from_mysql_sql = '''
SELECT table_name
FROM information_schema.TABLES
WHERE table_schema = 'jungle_logs'
AND table_name IN
('squads_{{ macros.ds_format(ds, "%Y-%m-%d", "%d%m%Y") }}',
'squads_{{ macros.ds_format( macros.ds_add(ds, -1), "%Y-%m-%d", "%d%m%Y") }}',
'squads_{{ macros.ds_format( macros.ds_add(ds, -2), "%Y-%m-%d", "%d%m%Y") }}',
'squads_{{ macros.ds_format( macros.ds_add(ds, -3), "%Y-%m-%d", "%d%m%Y") }}',
'squads_{{ macros.ds_format( macros.ds_add(ds, -4), "%Y-%m-%d", "%d%m%Y") }}')
'''
select_table_from_mysql = PythonOperator(
task_id='select_table_from_mysql',
python_callable=get_table_from_mysql,
provide_context=True,
templates_dict={'sql': select_table_from_mysql_sql},
dag=dag
)
# Получаем XCom из задачи 'select_table_from_mysql' по ключу 'table_name'
sensor_jh_squad_sql = '''
SELECT 1
FROM jungle_logs.{{ task_instance.xcom_pull(task_ids='select_table_from_mysql',
key='table_name') }}
LIMIT 1
'''Ещё один пример использования технологии XCom — рассылка email-уведомлений с текстом, отправленным из PythonOperator’а:
kwargs['ti'].xcom_push(key='mail_body', value=mail_body)А вот получение текста письма внутри оператора EmailOperator:
email_notification_lost_keys = EmailOperator(
task_id='email_notification_lost_keys',
to=alert_mails,
subject='[airflow] Lost keys',
html_content='''{{ task_instance.xcom_pull(task_ids='find_lost_keys',
key='mail_body') }}''',
dag=dag
)Документация по технологии XCom
Я рассказала о способах ветвления, коммуникации между задачами и шаблонах подстановки. С помощью встроенных механизмов Airflow можно решать самые разные задачи, не отходя от общей концепции реализации DAG’ов. На этом интересные нюансы Airflow не заканчиваются. У нас с коллегами есть идеи для следующих статей на эту тему. Если вас заинтересовал этот инструмент, пишите, о чём именно вам хотелось бы прочитать в следующий раз.