https://habr.com/ru/company/otus/blog/502568/- Блог компании OTUS. Онлайн-образование
- Python
- Программирование
- Big Data
Статья переведена в преддверии запуска курса «Разработчик Python».
Сторителлинг – один из важнейших навыков для специалистов, которые занимаются анализом данных. Чтобы доносить идеи и делать это убедительно, нужно простраивать эффективную коммуникацию. В этой статье мы познакомимся с 5 методами визуализации, которые выходят за рамки классического понимания, и могут сделать вашу Data Story более эстетичной и красивой. Работать мы будем с графической библиотекой
Plotly на Python (она также доступна на R), которая позволяет создавать анимированные и интерактивные диаграммы с минимальными усилиями.
Что хорошего в Plotly
Графики Plotly можно легко интегрировать в различные среды: они хорошо работают в jupyter notebooks, их можно встроить в веб-сайт, а еще они полностью интегрируемы с
Dash — отличным инструментом для создания панелей мониторинга и аналитических приложений.
Начнем
Если у вас еще не установлена plotly, сделать это можно с помощью следующей команды:
pip install plotly
Отлично, теперь можно продолжать!
1. Анимации
Наша работа часто связана с временными данными, например, когда мы рассматриваем эволюцию той или иной метрики. Анимация в plotly – это классный инструмент, который помогает отразить, как данные изменяются со временем, с помощью всего одной строчки кода.

import plotly.express as px
from vega_datasets import data
df = data.disasters()
df = df[df.Year > 1990]
fig = px.bar(df,
y="Entity",
x="Deaths",
animation_frame="Year",
orientation='h',
range_x=[0, df.Deaths.max()],
color="Entity")
# improve aesthetics (size, grids etc.)
fig.update_layout(width=1000,
height=800,
xaxis_showgrid=False,
yaxis_showgrid=False,
paper_bgcolor='rgba(0,0,0,0)',
plot_bgcolor='rgba(0,0,0,0)',
title_text='Evolution of Natural Disasters',
showlegend=False)
fig.update_xaxes(title_text='Number of Deaths')
fig.update_yaxes(title_text='')
fig.show()
Почти любой график можно анимировать, если у вас есть переменная, которая поможет вам провести фильтрацию по времени. Пример анимации диаграммы рассеяния:
import plotly.express as px
df = px.data.gapminder()
fig = px.scatter(
df,
x="gdpPercap",
y="lifeExp",
animation_frame="year",
size="pop",
color="continent",
hover_name="country",
log_x=True,
size_max=55,
range_x=[100, 100000],
range_y=[25, 90],
# color_continuous_scale=px.colors.sequential.Emrld
)
fig.update_layout(width=1000,
height=800,
xaxis_showgrid=False,
yaxis_showgrid=False,
paper_bgcolor='rgba(0,0,0,0)',
plot_bgcolor='rgba(0,0,0,0)')
2. Диаграммы Sunburst
Диаграммы Sunburst – это отличный способ визуализации операции
group by. Если вы хотите разбить имеющийся объем данных на одну или несколько категориальных переменных, воспользуйтесь sunburst-диаграммой.
Допустим, нам нужно получить распределение чаевых по полу и времени суток. Значит, мы можем воспользоваться оператором
group by дважды и с легкостью визуализировать полученные данные, чтобы не лицезреть обычный табличный вывод.
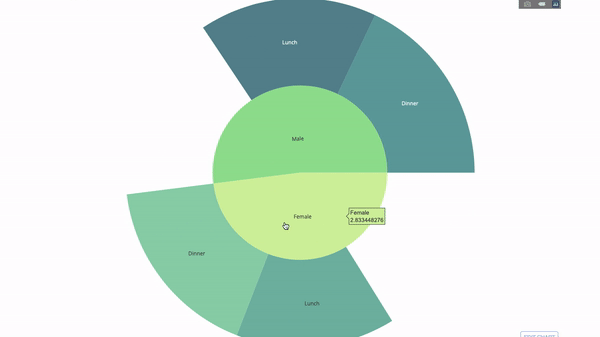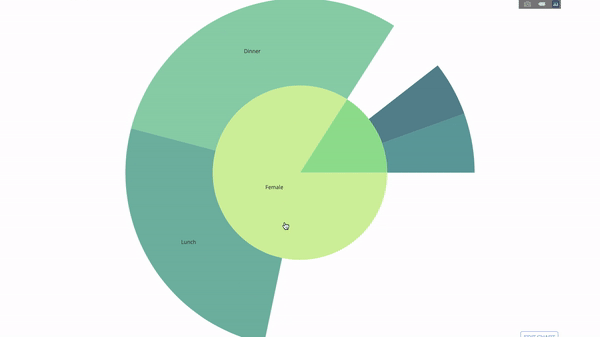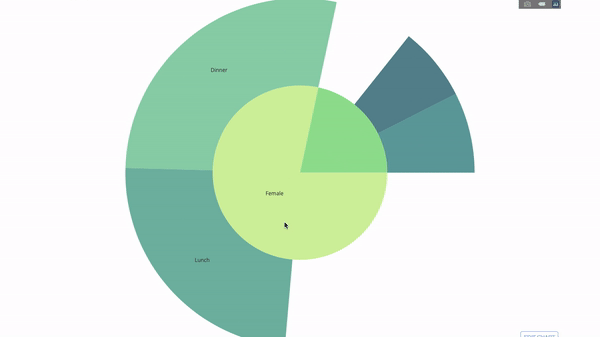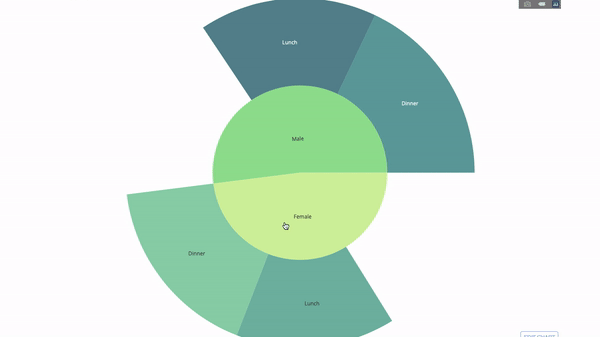
Диаграмма получается интерактивной, вы можете кликать на категории и рассматривать каждую категорию по отдельности. Все, что вам нужно сделать, это определиться с этими категориями, продумать иерархию между ними (аргумент
parents в коде) и присвоить соответствующие значения, которые в нашем случае окажутся выходными данными операторов
group by.
import plotly.graph_objects as go
import plotly.express as px
import numpy as np
import pandas as pd
df = px.data.tips()
fig = go.Figure(go.Sunburst(
labels=["Female", "Male", "Dinner", "Lunch", 'Dinner ', 'Lunch '],
parents=["", "", "Female", "Female", 'Male', 'Male'],
values=np.append(
df.groupby('sex').tip.mean().values,
df.groupby(['sex', 'time']).tip.mean().values),
marker=dict(colors=px.colors.sequential.Emrld)),
layout=go.Layout(paper_bgcolor='rgba(0,0,0,0)',
plot_bgcolor='rgba(0,0,0,0)'))
fig.update_layout(margin=dict(t=0, l=0, r=0, b=0),
title_text='Tipping Habbits Per Gender, Time and Day')
fig.show()
Теперь давайте добавим еще один уровень иерархии:

Для этого мы добавим результат выполнения еще одного
group by, из которого мы получим еще три категории.
import plotly.graph_objects as go
import plotly.express as px
import pandas as pd
import numpy as np
df = px.data.tips()
fig = go.Figure(go.Sunburst(labels=[
"Female", "Male", "Dinner", "Lunch", 'Dinner ', 'Lunch ', 'Fri', 'Sat',
'Sun', 'Thu', 'Fri ', 'Thu ', 'Fri ', 'Sat ', 'Sun ', 'Fri ', 'Thu '
],
parents=[
"", "", "Female", "Female", 'Male', 'Male',
'Dinner', 'Dinner', 'Dinner', 'Dinner',
'Lunch', 'Lunch', 'Dinner ', 'Dinner ',
'Dinner ', 'Lunch ', 'Lunch '
],
values=np.append(
np.append(
df.groupby('sex').tip.mean().values,
df.groupby(['sex',
'time']).tip.mean().values,
),
df.groupby(['sex', 'time',
'day']).tip.mean().values),
marker=dict(colors=px.colors.sequential.Emrld)),
layout=go.Layout(paper_bgcolor='rgba(0,0,0,0)',
plot_bgcolor='rgba(0,0,0,0)'))
fig.update_layout(margin=dict(t=0, l=0, r=0, b=0),
title_text='Tipping Habbits Per Gender, Time and Day')
fig.show()
3. Параллельные категории
Еще один хороший способ визуализировать отношения между категориями – эта диаграмма параллельных категорий. Вы можете перетаскивать, выделять и получать значения на ходу, что отлично подходит для презентаций.

import plotly.express as px
from vega_datasets import data
import pandas as pd
df = data.movies()
df = df.dropna()
df['Genre_id'] = df.Major_Genre.factorize()[0]
fig = px.parallel_categories(
df,
dimensions=['MPAA_Rating', 'Creative_Type', 'Major_Genre'],
color="Genre_id",
color_continuous_scale=px.colors.sequential.Emrld,
)
fig.show()
4. Параллельные координаты
Диаграмма с параллельными координатами – это развернутая версия приведенного выше графика. Здесь каждая часть графика отражает одно наблюдение. Это хороший инструмент выявления выбросов (одиночных потоков, изолированных от остальных данных), кластеров, трендов и избыточных данных (например, если у двух переменных одинаковые значения для всех наблюдений, они будут лежать на горизонтальной линии, что укажет на наличие избыточности).
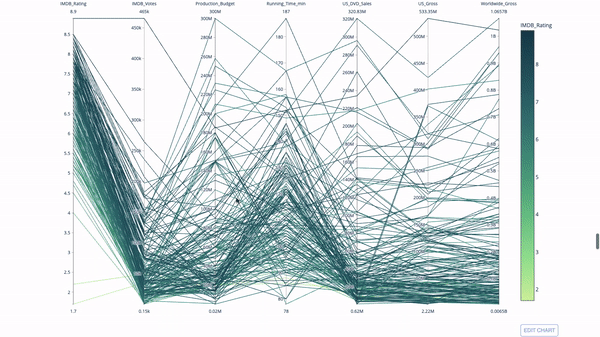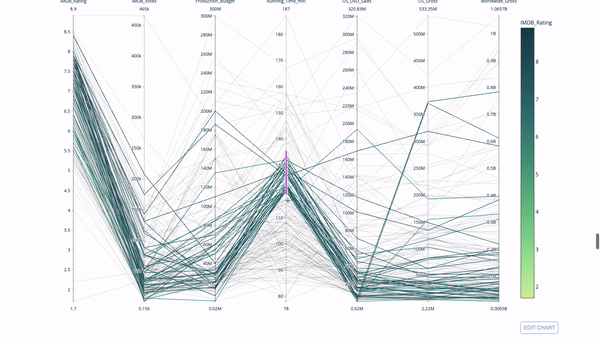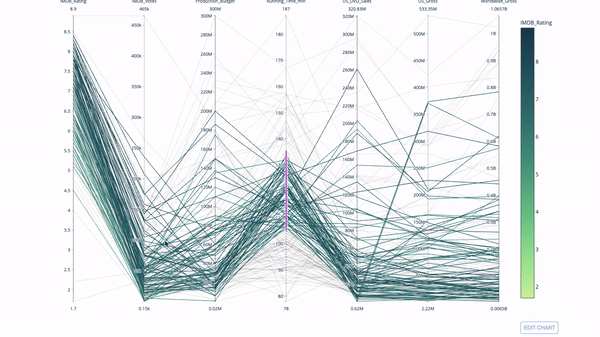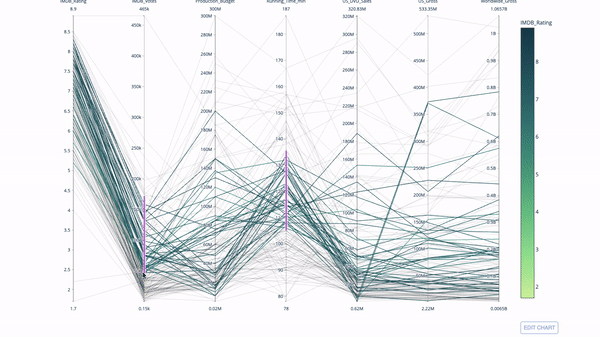
import plotly.express as px
from vega_datasets import data
import pandas as pd
df = data.movies()
df = df.dropna()
df['Genre_id'] = df.Major_Genre.factorize()[0]
fig = px.parallel_coordinates(
df,
dimensions=[
'IMDB_Rating', 'IMDB_Votes', 'Production_Budget', 'Running_Time_min',
'US_Gross', 'Worldwide_Gross', 'US_DVD_Sales'
],
color='IMDB_Rating',
color_continuous_scale=px.colors.sequential.Emrld)
fig.show()
5. Диаграммы-датчики и индикаторы

Диаграммы-датчики нужны для эстетики. Они являются хорошим способом сообщить о показателях успеха или показателях эффективности и связать их с вашей целью.

Индикаторы будут весьма полезны в контексте бизнеса и консалтинга. Они дополняют визуальные эффекты текстом, который привлекает внимание аудитории и транслирует аудитории показатели роста.
import plotly.graph_objects as go
fig = go.Figure(go.Indicator(
domain = {'x': [0, 1], 'y': [0, 1]},
value = 4.3,
mode = "gauge+number+delta",
title = {'text': "Success Metric"},
delta = {'reference': 3.9},
gauge = {'bar': {'color': "lightgreen"},
'axis': {'range': [None, 5]},
'steps' : [
{'range': [0, 2.5], 'color': "lightgray"},
{'range': [2.5, 4], 'color': "gray"}],
}))
fig.show()
import plotly.graph_objects as go
fig = go.Figure(go.Indicator(
title = {'text': "Success Metric"},
mode = "number+delta",
value = 300,
delta = {'reference': 160}))
fig.show()
fig = go.Figure(go.Indicator(
title = {'text': "Success Metric"},
mode = "delta",
value = 40,
delta = {'reference': 160}))
fig.show()
Вот и все!
Надеюсь, вы нашли для себя что-то полезное. Оставайтесь дома, будьте в безопасности, работайте продуктивно.
Узнать подробнее о курсе.